一些小姿势
hdfs ha架构图梳理
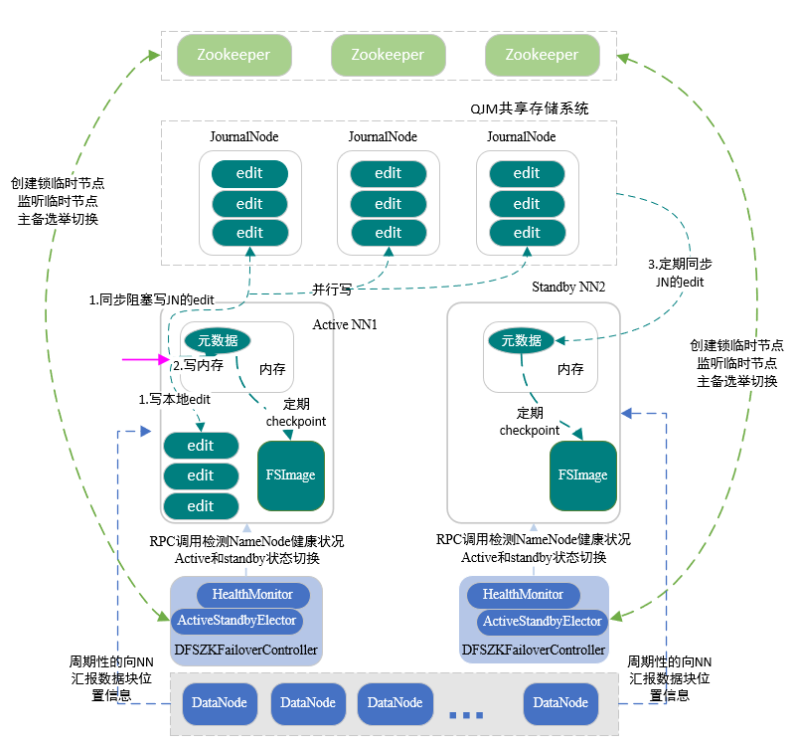
两个 namenode 保证了 hdfs 高可用,下面来了解下是如何保证两个 namenode 自动切换以及内容一致:
Zookeeper:ZKFC一启动就会抢先在Zookeeper集群创建临时节点,谁先创建谁就是active NN;此时,standby NN会一直关注临时节点状态,发现被销毁则表示原先的active NN出现问题;standby NN就会自动去创建临时节点,一旦创建成功,standby NN就变成了active NN。
我们都知道 NN 记录 HDFS 上所有文件存储信息,由fsimage 和 edits 一起完成:edits 负责编辑日志,客户端对目录和文件的写操作首先被写到 edit 日志中,如:创建文件、删除文件等;fsimage 负责文件系统元数据检查点镜像文件,保存了文件系统中所有的目录和文件信息,如:一个目录下有那些子目录、子文件、文件名,文件副本数,文件由哪些块组成等。
JournalNode:共享存储系统,active NN写入edits,而standby NN定期读edits,从而保证edits内容同步DataNode:DataNode会周期性的同时向两个NN上报本节点的数据信息,从而实现fsimage信息一致
yarn ha架构图梳理
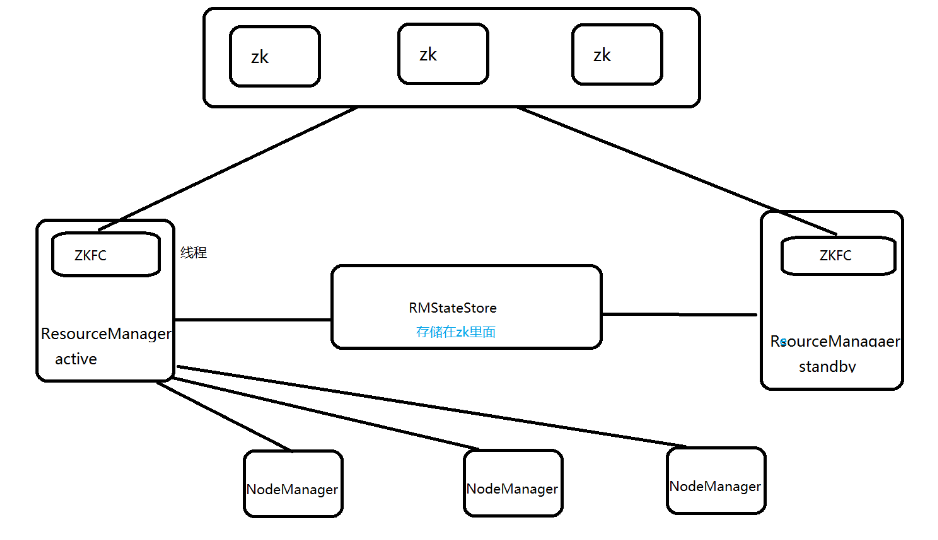
如上图所示,yarn 的高可用实现同样需要两个 ResourceManager,大体上与 hdfs 类似。下面重点关注他们的不同之处
hdfs yarn ha 架构区别
-
启动不同:
start-dfs.sh脚本会同时启动两个NN,而start-yarn.sh却只能启动一个ResourceManager;如果要启动另外一个ResourceManager必须去其他对应的机器执行yarn-daemon.sh start resourcemanager,关闭同理 -
ZKFC:虽然两者都是靠Zookeeper来显示自动切换,但hdfs是单独启动一个ZKFC进程来负责,而yarn是在ResourceManager进程中启动一个ZKFC线程来负责,显然两者的重要程度不同 -
共享系统:
hdfs是有由JournalNode组成的共享储存系统,而yarn仅仅是将记录保存在Zookeeper里(Zookeeper存储信息有限)
由此可见,yarn 的高可用结构比 hdfs 弱太多了。
hdfs dfs -ls 结果是哪个目录
查看 hdfs 的 /user/用户 目录。举例,当前用户为 hadoop,那么 hdfs dfs -ls 就是查看 /user/hadoop 目录
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs dfs -ls /user/hadoop/
Found 1 items
-rw-r--r-- 3 hadoop hadoop 70 2019-08-24 18:19 /user/hadoop/HDFS_HA.log
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs dfs -ls
Found 1 items
-rw-r--r-- 3 hadoop hadoop 70 2019-08-24 18:19 HDFS_HA.log
双写的理解
当只存在一条数据链路时(数据从终端到存储系统的通道),若发生事故则数据就会丢失。那么就需要一条备用的链路来保证数据正常的流通,且备用链路的架构与之前链路不同,这样才能在发生事故时两条链路不会同时失效。但需要注意的是,两条链路是同时工作的,这就需要保证数据的唯一性
小文件的理解 什么的小文件,危害,如何避免(产生前,产生后)
小文件是指文件大小小于 HDFS 块大小的文件,它会严重影响 Hadoop的扩展和性能。
namenode机器的内存会保存所有文件的路径,内存是固定的(文件数已固定);那么小文件增多会导致整个HDFS可存储的容量减少。- 小文件增多肯定会导致任务处理所需要读取的
datanode节点增多,导致更多网络链接,严重影响性能;处理大量小文件速度远远小于处理同等大小的文件速度:每个小文件要占用slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
如何避免:
- 产生前:
MapReduce和Spark任务在最终输出前,将小文件合并成大文件
- 产生后:
- 文件归档:将
HDFS上的小文件再次进行整理和保存,通过二层索引文件的查找,实现文件读取,这会减慢读取速度。可由hadoop archive命令产生归档文件 - 依赖外部系统的数据访问模式进行数据管理:产生的小文件不直接存入
HDFS中,而是直接存储到HBase
- 文件归档:将
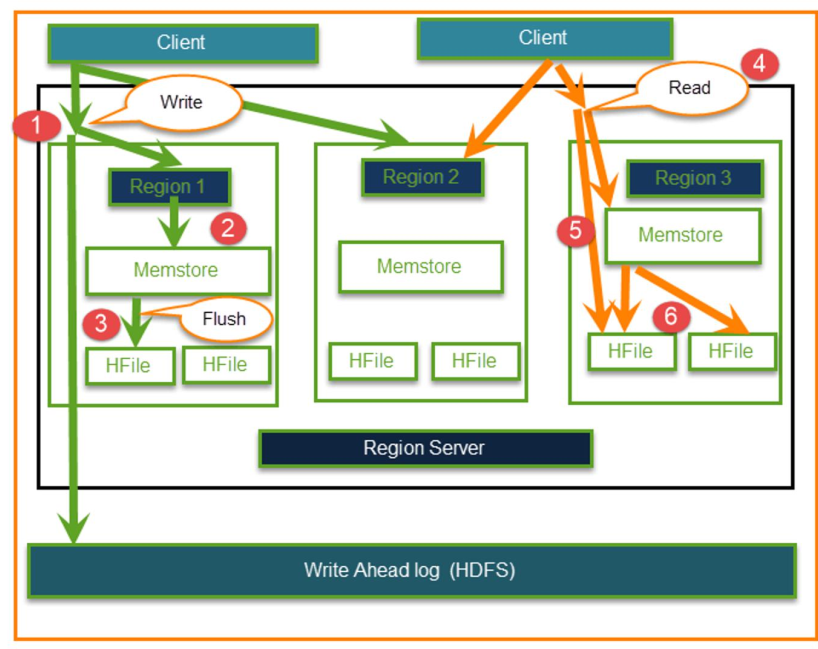
主从架构的 hbase 读写经过 master 进程吗?
不经过,直接操作 Region,如下图所示
Zookeeper
Zookeeper 在 Hadooop 集群中的重要性不用多说了,它是基石。想象这么一种情况:avtive NN 挂了,standby NN 去 Zookeepr 集群写文件,但此时运行Zookeeper 机器繁忙(该机器还有其他进程:namenode,datanode,nodemanager…),导致写文件延迟,那么切换 NN就会失败导致 HDFS 故障,这是很严重事故。那么该如何去解决:机器只允许运行 Zookeeper,这样就可以减少繁忙。 另外一个集群中,Zookeeper 节点数有经验值:
- 必须是
2N+1,这是选举需要 - 集群中机器数
<=20,可以用5个节点 - 集群中机器数
20~100,可使用7/9/11节点 - 集群中机器数
>100,可使用11节点 Zookeeper不是越多越好,节点越多,为了保证数据一致性就会耗费更多时间