机器学习概念
有监督学习
给定数据集 D 并给定数据标签 y;以 ImageNet 数据集为例,给定一副图片并标注图片所属类别(猫、狗…)。有监督学习在机器学习中占比很大,常见的有:KNN、线性回归、逻辑回归、决策树、SVM。虽然有监督学习很大占比,但其数据标签的获取会产生很大的占比(数以百万计的数标注),现在已经有很大规模数据标注服务。
无监督学习
对比有监督学习,无监督学习中数据集没有给定标签。无监督学习常用于聚类问题,例如将新闻分类。无监督学习算法常见的是 k-means。
泛化能力
泛化能力是指模型在未知数据上预测准确度,也是评估模型好坏的重要标准。对于机器学习,模型在测试数据上的性能。泛化误差由三个不同的误差决定:偏差、方差、噪声。
欠拟合
模型预测结果和实际相差甚大,拟合能力弱模型差,具体表现就是偏差大。
偏差:度量模型预测值和真实值偏离程度,刻画模型的拟合能力
针对欠拟合,可以采取以下措施:
- 更好的特征训练学习算法(特征工程)
- 选择一个更强大的模型,带有更多参数
- 减小对模型的限制(减小正则化超参)
过拟合
模型在训练集表现好,但在测试集在表现差。 解决方案如下:
- 简化模型 - 选择参数少的模型(将多项式模型换成线性模型)
- 优化特征 - 减少特征
- 限制模型 - 增加正则化去惩罚模型
- 收集更多的数据
- 减小数据噪声 - 修改数据错误和去除异常值
方差
方差:同样大小数据集变动所导致的学习能力变化。刻画数据扰动所造成的影响
从模型的角度来说,对训练数据的微小变化较为敏感,容易有更高的方差,因此导致欠拟合。
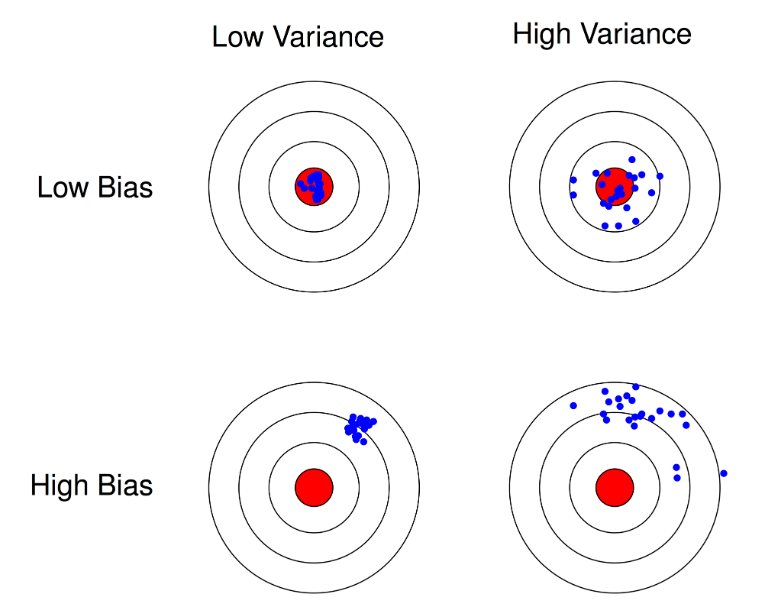
上图利用打靶图来展示偏差、方差之间的差异。
- 左上角图是模型能得到的最好结果,低偏差和低方差表示模型拟合能力强且稳定;
- 右上角图表示模型拟合能力较好但模型不稳定对数据敏感;
- 左下角虽然模型稳定但拟合能力差;
- 右下角是最差的情况,拟合能力弱且什么不稳定,模型基本无效
噪声
噪声:模型所能达到的期望泛化误差的下界,刻画了学习问题本身的难度
so,机器学习中数据是很重要的,好的数据是得到一个较优模型的基础。
交叉验证
交叉验证一般用于数据集较少的情况,弥补数据集少而容易引起过拟合。