HDFS
HDFS 是分布式系统 Hadoop 的文件系统。
NameNode
edits:编辑日志,客户端对目录和文件的写操作首先被写到 edit 日志中,如:创建文件、删除文件等。fsimage:文件系统元数据检查点镜像文件,保存了文件系统中所有的目录和文件信息,如:一个目录下有那些子目录、子文件、文件名,文件副本数,文件由哪些块组成等。- 内存镜像信息 =
fsimage+edits - NameNode 定期将内存中新增的
edits和fsimage合并保存到磁盘
namenode的 fsimage 只维护 HDFS 的目录结构,不保存Block和DataNode的映射关系(这通过 DataNode 实时上报 NameNode 实现)。
DataNode
- 在集群启动时向 NameNode 提供存储的 Block 块列表信息
- 通过心跳定时向 NameNode 汇报运行状态和所有块信息
- 执行客户端读写请求
DataNode 并不会持久化存储所有块信息
Block 块信息
- 文件分成若干 Block 块存储,每块默认 128M,可自定义
- 若一个块的大小小于设定块的大小,则不会占用整个块的空间
- 默认情况每个
Block有三个副本
Client
- 文件切分成块:文件在上传到
HDFS之前由客户端切分 - 与
NameNode交换文件元数据信息 - 与
DataNode交互,读取或写入数据 - 管理
HDFS
高可用
HDFS 全靠 NameNode 来存储文件元数据,那如何保证 NameNode 一直能正常运行呢?实质是在 HDFS 中有两个NN(NameNode 以下简称 NN),当有一个发生故障后另一个 NN 实时顶替。下面从备份和切换两方面来讲解:
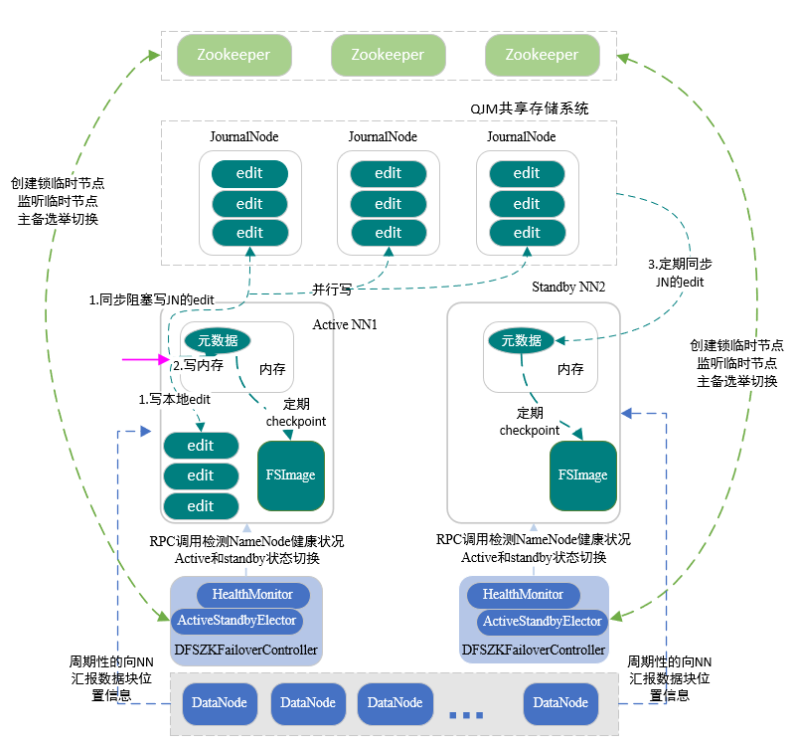
- 备份:保证两个 NN 元数据一致
1.1 ActivitNN 响应写请求,并请日志写到 edit ,同时将日志写到共享系统
1.2 ActivitNN 定期将内存的 fsimage 写到磁盘保存
1.3 StandbyNN 定期从共享系统同步 edit 到内存
1.4 StandbyNN 定期将内存的 fsimage 写到磁盘保存
- 切换:ActivitNN 发生故障,StandbyNN 切换为 ActivitNN
2.1 NN 在启动的时候都会启动 ActiveStandbyElector 进程
2.2 ActiveStandbyElector 进程会尝试在 Zookeeper 创建临时主节点
2.3 谁创建临时主节点,谁就是 ActivitNN ,剩下的就是 StandbyNN
2.4 StandbyNN 会监听临时主节点
2.5 ActivitNN 发生故障,Zookeeper 集群上对应的文件被删除
2.6 此时,StandbyNN 由于之前监听了就会被通知,然后自己切换成 ActivitNN
关于切换的部分涉及到
Zookeeper,不了解的话先自行去补(其实就是客户端利用Zookeeper实时监视服务器的存活)。
HDFS 写入文件流程
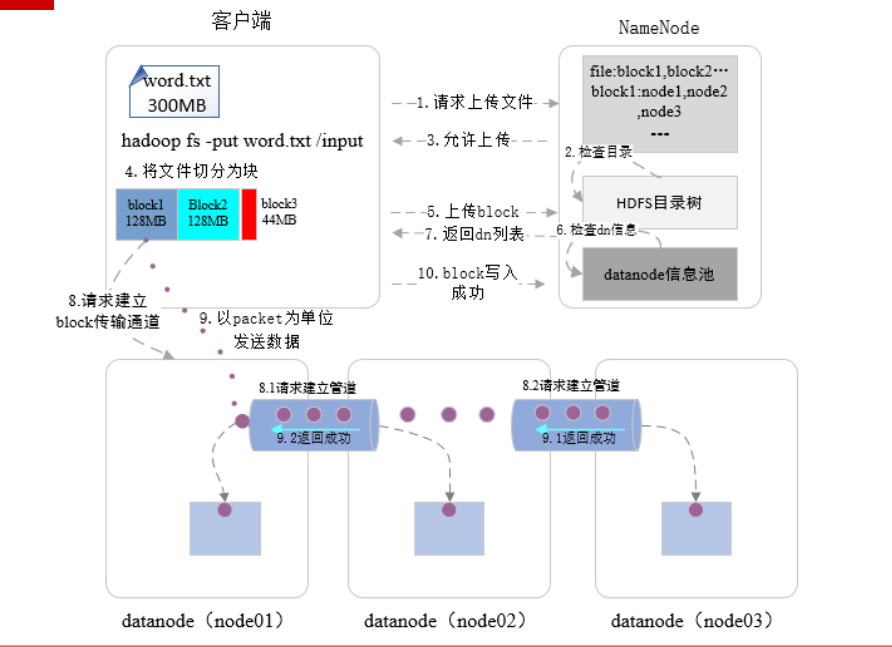
hadoop fs -put word.txt /input // word.txt 文件上传到 hdfs 的 /input
- 客户端发起写
/input文件请求 NameNode检查/input文件是否存在;若不存在则允许上传,否则报错- 客户端先将
word.txt文件写入到本地临时文件 - 当临时文件大小超过设定的
block大小或者文件写入结束,则向NameNode发起上传block操作NameNode根据集群datanode状态,返回此block副本要存储的datanode列表- 客户端根据返回 dn 列表与第一个
datanode0建立连接准备传输 - 客户端以 4kb 大小的
packet向datanode0传数据 - 当整个
block数据传输完毕后,由datanode0向datanode1建立管道传输数据 - 当
datanode0向datanode1传输完整个block后,由datanode1向datanode2建立管道传输数据 - 当
datanode1向datanode2传输完整个block后,datanode2向datanode1返回成功 - 接着
datanode1向datanode0返回成功 - 最后客户端给
NameNode发block写入成功消息 - 客户端继续将
word.txt文件写入到本地临时文件,重复第四步操作直至全部block上传结束
- 全部写入结束后,
NameNode才将/input在 HDFS 展示
dn 列表内容如下所示:

HDFS 读文件流程
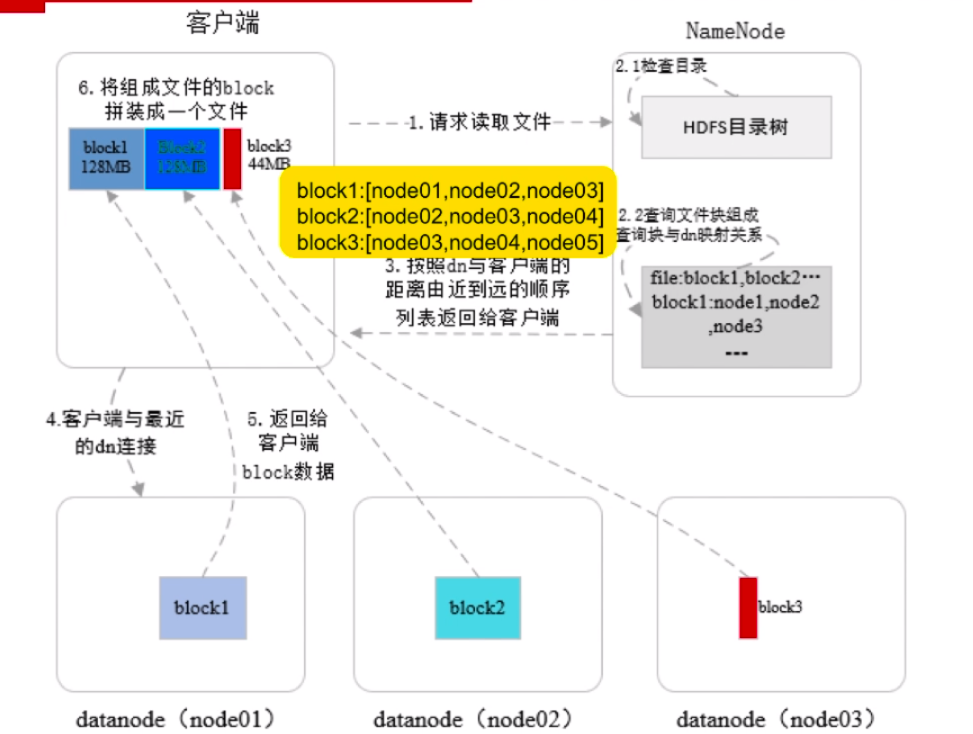
- 客户端请求
NameNode读取文件 NameNode检测 HDFS 是否存在文件,若存在则查询文件对应的 dn 列表NameNode返回的 dn 列表,按照客户端与datanode距离由近到远排序- 客户端接收到 dn 列表 后,按
block取出对应的datanode地址并建立连接进行读取 - 当客户端读取完一个
block后,关闭与当前的datanode连接,并进行下一个block读取 - 客户端读取完全部
block后,将其组装成文件
概括
HDFS为何不适合存储小文件。简而言之,NameNode内存存储文件元数据,存个小文件太浪费 -HDFS可以存储的文件个数取决于NameNode内存大小。
YARN
ResourceManager
整个集群只有一个 Master
- 处理客户端请求
- 启动/监控
ApplicationMaster - 监控
NodeManager - 资源分配和调度
NodeManager
每个节点只有一个,集群中会有多一个,一般与 DataNode 一一对应,在相同的机器上部署。
- 单个节点上的资源监控和管理
- 定时向
ResourceManager汇报本机的资源使用情况 - 处理来自
ResourceManager的请求,为作业的执行分配Container - 处理来自
Application Master的请求,启动和停止Container
Application Master
每个应用程序只有一个,负责应用程序的管理,资源申请和任务调度
- 与
ResourceManager协商为应用程序申请资源 - 与
NodeManager通信启动/停止任务 - 监控任务运行状态和失败处理
Container
任务运行环境的抽象,只有在任务分配的时候才会抽象出 Container。
- 任务运行资源(节点、内存、cpu)
- 任务启动命令
- 任务运行环境
容错
YARN 不同于 HDFS 只需保证 NameNode 即可;它有两个守护进程:ResourceManager 、NodeManager,还有任务处理进程 ApplicationMaster
- ResourceManager:类似 NameNode ,有备份可实时切换
- NodeManager:若在处理任务时发生故障后,
ResourceManager通知Application Master;Application Master决定如何处理 - ApplicationMaster:失败后,由
ResourceManager负责重启
任务调度
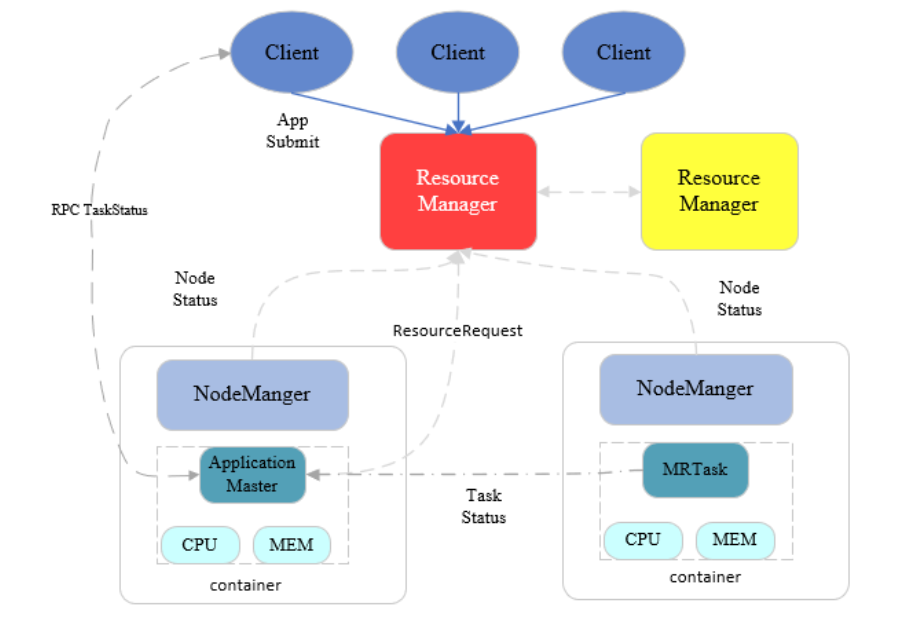
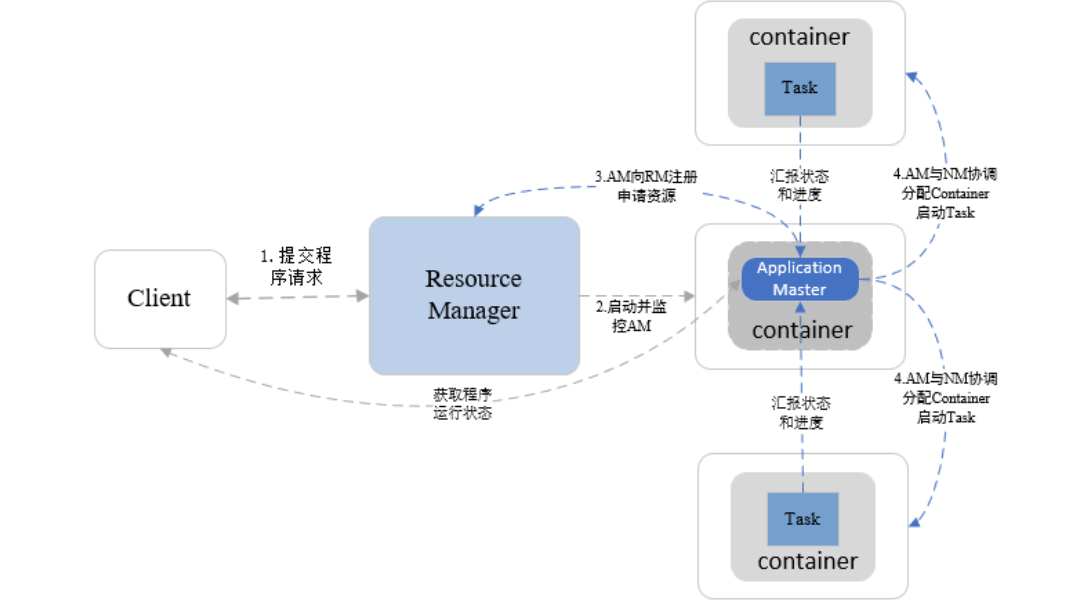
Client发起数据处理任务(写请求是 NN 处理)ResourceManager响应任务后,根据数据存放位置指定NodeManager处理任务(数据一般本机处理,不移动)NodeManager得到任务后,会启动container,其包含 cpu、mem资源;ResourceManager在其启动Application MasterApplication Master会向ResourceManager请求资源(其他 NodeManger,mapper任务并行处理)Application Master得到资源后向其他 NodeManger 发起任务- 其他 NodeManager 得到任务后也会启动
container,其包含 cpu、mem 和具体执行任务的MRTask Application Master此时会和Client交互任务状态Application Master会和MRTask交互任务进展MRTask任务结束后,Application Master通知其他 NodeManager 关闭其container
YARN程序运行流程
MapReduce
分布式批处理框架,适合海量数据的离线处理;MapReduce 程序分为 Map 阶段和 Reduce 阶段。
应用场景
擅长:
- 数据统计,比如网站的
PV、UV统计 - 搜索引擎索引
- 海量数据查找
- 复杂数据分析和算法实现
不擅长:
- 低延迟计算
- 流式计算
执行流程
步骤:分解 -> 合并求解
- 分 map
- 数据分块处理
- 负责问题分解成多个简单任务
- 合 reduce
- 把 map 输出结果作为输入合并求解
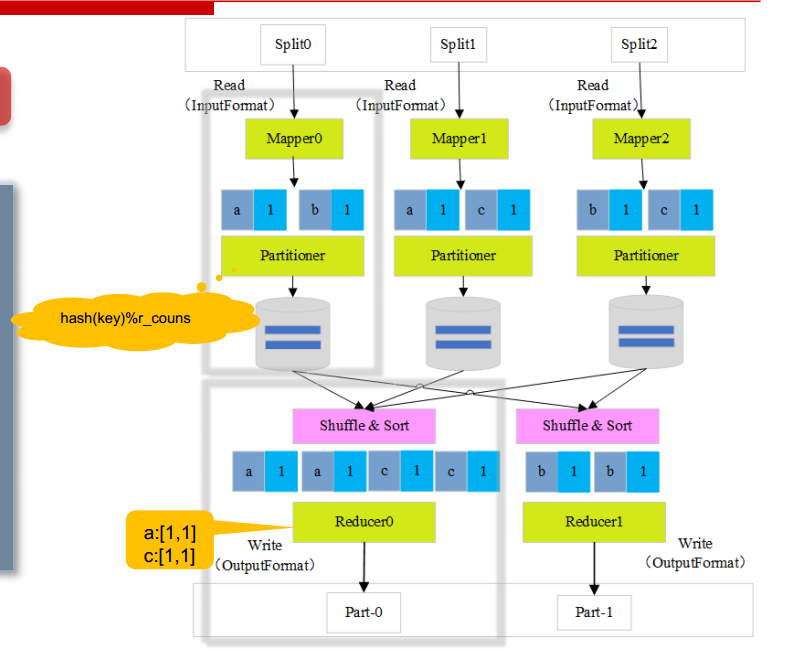
HDFS 数据是分块处理,将大文件切分成很多块;下图的 split0、split1、split2 就是文件的不同块。
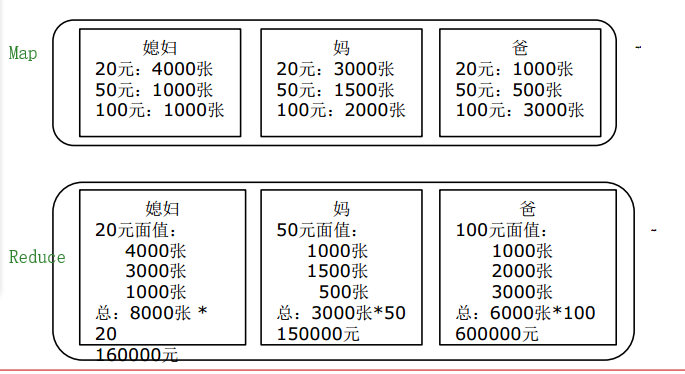
Mapper从 block 中读取数据Mapper统计 block 数据;对应上图就是媳妇、妈、爸统计出自己手中各个面值钞票数量Partitioner-分区将Mapper结果按key映射到某个Reducer处理- Shuffle&Sort 接收到多个
Mapper结果并按key排序; Reducer统计key值;对应上图就是得到媳妇、妈、爸手中单一面值的总金额
编程模型
- split
MapReduce中最小的计算单元- 默认与
Block一 一对应,但对应关系是任意的,可由用户控制 - 与
Mapper个数相同
- InputFormat
处理分片以及涉及到跨行问题:文件切分为 block 时,有可能把一行内容分到两个 block 中。
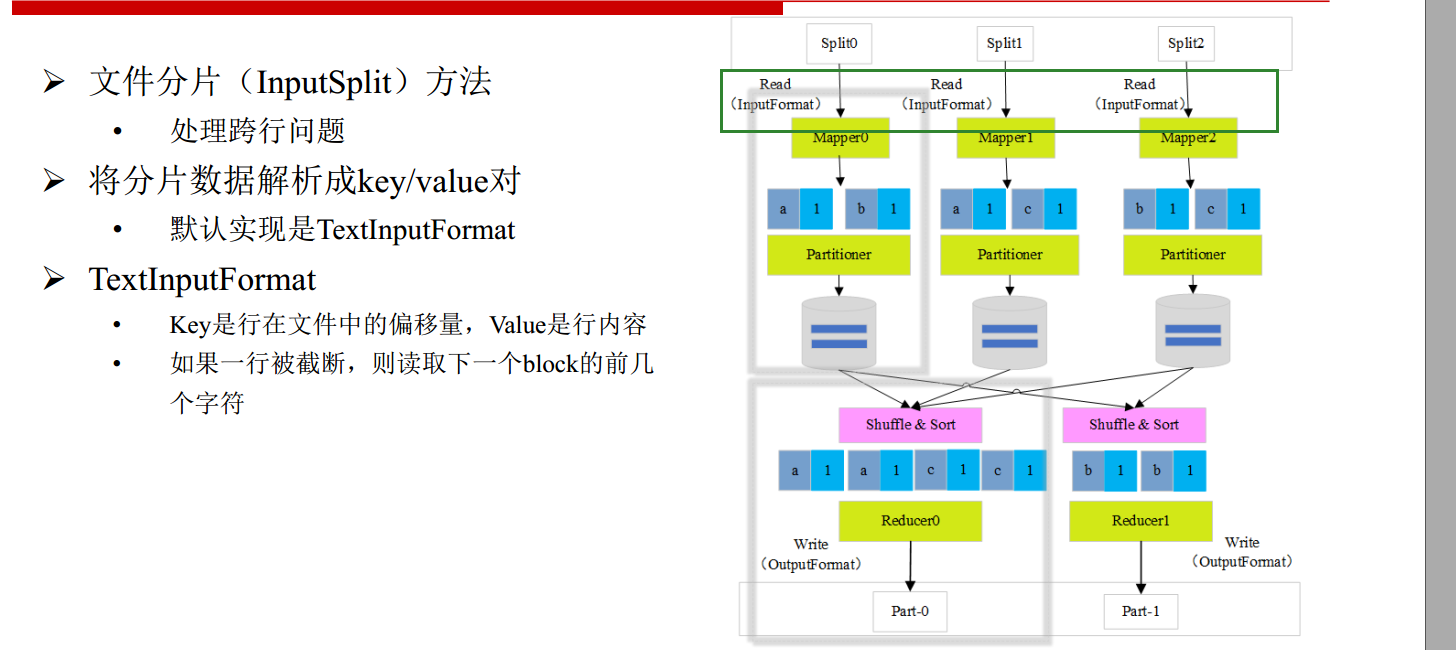
- Partitioner
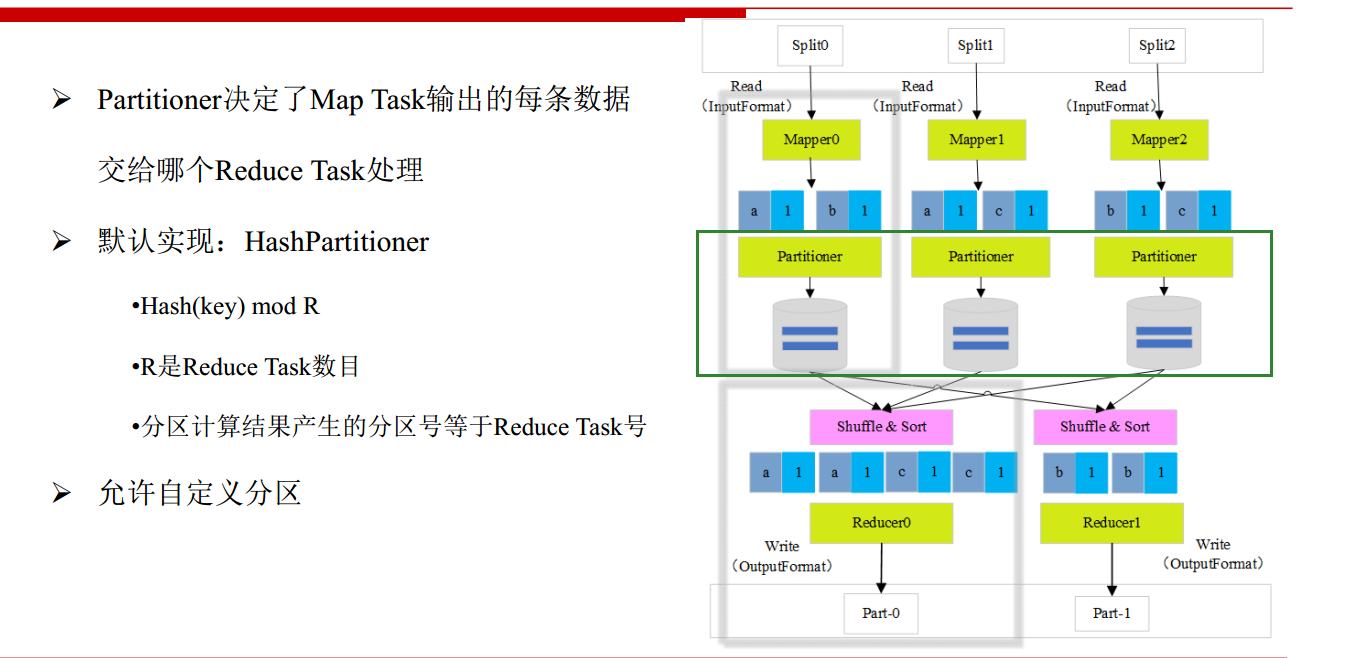
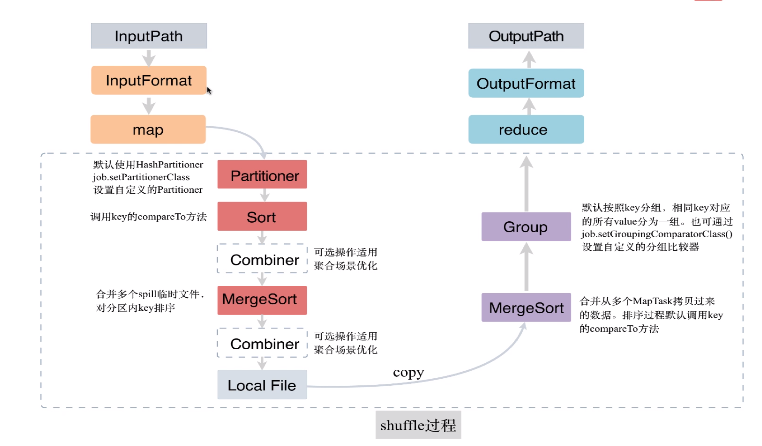
- Shuffle 过程
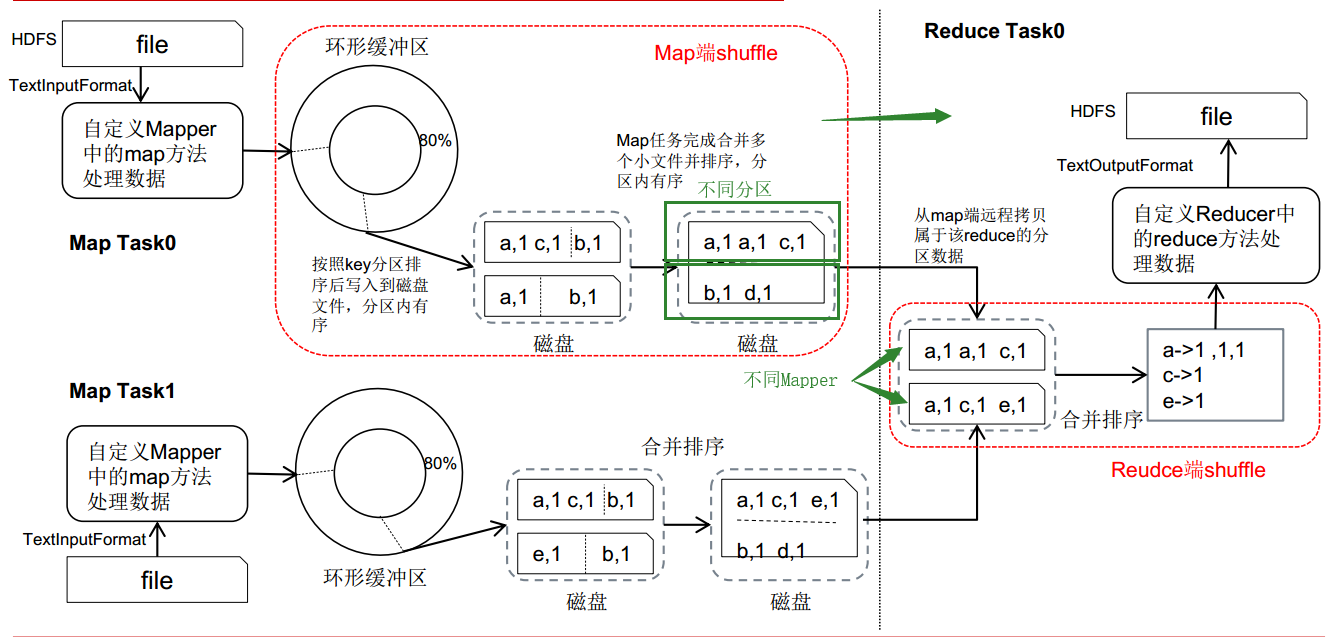
- 每个
Map Task把输出结果写到内存中的环形缓冲区 - 当内存缓冲区写入的数据量达到一定的阈值时,后台线程会把数据溢写到磁盘
- 根据
Partitioner,把数据写到不同的Partitioner - 对于每个
Partitioner内的数据进行排序
- 根据
- 随着
Map Task的不断运行,磁盘上的溢出文件越来越多- 将这些溢出文件合并
- 对于一个
Partitioner下的不同分片,使用归并排序,同一分区内数据有序
Reduce Task通过网络远程拷贝Map Task的结果文件中的属于它的分区数据- 合并所有已拷贝过来的数据文件
- 采用归并排序算法,对文件数据内容整理排序,将相同
key的数据分为一组,不同key之间有序 - 最终生成一个
key对应一组值的数据集,一个key对应的数据会调用一次reduce方法
- Combiner 优化
- 必须设置,
MapReduce才会使用。
- 必须设置,
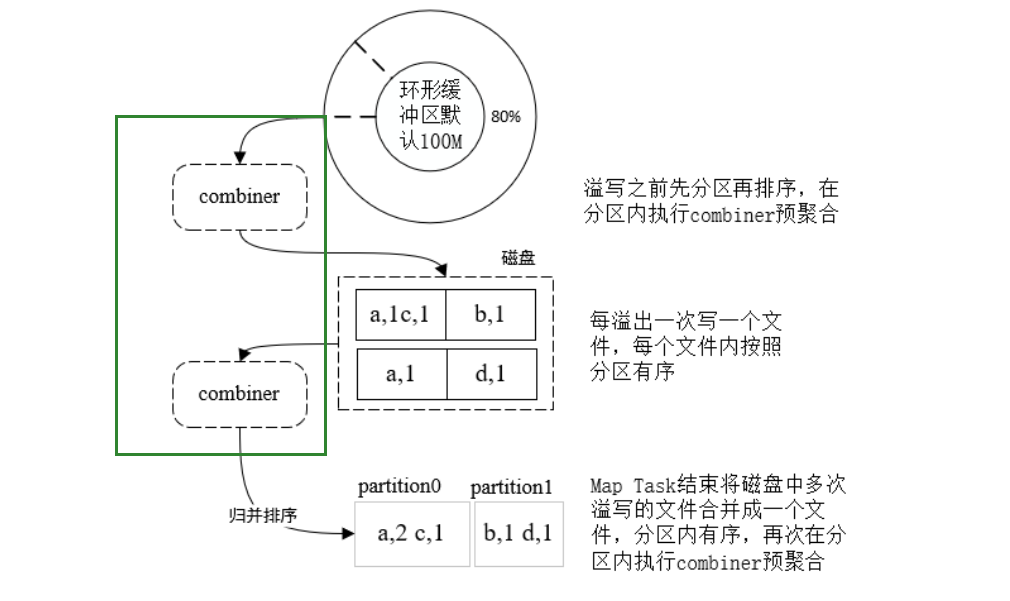

数据本地性
数据处理和数据存储在同一节点;减少网络传输的损耗。

推测执行

Hadoop 服务脚本

问题集
timeout
- xxx millis timeout while waiting for channel to be ready for write mapreduce 写文件操作太长导致超时,在
hdfs-site.xml增加属性
<property> <name>dfs.client.socket-timeout</name> <value>1800000</value> <description> timeout while waiting for channel to be scription write</description> </property> <property> <name>dfs.datanode.socket.write.timeout</name> <value>1800000</value> <description> timeout while waiting for channel to be ready for write</description> </property>
Unknown Job
standy
当两个 namenode 都是 standy 时,强制设置有效 namenode。
hdfs haadmin -transitionToActive –forcemanual nn1
namenode 消失
正常启动 hadoop 后,过十几秒 namenode 就消失了。查日志发现是 8485 failed on connection exception: java.net.ConnectException: Connection refused。
-
原因 用
start-dfs.sh启动的集群,journalnode(端口8485)是在namenode后启动的。默认情况下namenode启动10s(maxRetries=10, sleepTime=1000)后journalnode还没有启动,就会报上述错误。 -
解决方案
1.1 修改 core-site.xml 延长时间和连接次数
<!--修改core-site.xml中的ipc参数,防止出现连接journalnode服务ConnectException--> <property> <name>ipc.client.connect.max.retries</name> <value>100</value> <description>Indicates the number of retries a client will make to establish a server connection.</description> </property> <property> <name>ipc.client.connect.retry.interval</name> <value>10000</value> <description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.</description> </property>
2.1 先启动 journalnode
hadoop-daemons.sh start journalnode
start-dfs.sh
我选择后者
Will not attempt to authenticate using SASL
Zookeeper 出现问题了,分下列几种情况
Zookeeper挂了,zkServer.sh status来检测host配置不当,无法访问Zookeeper
local-dirs are bad
一般为磁盘满了,清理 or 增加磁盘或者增加阈值
yarn-site.xml
<property> <name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name> <value>98.5</value> </property>
datanode 节点缺失
jps 显示 datanode 节点启动正常,但web 展示却缺失且 log 正常无报错,很大原因是几个 datanode 下的 storageID 相同,导致 namenode 只认一个 datenode。