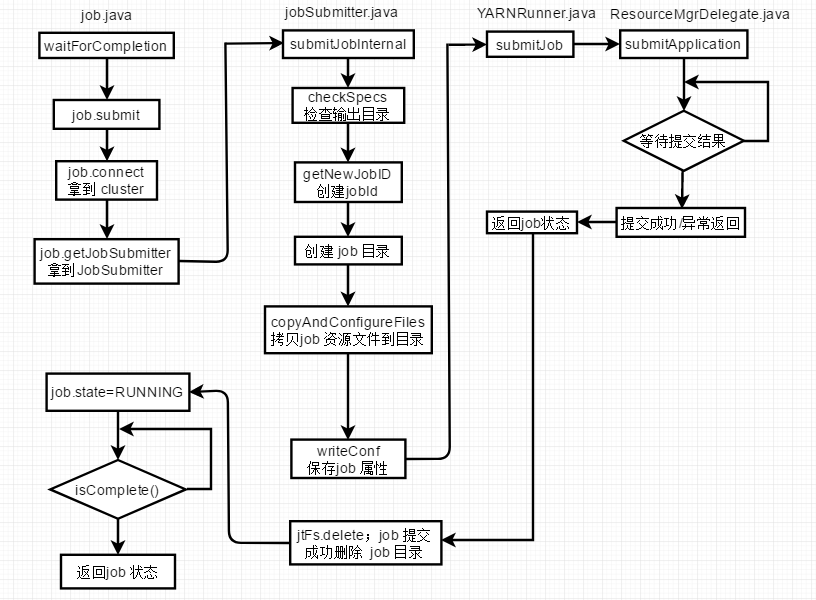
Hadoop 中的 job 任务包含 Mapper 和 Reducer 过程;但这只是最简单的划分,为了理清 job的执行过程将其划分为:job 层、MR 层,每层又由很多小部分组成。
job 层
job.waitForCompletion(true) 是我们提交 job 任务代码,从这个切入点出发:
一、判断 job 状态,准备提交任务
// job.java
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
// state 初始化就是 JobState.DEFINE
// 注意 state 标识跟随 job 整个周期
if (state == JobState.DEFINE) {
// 重点在这里
submit();
}
// 等待 job 结束
if (verbose) {
// monitorAndPrintJob 中 1s 调用 isComplete() 一次;progMonitorPollIntervalMillis 控制
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
// completionPollIntervalMillis 调用一次,isComplete 实质是调用 clientCache.getClient(jobId).getJobStatus(jobId) 获取状态
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
二、提交任务,修改 job 状态为 RUNNING
// job.java
/**
* Submit the job to the cluster and return immediately.
* @throws IOException
*/
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
// 确认状态
ensureState(JobState.DEFINE);
setUseNewAPI();
// 为了得到 cluster -> YARNRunner(集群)
connect();
// 有 cluster 后,构建 submitter 对象
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
// submitter 对象提交任务
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
三、submitJobInternal 才是我们真正需要关注的东西
// JobSubmitter.java
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
// 检查输出目录
checkSpecs(job);
...
// 创建一个 staging 目录
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
...
// 获取 job ID:application_id { id: 3 cluster_timestamp: 1567478115673 }
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 本Job对应的目录: staging + jobid => /tmp/hadoop-yarn/staging/hadoop/.staging/job_1567478115673_0003
// 此目录存放 job 涉及到的jar、tmpfiles 等文件
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
try {
...
// job 的资源复制到 submitJobDir 目录(JobResourceUploader.java)
copyAndConfigureFiles(job, submitJobDir);
// /tmp/hadoop-yarn/staging/hadoop/.staging/job_1567478115673_0003/job.xml
// 保存 job 任务的属性
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// InputSplit 这是重点,MR 中会详细分析
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
...
// Job 的信息写入到 job.xml
writeConf(conf, submitJobFile);
// 下面才真的提交任务 ^-^
//
// Now, actually submit the job (using the submit name)
//
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
// 任务提交成功后,清空 Job 对应的目录
jtFs.delete(submitJobDir, true);
}
}
3.1、检查输出目录(已存在抛异常)
// 继承 OutputFormat 的类,即任务输出类
public void checkOutputSpecs(JobContext job
) throws FileAlreadyExistsException, IOException{
// Ensure that the output directory is set and not already there
Path outDir = getOutputPath(job);
// 输出路径为空, "Output directory not set." 异常
if (outDir == null) {
throw new InvalidJobConfException("Output directory not set.");
}
// get delegation token for outDir's file system
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { outDir }, job.getConfiguration());
// 输出目录已存在,"Output directory " + outDir + " already exists" 异常
if (outDir.getFileSystem(job.getConfiguration()).exists(outDir)) {
throw new FileAlreadyExistsException("Output directory " + outDir +
" already exists");
}
3.2、staging 目录
// MRApps.java => /tmp/hadoop-yarn/staging/hadoop/.staging
private static final String STAGING_CONSTANT = ".staging";
public static Path getStagingAreaDir(Configuration conf, String user) {
return new Path(conf.get(MRJobConfig.MR_AM_STAGING_DIR,
MRJobConfig.DEFAULT_MR_AM_STAGING_DIR)
+ Path.SEPARATOR + user + Path.SEPARATOR + STAGING_CONSTANT);
}
3.3、job 提交到 ResourceManager
// YARNRunner.java
public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts)
throws IOException, InterruptedException {
addHistoryToken(ts);
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);
// Submit to ResourceManager
try {
ApplicationId applicationId =
resMgrDelegate.submitApplication(appContext);
ApplicationReport appMaster = resMgrDelegate
.getApplicationReport(applicationId);
String diagnostics =
(appMaster == null ?
"application report is null" : appMaster.getDiagnostics());
if (appMaster == null
|| appMaster.getYarnApplicationState() == YarnApplicationState.FAILED
|| appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) {
throw new IOException("Failed to run job : " +
diagnostics);
}
// 获取 job 状态
// 上面等待 job 结束实质也是调用这段代码
return clientCache.getClient(jobId).getJobStatus(jobId);
} catch (YarnException e) {
throw new IOException(e);
}
3.4: job 客户端
// ResourceMgrDelegate.java
public ApplicationId submitApplication(ApplicationSubmissionContext appContext)
throws YarnException, IOException {
return client.submitApplication(appContext);
// YarnClientImpl.java
public ApplicationId
submitApplication(ApplicationSubmissionContext appContext)
throws YarnException, IOException {
...
// job 包装成 request
SubmitApplicationRequest request =
Records.newRecord(SubmitApplicationRequest.class);
request.setApplicationSubmissionContext(appContext);
// rmClient 是 RM 的代理类,这里才是真的提交 job 到 yarn
//TODO: YARN-1763:Handle RM failovers during the submitApplication call.
rmClient.submitApplication(request);
int pollCount = 0;
long startTime = System.currentTimeMillis();
EnumSet<YarnApplicationState> waitingStates =
EnumSet.of(YarnApplicationState.NEW,
YarnApplicationState.NEW_SAVING,
YarnApplicationState.SUBMITTED);
EnumSet<YarnApplicationState> failToSubmitStates =
EnumSet.of(YarnApplicationState.FAILED,
YarnApplicationState.KILLED);
// 死等 job 提交成功或者job 异常才返回;200 ms 查询一次状态
while (true) {
try {
ApplicationReport appReport = getApplicationReport(applicationId);
YarnApplicationState state = appReport.getYarnApplicationState();
if (!waitingStates.contains(state)) {
if(failToSubmitStates.contains(state)) {
throw new YarnException("Failed to submit " + applicationId +
" to YARN : " + appReport.getDiagnostics());
}
LOG.info("Submitted application " + applicationId);
break;
}
...
// 200 ms
try {
Thread.sleep(submitPollIntervalMillis);
} catch (InterruptedException ie) {
LOG.error("Interrupted while waiting for application "
+ applicationId
+ " to be successfully submitted.");
}
} catch (ApplicationNotFoundException ex) {
// FailOver or RM restart happens before RMStateStore saves
// ApplicationState
LOG.info("Re-submit application " + applicationId + "with the " +
"same ApplicationSubmissionContext");
// 异常,重新提交
rmClient.submitApplication(request);
}
}
return applicationId;
3.5 实时获取 job 状态
// job.java
public boolean isComplete() throws IOException {
ensureState(JobState.RUNNING);
updateStatus();
return status.isJobComplete();
}
/** Some methods need to update status immediately. So, refresh
* immediately
* @throws IOException
*/
synchronized void updateStatus() throws IOException {
try {
this.status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
@Override
public JobStatus run() throws IOException, InterruptedException {
// 获取状态
return cluster.getClient().getJobStatus(getJobID());
}
});
}
catch (InterruptedException ie) {
throw new IOException(ie);
}
if (this.status == null) {
throw new IOException("Job status not available ");
}
this.statustime = System.currentTimeMillis();
}
job 层流程分析到这里,下面以一副图来总结下