背景
在讨论 Word2Vec 之前,必然是要说到 Embedding。刚开始接触 Embedding 时,很难描述它究竟是干什么的。我们不妨这么来理解:在机器学习中,我们需要对现实的问题建模来实现问题的求解;建模的输入是数值,而现实中遇到的都是符号(word、movie、food…);那么在解决问题时,需要将符号转换成数值 - 这个过程叫 Embedding 即符号用 Vector 来表示。在 Embedding 时,必然存在 embedding matrix 供转换使用,它是机器学习想要得到的结果。本文要讨论的 Word Embedding 是 Embedding 在 Word 领域的实现。
Word2Vec
Word2Vec 是实现 Word Embedding 的一种工具。在 Word2Vec 之前,我们都是用 one-hot-encoder 来对每个词编码。但one-hot-encoder 是假设每个词相互独立,这显然不符号词的现实意思(词与词之间有关联的,同义、反义…),而且one-hot-encoder 编码维度会很大(假设10万个词就是10万维度),在机器学习过程中导致维度爆炸很难进行训练。很显然 Word2Vec 解决了上述问题,优点显而易见
- 降维:将
one-hot-encoder降低到vector要表示的维度,一般是 50-300 - 词义:
Word2Vec可以变现不同词之间的关系 - 根据词在向量空间的坐标得到词与词之间联系
Word2Vec 是如何做到的呢?一个词的意思是用其他词来描述 - Word2Vec 是将词用词的上下文来描述。简单举例:
- 对于一句话:『她们 夸 吴彦祖 帅 到 没朋友』,『吴彦祖』这个词,在本句的上下文就是『她们』、『夸』、『帅』、『没朋友』这些词
- 现有另一句话:『她们 夸 我 帅 到 没朋友』,那么不难发现『我』这个词,和『吴彦祖』这个词,在本语料中上下文相同
- 可以得出『我』和『吴彦祖』两个词意思相同
语料可以简单认为是很多句子的集合,本例中就是例子中的两句话。上面的语料训练出『我』和『吴彦祖』是同义词,也许换个语料结果会不同,显然一个丰富的语料很重要。
Word2Vec 基于词和上下文的关系可以派生出两个模型
Skip-gram
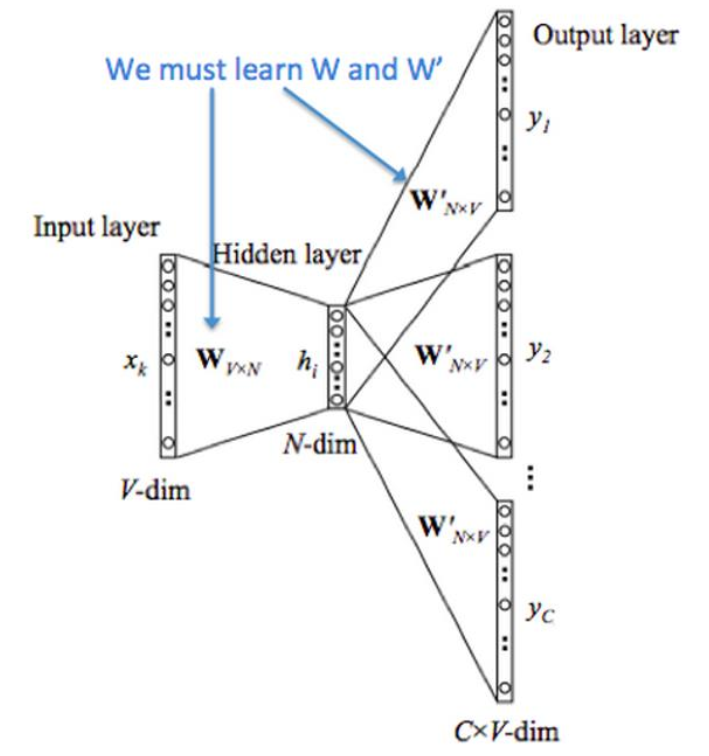
如果用一个词语作为输入,来预测它周围的上下文,那这个模型叫做 Skip-gram 模型,即 P(context|word)
CBOW
如果是拿一个词语的上下文作为输入,来预测这个词语本身,则是 CBOW 模型,即P(word|context)
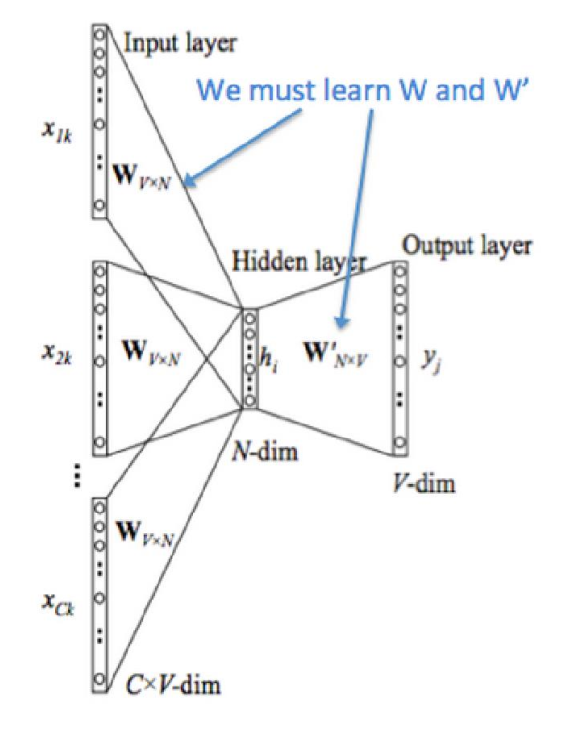
Model
在大致了解 Word2Vec是什么东东后,以 Skip-gram 为例看看它的模型。Skip-gram 模型 显然是个浅层神经网络,只有一个隐藏层,需要求解的也只是两个权重:$W {V*N}$、$W ^{‘}{NV}$ 。模型训练结束后,$W _{VN}$ 就是我们需要的 embedding matrix 。举个例子来理解,现在有两个词:·我·、’第’经 one-hot-encoder 编码向量表示为[0,1,0,0,0]和[0,0,0,0,1],embedding matrix 如下
[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]]
那么 Word2Vec 的转换公式为 onehot * embedding matrix(实际运算不用点积,太耗时了,直接查表就行),·我· = [3,4,5],’第’ = [12, 13, 14]。本例实现将5维的onehot 转换成3维word embedding。
上面描述的是模型训练后,如何应用的问题。接下来看看模型是如何训练的,在此之前需要一些神经网络的知识自己去弥补。
Input layer:维度与onehot相同Hidden layer:神经元个数和最后得到的Word Embedding相同,这就是为什么 $W _{V*N}$ =embedding matrixoutput layer:维度与onehot相同
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数(embedding matrix),例如隐层的权重矩阵。
tf train Word2Vec
待续
hierarchical softmax or negative sampling