http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.15.1/FlumeUserGuide.html
简介
Flume 是一个分布式的、可靠的、高可用的海量日志采集、聚合和传输系统。它的数据流模型为Source -> Channel -> Sink,其事务机制保证消息传递的可靠性。
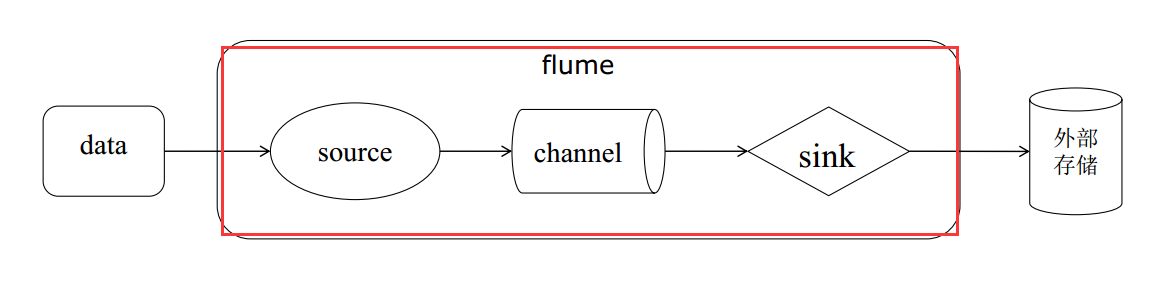
Event:消息的基本单位,由header和body组成Agent:JVM 进程,负责将一端外部来源产生的消息转发到另一端外部的目的地Source:从外部来源读入event,并写入channelChannel:event暂存组件,source写入后,event将会一直保存,直到被Sink成功消费Sink:从channel读入event,并写入目的地
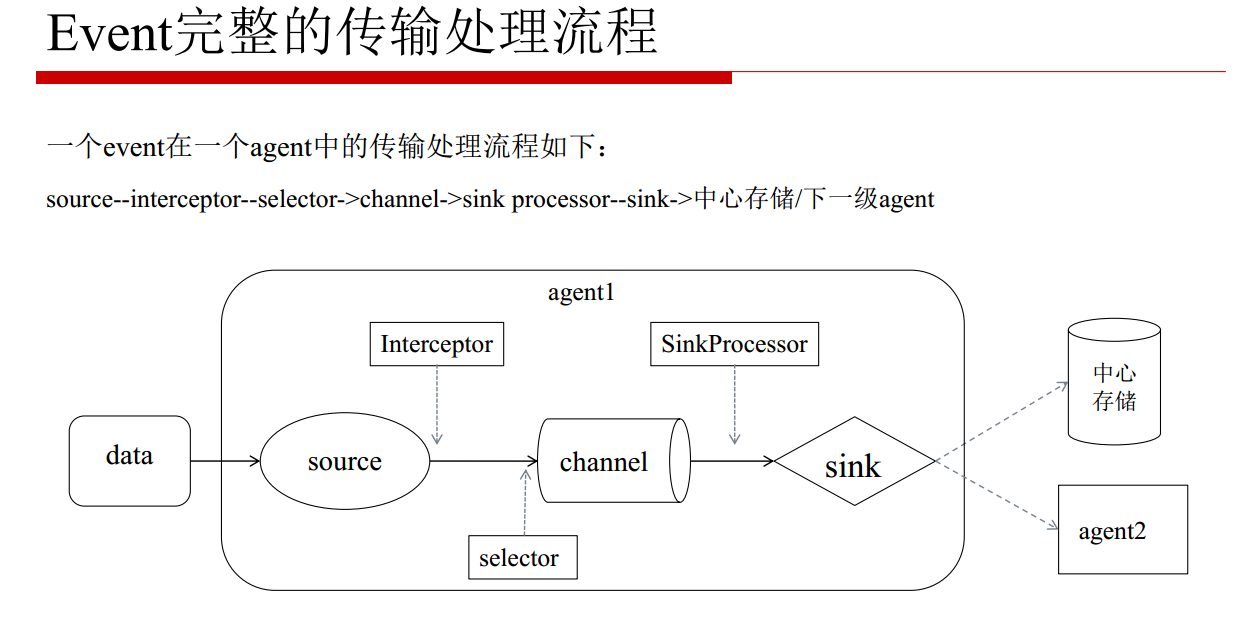
组件
Source 组件
对接各种外部数据源,将收集到的event 发送到 channel 中,一个 source 可以向多个 channel 发送 event,Flume 内置非常丰富的 Source,同时用户可以自定义 Source
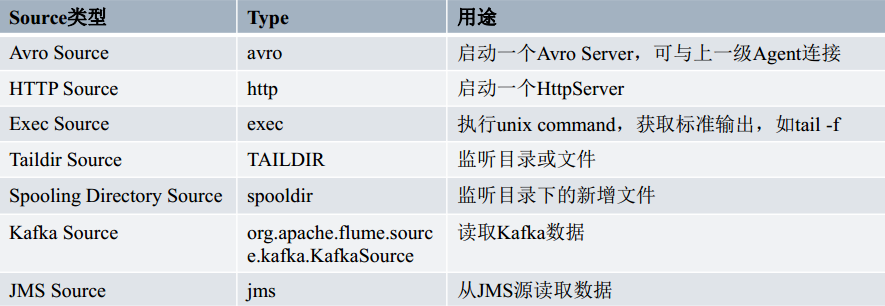
Avro Source

Exce Source

Taildir Source


Kafka Source
只能接受新的消息,已存在的消息无法接收

Channel 组件
- 被设计为
event中转暂存区,存储Source收集但还没被Sink消费的event,为了平衡Source收集和Sink读取速度,可视为Flume内部的消息队列 - 线程安全的并且具有事务性,支持
Source写失败重复写和Sink读失败重复读操作
Memory Channel

File Channel



Kafka Channel

Interceptor 拦截器
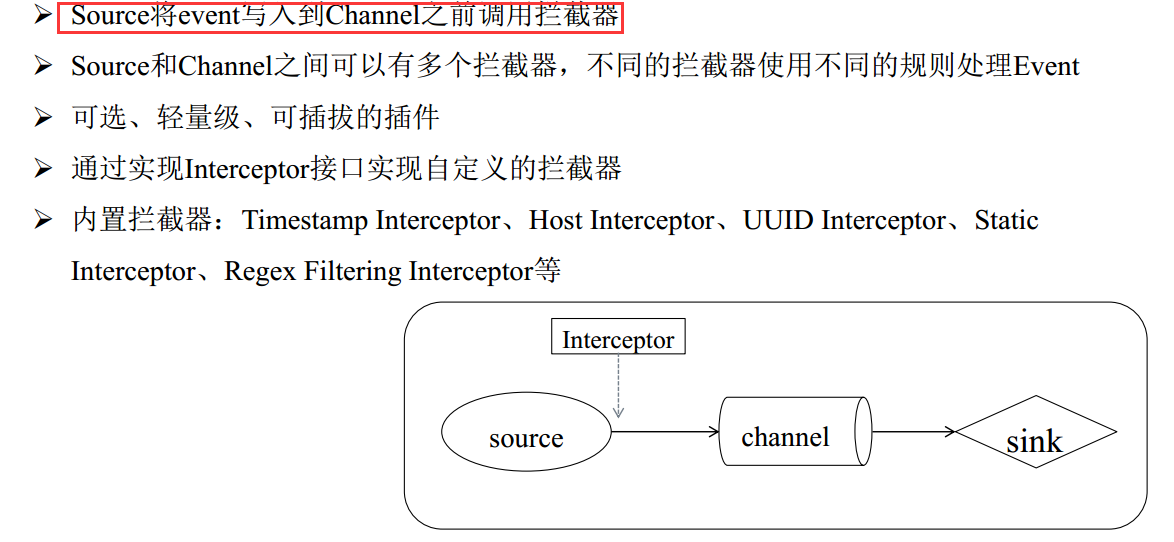
Timestamp Interceptor

Host Interceptor

Static Interceptor

Sink 组件

Avro Sink

HDFS Sink



Kafka Sink

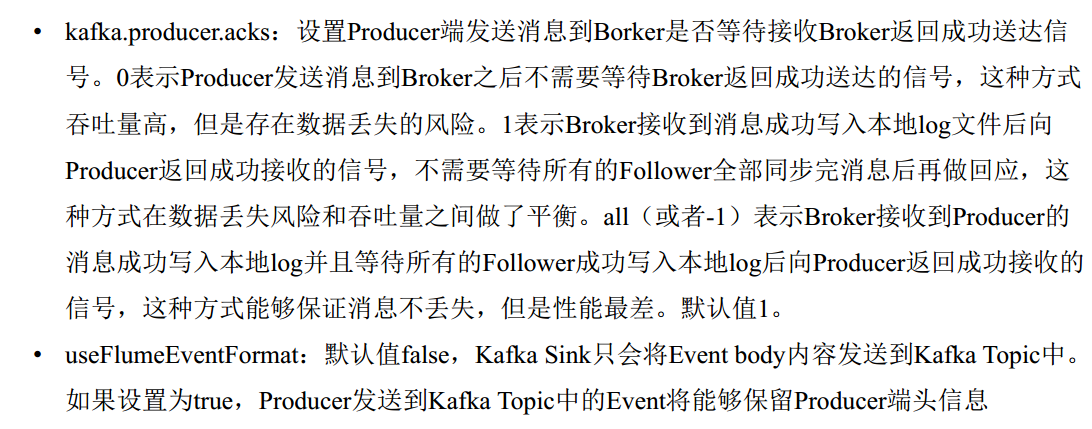
Selector 选择器
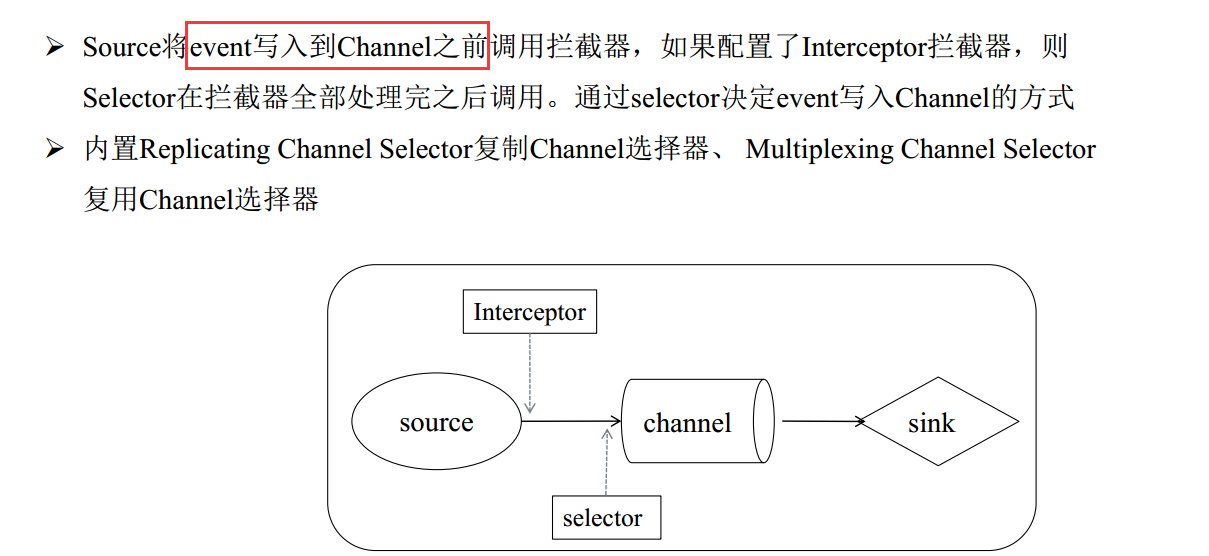
Replicating Channel Selector

Multiplexing Channel Selector

Sink Processor
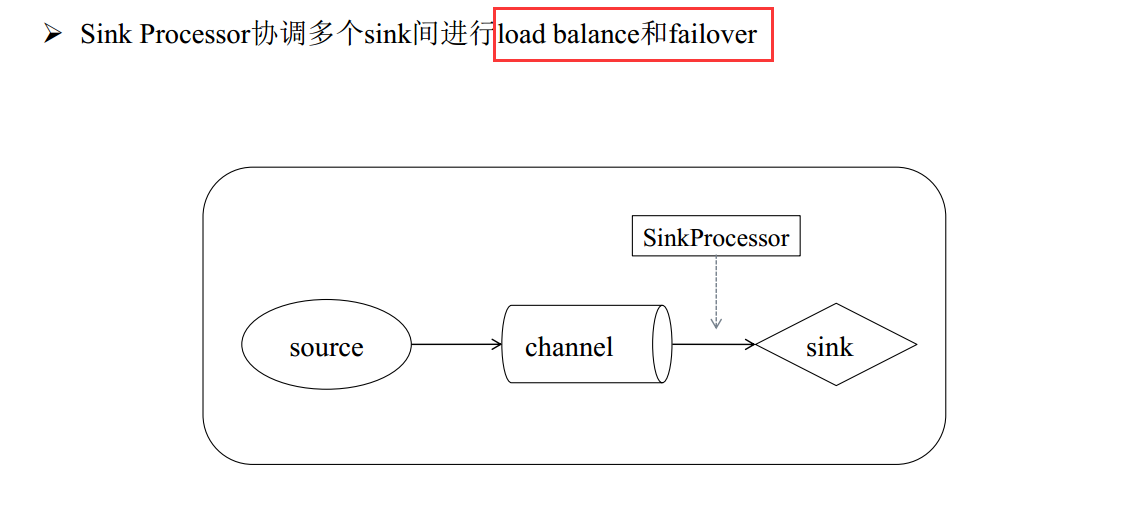
Load-Balancing Sink Processor

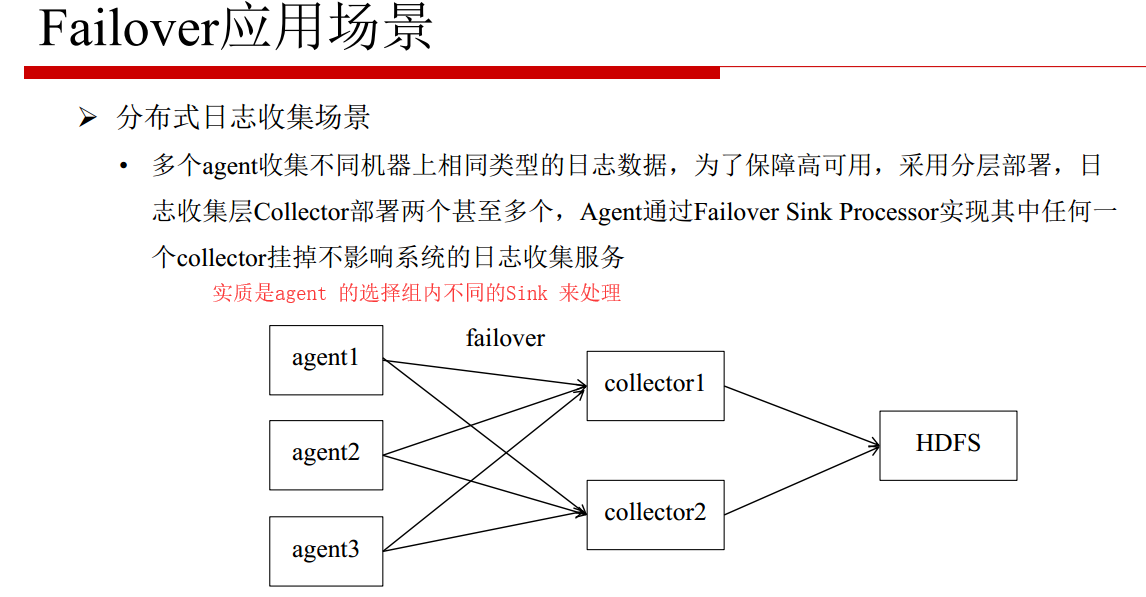
Failover Sink Processor

应用
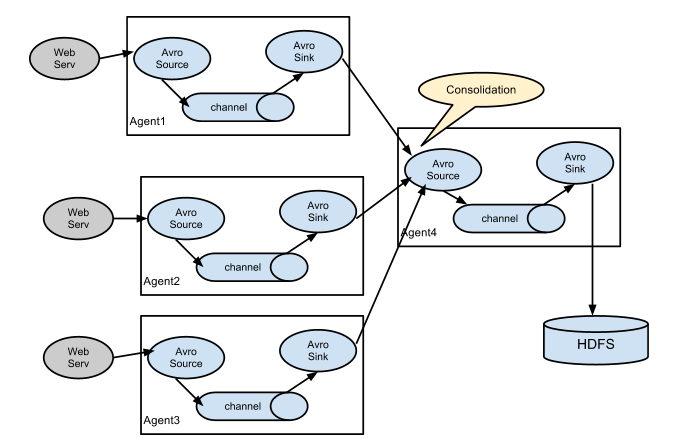
聚合
将运行在多台机器上的 Flume Agent 聚合到一台机器上。
容错处理
设置 Sink Processors 类型为 failover,将 channel 有优先级的输出到不同的 Sink,这样每个 Sink 连接的 Agent 就是不同的数据通道,保证高可用
QA
Flume 优化
- Source
- TailDir
- 增加 filegroup 个数,增加数据采集并行度
- batchSize:Source -> Channel 的个数(参考1万-5万)
- TailDir
- Channel
- Memory
- File
- 多个盘符、磁盘要求高
- capacity:当前 Channel 能存的最大 event
- transactionCapacity:从 Source 取或者输出到 Sink 的event 最大数
- Source/Sink:batchSize 要比 transactionCapacity 小
- Sink
- 多个 Sink 增加吞吐量;但每个 Sink 后会再跟 Agent 进程,增大开销
Flume Agent 必须先保证 failover,若机器资源还有结余再增加 load_balance
Flume 监控
只监控 channel 的状态即可。
- JMX Reporting
- Ganglia
- JSON Reporting