一些小姿势
hdfs 常用命令整理
hdfs haadmin
run a DFS HA admin client
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs haadmin
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive <serviceId> [--forceactive]]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState <serviceId>]
[-checkHealth <serviceId>]
[-help <command>]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
查看 namenode 状态
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs haadmin -getServiceState nn1
active
切换 active namenode
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs haadmin -failover nn1 nn2
Failover to NameNode at danner002/172.16.19.36:8020 successful
# 切换成功,查看状态是否改变
[hadoop@izbp13e6ad3yxuuc3va7bez hadoop]$ hdfs haadmin -getServiceState nn2
active
hdfs fsck
run a DFS filesystem checking utility
hdfs fsck <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]
<path> 检查这个目录中的文件是否完整
-move 破损的文件移至/lost+found目录
-delete 删除破损的文件
-openforwrite 打印正在打开写操作的文件
-files 打印正在check的文件名
-blocks 打印block报告 (需要和-files参数一起使用)
-locations 打印每个block的位置信息(需要和-files参数一起使用)
-racks 打印位置信息的网络拓扑图 (需要和-files参数一起使用)
也可以通过浏览器直接访问地址,格式如下:
http://192.168.22.147:50070/fsck?ugi=hadoop&path=/a.txt&files=1&blocks=1
以上等同于命令: hdfs fsck /a.txt -files -blocks
查看整个某个文件状态
[hadoop@localhost ~]$ hdfs fsck /a.txt -files
// 文件大小 2 bytes,占 1 block,副本数为 1,
Connecting to namenode via http://192.168.22.147:50070/fsck?ugi=hadoop&files=1&path=%2Fa.txt
FSCK started by hadoop (auth:SIMPLE) from /192.168.22.147 for path /a.txt at Fri Aug 30 02:02:09 PDT 2019
/a.txt 2 bytes, 1 block(s): OK
Status: HEALTHY
Total size: 2 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 2 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Fri Aug 30 02:02:09 PDT 2019 in 1 milliseconds
查看某个文件 blocks 信息
[hadoop@izbp1ds3ppdemdhy7lsoofz ~]$ hdfs fsck /a.txt -files -blocks
Connecting to namenode via http://192.168.22.147:50070/fsck?ugi=hadoop&files=1&blocks=1&path=%2Fa.txt
FSCK started by hadoop (auth:SIMPLE) from /192.168.22.147 for path /a.txt at Fri Aug 30 02:05:56 PDT 2019
/a.txt 2 bytes, 1 block(s): OK
// 增加 block 信息: datanode 数据目录名:block索引 block_Id 块大小 副本数
0. BP-2123018093-127.0.0.1-1567154554685:blk_1073741825_1001 len=2 Live_repl=1
Status: HEALTHY
Total size: 2 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 2 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Fri Aug 30 02:05:56 PDT 2019 in 1 milliseconds
查看某个文件存储地址
Connecting to namenode via http://192.168.22.147:50070/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fa.txt
FSCK started by hadoop (auth:SIMPLE) from /192.168.22.147 for path /a.txt at Fri Aug 30 02:07:48 PDT 2019
/a.txt 2 bytes, 1 block(s): OK
// [] 就是存储地址信息,包含:访问端口,storageID=DataNode节点的存储器的全局编号,存储方式
// 但其实这个地址用处不是很大,DatanodeInfoWithStorage 只是告诉你存储在那台机器,且文件名是什么,并没有和实际文件系统相关联,还需在 datanode 数据目录下找到对应的文件
0. BP-2123018093-127.0.0.1-1567154554685:blk_1073741825_1001 len=2 Live_repl=1 [DatanodeInfoWithStorage[192.168.22.147:50010,DS-5e3e057f-bd04-4163-b91a-0111bc48948b,DISK]]
Status: HEALTHY
Total size: 2 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 2 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Fri Aug 30 02:07:48 PDT 2019 in 2 milliseconds
查看某个文件存储的机架信息
[hadoop@localhost current]$ hdfs fsck /a.txt -files -blocks -locations -racks
Connecting to namenode via http://192.168.22.147:50070/fsck?ugi=hadoop&files=1&blocks=1&locations=1&racks=1&path=%2Fa.txt
FSCK started by hadoop (auth:SIMPLE) from /192.168.22.147 for path /a.txt at Fri Aug 30 02:18:59 PDT 2019
/a.txt 2 bytes, 1 block(s): OK
// /default-rack/192.168.22.147:50010
0. BP-2123018093-127.0.0.1-1567154554685:blk_1073741825_1001 len=2 Live_repl=1 [/default-rack/192.168.22.147:50010]
Status: HEALTHY
Total size: 2 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 2 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Fri Aug 30 02:18:59 PDT 2019 in 2 milliseconds
查看 hdfs 损坏的块
hdfs fsck -list-corruptfileblocks
Connecting to namenode via http://hadoop36:50070/fsck?ugi=hdfs&listcorruptfileblocks=1&path=%2F
The list of corrupt files under path ‘/’ are:
blk_1075229920 /hbase/data/JYDW/WMS_PO_ITEMS/c71f5f49535e0728ca72fd1ad0166597/0/f4d3d97bb3f64820b24cd9b4a1af5cdd
blk_1075229921 /hbase/data/JYDW/WMS_PO_ITEMS/c96cb6bfef12795181c966a8fc4ef91d/0/cf44ae0411824708bf6a894554e19780
The filesystem under path ‘/’ has 2 CORRUPT files
显示有两个块损坏,继续查损坏块的存储信息
hdfs fsck blk_1075229920 -files -blocks -locations -racks
以上命令即可知道大致存储地址。下面提供一个修复思路:如果传统数据库中有备份
1、hdfs fsck / -delete 删除所有损坏的块
2、重新导入 hdfs
hdfs debug
Usage: hdfs debug <command> [arguments]
These commands are for advanced users only.
Incorrect usages may result in data loss. Use at your own risk.
verifyMeta -meta <metadata-file> [-block <block-file>] 验证HDFS元数据和块文件
computeMeta -block <block-file> -out <output-metadata-file> 从块文件中计算HDFS元数据
recoverLease -path <path> [-retries <num-retries>] 在指定的路径上恢复租约
// 尝试恢复 /a.txt 文件三次;最后有案例讲解
hdfs debug recoverLease -path /a.txt -retries 3
hdfs storagepolicies
Usage: bin/hdfs storagepolicies [COMMAND] 存储策略相关
[-listPolicies]
[-setStoragePolicy -path <path> -policy <policy>]
[-getStoragePolicy -path <path>]
[-help <command-name>]
设置 path 为内存存储
hdfs storagepolicies -setStoragePolicy -path
-policy LAZY_ PERSIST
hdfs balancer
均衡集群中 DN 间的数据量
dfs.datanode.balance.bandwidthPerSec 30m,设置 balance 时数据传输最大带宽/分钟
hdfs balancer -threshold 20,执行数据均衡工作,保证每个节点磁盘使用量和集群中节点的磁盘平均使用量小于20%,默认为10。一般在每日空闲时段(凌晨)执行,执行结束自动关闭
hdfs diskbalancer
单个 DN 节点下挂载的磁盘中数据均衡:为了高效率读、写,每个节点会挂载多个物理磁盘,那么就可能出现每个磁盘的使用量(df -h 命令查看)不同。均衡磁盘间的数据 ,分为三步
- hdfs-site.xml 中设置
dfs.disk.balancer.enabled为true hdfs diskbalancer -plan hostname生成 hostname 对应机子的磁盘信息:hostname.plan.jsonhdfs diskbalancer -execute hostname.plan.json执行
该命令在那些场景在执行呢?一般为手动执行
- 新加入磁盘时,此时新加的磁盘使用量肯定为0,数据必定不均衡
- 监控服务器的磁盘空间小于 10%时,发邮件报警然后手动
yarn 常用命令整理
yarn rmadmin
强制设置 rm2 为 active resourcemanager
yarn rmadmin -transitionToActive --forcemanual rm2
yarn application
列出运行的任务 id
yarn application -list
yarn logs
查看 jobId 任务日志(jobId 是上面命令的输出)
yarn logs -applicationId jobId
压缩算法
| 压缩算法 | 工具 | 算法 | 扩展名 | 是否支持分割 | Hadoop 编码/解码器 |
|---|---|---|---|---|---|
| DEFLATE | N/A | DEFLATE | .deflate | No | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | gzip | DEFLATE | .gz | No | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | No | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | Lzop | LZO | .lzo | Yes(if index) | com.hadoop.compressiion.lzo.LzoCodec |
| LZ4 | N/A | LZ4 | .lz4 | No | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | N/A | Snappy | .snappy | No | org.apache.hadoop.io.compress.SnappyCodec |
- gzip
- 压缩比在四种压缩方式中较高;
hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便 - 不支持
split
- 压缩比在四种压缩方式中较高;
- bzip2
- 支持
split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便 - 压缩/解压速度慢;不支持
native
- 支持
- lzo
- 压缩/解压速度也比较快,合理的压缩率;支持
split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便 - 压缩率比
gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)
- 压缩/解压速度也比较快,合理的压缩率;支持
- snappy
- 压缩速度快;支持
hadoop native库 - 不支持
split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
- 压缩速度快;支持
下面是这几种压缩方式对比
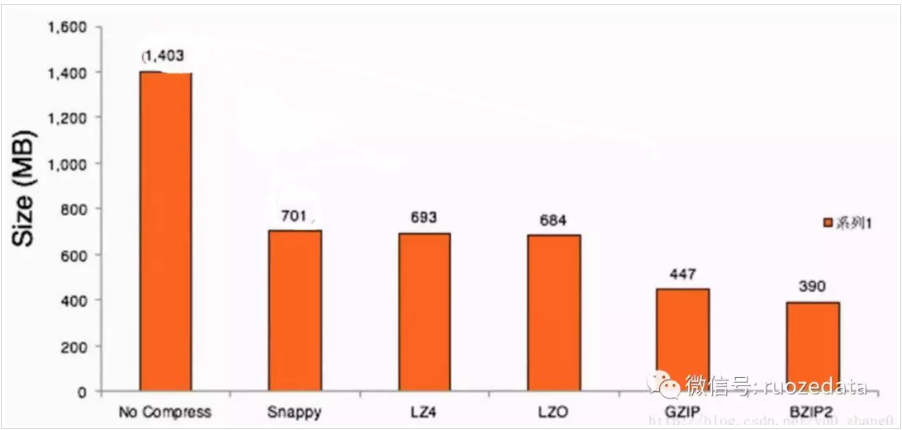
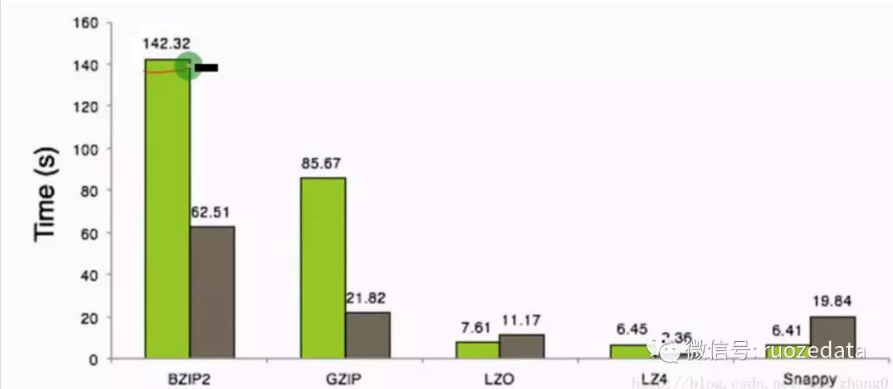
压缩比越高,压缩时间越长,压缩比:Snappy > LZ4 > LZO > GZIP > BZIP2
hadoop checknative 显示支持的压缩格式
[hadoop@hadoop001 ~]$ hadoop checknative
19/04/07 17:50:08 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
19/04/07 17:50:08 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
snappy: true /usr/lib64/libsnappy.so.1
lz4: true revision:99
bzip2: true /lib64/libbz2.so.1
openssl: true /usr/lib64/libcrypto.so
standby 节点
在实际的场景中我们能直接操作 standby namenode 吗?
danner001 是 standby namenode,danner002 是 active namenode
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs dfs -ls hdfs://danner002:8020
Found 2 items
drwx------ - hadoop hadoop 0 2019-08-24 18:24 hdfs://danner002:8020/user/hadoop/.Trash
-rw-r--r-- 3 hadoop hadoop 70 2019-08-24 18:19 hdfs://danner002:8020/user/hadoop/HDFS_HA.log
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs dfs -ls hdfs://danner001:8020
ls: Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
由此可见,无法直接查看 standby namenode
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs dfs -put jps.sh hdfs://danner002:8020/
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs dfs -ls hdfs://danner002:8020/
Found 3 items
-rw-r--r-- 3 hadoop hadoop 436 2019-08-26 23:01 hdfs://danner002:8020/jps.sh
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs dfs -put start_cluster.sh hdfs://danner001:8020/
put: Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
同样无法直接操作 standby namenode
hdfs的安全模式
安全模式是 HDFS 所处的一种特殊状态。在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在 NameNode 主节点启动时,HDFS 首先进入安全模式,DataNode 在启动的时候会向 namenode 汇报可用的 block 等状态,当整个系统达到安全标准时,HDFS 自动离开安全模式。要离开安全模式,需要满足以下条件:
- 达到副本数量要求的
block比例满足要求; - 可用的
datanode节点数满足配置的数量要求; - 以上两个条件满足后维持的时间达到配置的要求。
hadoop dfsadmin -safemode
hadoop dfsadmin -safemode get // 查看当前状态
hadoop dfsadmin -safemode enter // 进入安全模式
hadoop dfsadmin -safemode leave // 强制离开安全模式
hadoop dfsadmin -safemode wait // 一直等待直到安全模式结束
启动日志
# 进入安全模式
2019-08-26 22:34:44,391 INFO org.apache.hadoop.hdfs.StateChange: STATE* Safe mode ON, in safe mode extension.
The reported blocks 2 has reached the threshold 0.9990 of total blocks 2. The number of live datanodes 2 has reached the minimum number 0.
In safe mode extension. Safe mode will be turned off automatically in 9 seconds.
# 退出安全模式
2019-08-26 22:34:54,393 INFO org.apache.hadoop.hdfs.StateChange: STATE* Leaving safe mode after 41 secs
2019-08-26 22:34:54,393 INFO org.apache.hadoop.hdfs.StateChange: STATE* Safe mode is OFF
2019-08-26 22:34:54,393 INFO org.apache.hadoop.hdfs.StateChange: STATE* Network topology has 1 racks and 2 datanodes
2019-08-26 22:34:54,393 INFO org.apache.hadoop.hdfs.StateChange: STATE* UnderReplicatedBlocks has 0 blocks
hdfs ha 启动过程
namenode -> datanode -> journalnode -> ZKFC
Starting namenodes on [danner001 danner002]
danner001: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-namenode-izbp13e6ad3yxuuc3va7bez.out
danner002: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-namenode-izbp13e6ad3yxuuc3va7bfz.out
danner003: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-datanode-izbp13e6ad3yxuuc3va7bgz.out
danner001: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-datanode-izbp13e6ad3yxuuc3va7bez.out
danner002: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-datanode-izbp13e6ad3yxuuc3va7bfz.out
Starting journal nodes [danner001 danner002 danner003]
danner003: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-journalnode-izbp13e6ad3yxuuc3va7bgz.out
danner001: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-journalnode-izbp13e6ad3yxuuc3va7bez.out
danner002: starting journalnode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-journalnode-izbp13e6ad3yxuuc3va7bfz.out
Starting ZK Failover Controllers on NN hosts [danner001 danner002]
danner001: starting zkfc, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-zkfc-izbp13e6ad3yxuuc3va7bez.out
danner002: starting zkfc, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/logs/hadoop-hadoop-zkfc-izbp13e6ad3yxuuc3va7bfz.out
停止的顺序与启动相同
整理故障案例
线上常常会有副本丢失的情况,这种情况我们可以手动 hdfs debug 修复
正常情况,文件 Average block replication: 3.0
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs fsck /jps.sh -files -blocks -locations
Connecting to namenode via http://danner002:50070/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fjps.sh
FSCK started by hadoop (auth:SIMPLE) from /172.16.19.39 for path /jps.sh at Sat Aug 31 14:51:28 CST 2019
/jps.sh 436 bytes, 1 block(s): OK
0. BP-829956989-172.16.19.39-1567220628599:blk_1073741825_1001 len=436 Live_repl=3 [DatanodeInfoWithStorage[172.16.19.37:50010,DS-2b1fd634-a411-4a3a-bfd6-b56e4d3fb388,DISK], DatanodeInfoWithStorage[172.16.19.39:50010,DS-a1eb846d-f16f-4be4-abd4-3ff54ccb00e8,DISK], DatanodeInfoWithStorage[172.16.19.36:50010,DS-ee383a4d-b17a-4585-980f-fd0f949f21d3,DISK]]
Status: HEALTHY
Total size: 436 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 436 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Sat Aug 31 14:51:28 CST 2019 in 1 milliseconds
为了模拟文件损坏情况,直接给文件的某个副本的元数据文件追加信息导致副本数据异常
[hadoop@izbp13e6ad3yxuuc3va7bfz subdir0]$ echo "123" >> blk_1073741825
为了让namenode 立刻意识到副本异常,整个集群重启(不然下次扫描要等6个小时);再次查看文件状态
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs fsck /jps.sh -files -blocks -locations
Connecting to namenode via http://danner002:50070/fsck?ugi=hadoop&files=1&blocks=1&locations=1&path=%2Fjps.sh
FSCK started by hadoop (auth:SIMPLE) from /172.16.19.39 for path /jps.sh at Sat Aug 31 14:57:41 CST 2019
/jps.sh 436 bytes, 1 block(s): Under replicated BP-829956989-172.16.19.39-1567220628599:blk_1073741825_1001. Target Replicas is 3 but found 2 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
// 注意此处 BP-829956989-172.16.19.39-1567220628599 不是损坏 datanode 地址,而是当前执行命令 datanode 的地址
// 所以此处我们并不能得到损坏的 datanode 地址
0. BP-829956989-172.16.19.39-1567220628599:blk_1073741825_1001 len=436 Live_repl=2 [DatanodeInfoWithStorage[172.16.19.37:50010,DS-2b1fd634-a411-4a3a-bfd6-b56e4d3fb388,DISK], DatanodeInfoWithStorage[172.16.19.39:50010,DS-a1eb846d-f16f-4be4-abd4-3ff54ccb00e8,DISK]]
Status: HEALTHY
Total size: 436 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 436 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 2.0
Corrupt blocks: 0
Missing replicas: 1 (33.333332 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Sat Aug 31 14:57:41 CST 2019 in 8 milliseconds
hdfs debug 修复文件
[hadoop@izbp1ds3ppdemdhy7lsoofz hadoop]$ hdfs debug recoverLease -path /jps.sh -retries 10
recoverLease SUCCEEDED on /jps.sh
参考资料
大数据压缩,你们真的了解吗?
HDFS安全模式详解
hdfs fsck命令查看HDFS文件对应的文件块信息(Block)和位置信息
HDFS命令指南