之前两节关于生产者和 Broker,本节剖析消费者流程。kafka 消费过程中,有个重要的组件 Coordinator,它协调同个消费组下的消费者。我们熟知的一条规律:同一时间下同个分区只会被同个消费组消费一次,就是 Coordinator 功劳。kafka consumer 消费数据流程如下:
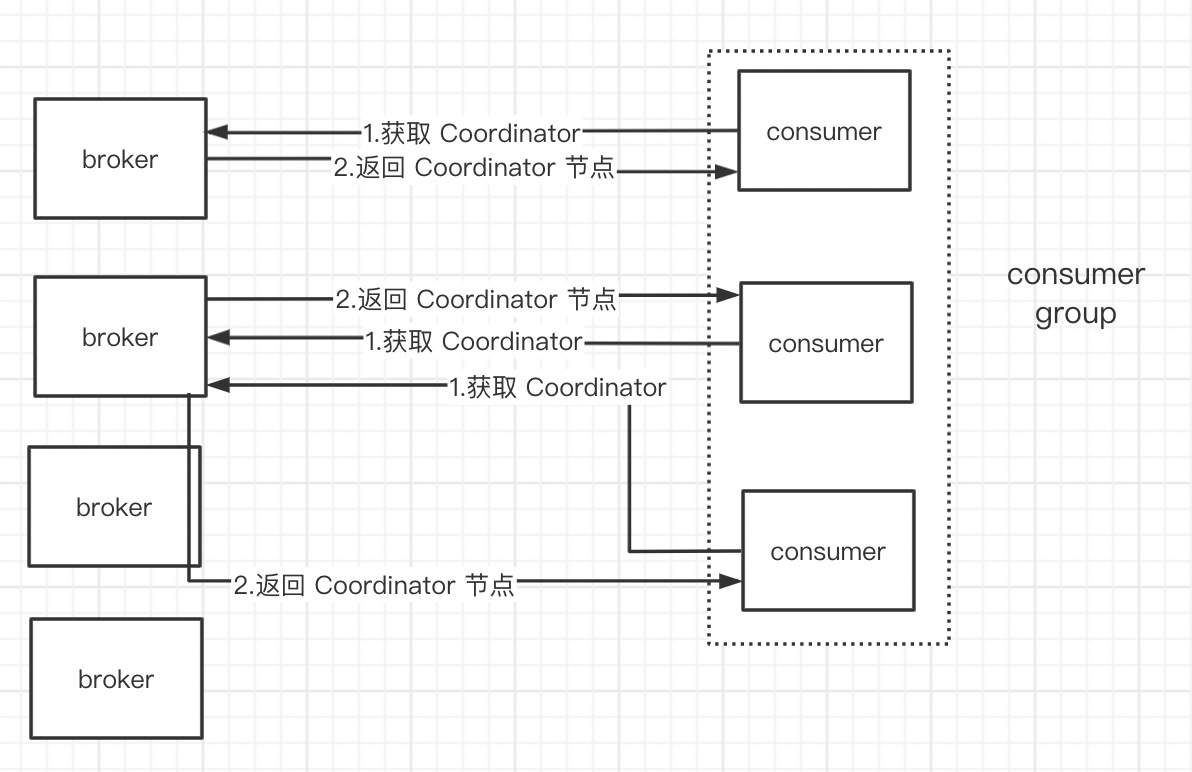
- consumer 向某个 broker 发送询问当前 group 的 Coordinator
- broker 根据 group hash值取模
__consumer_offset分区数 index,__consumer_offset第 index 分区的 leader 所在的 broker 就是 group 的Coordinator(所有 offset 也是提交到这个分区) - consumer 向
Coordinator发送 join group 请求 Coordinator将第一个发送 join group 请求的 consumer 设置为 consumer leader- consumer leader 制定分区消费方案:同个消费组下,指定哪个 consumer 消费哪个分区,并将其发送给
Coordinator Coordinator将消费方案下发到同个 group 下的 consumer- consumer 消费数据并提交 offset
// consumer = new KafkaConsumer<>(props);
// -> consumer.subscribe(topics)
// -> consumer.poll(1000)
// org.apache.kafka.clients.consumer.KafkaConsumer
public ConsumerRecords<K, V> poll(long timeout) {
...
// poll for new data until the timeout expires
long start = time.milliseconds();
long remaining = timeout;
do {
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining);
if (!records.isEmpty()) {
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
fetcher.sendFetches();
client.pollNoWakeup();
if (this.interceptors == null)
return new ConsumerRecords<>(records);
else
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
long elapsed = time.milliseconds() - start;
remaining = timeout - elapsed;
} while (remaining > 0); // 一直循环直到超时/获取到数据
...
}
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
// 1、确认 Coordinator 和已加入 joinGroup
coordinator.poll(time.milliseconds());
// fetch positions if we have partitions we're subscribed to that we
// don't know the offset for
if (!subscriptions.hasAllFetchPositions())
// // 更新 offset
updateFetchPositions(this.subscriptions.missingFetchPositions());
// 处理拉取到的数据,completedFetches
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty())
return records;
// 拉取数据请求,与副本数据同步类似,发送 ApiKeys.FETCH
// 拉取到的数据存放到 completedFetches
fetcher.sendFetches();
long now = time.milliseconds();
long pollTimeout = Math.min(coordinator.timeToNextPoll(now), timeout);
client.poll(pollTimeout, now, new PollCondition() {
@Override
public boolean shouldBlock() {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasCompletedFetches();
}
});
...
return fetcher.fetchedRecords();
}
Coordintor
// org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
public void poll(long now) {
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.partitionsAutoAssigned() && coordinatorUnknown()) {
// 搜寻 Coordinator
ensureCoordinatorReady();
now = time.milliseconds();
}
// 加入 joinGroup
if (needRejoin()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster's topics at least once before joining.
if (subscriptions.hasPatternSubscription())
client.ensureFreshMetadata();
// 有 Coordinator 后 joinGroup
ensureActiveGroup();
now = time.milliseconds();
}
// 发送心跳
pollHeartbeat(now);
// 提交 offset (当有数据消费后)
maybeAutoCommitOffsetsAsync(now);
}
public synchronized void ensureCoordinatorReady() {
// 死循环直到确认 Coordinator
while (coordinatorUnknown()) {
RequestFuture<Void> future = lookupCoordinator();
// 无限期的阻塞,直到请求结束
client.poll(future);
...
}
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// find a node to ask about the coordinator
// 随便找一台 broker 请求,因为每台 broker 都包含集群元数据
Node node = this.client.leastLoadedNode();
...
} else
// 发送获取 Coordinator 请求
findCoordinatorFuture = sendGroupCoordinatorRequest(node);
}
return findCoordinatorFuture;
}
private RequestFuture<Void> sendGroupCoordinatorRequest(Node node) {
// initiate the group metadata request
log.debug("Sending coordinator request for group {} to broker {}", groupId, node);
GroupCoordinatorRequest metadataRequest = new GroupCoordinatorRequest(this.groupId);
// 携带 group id,ApiKeys.GROUP_COORDINATOR
// 回调函数 GroupCoordinatorResponseHandler
return client.send(node, ApiKeys.GROUP_COORDINATOR, metadataRequest)
.compose(new GroupCoordinatorResponseHandler());
}
broker
// kafka.server.KafkaApis
// case ApiKeys.GROUP_COORDINATOR => handleGroupCoordinatorRequest(request)
def handleGroupCoordinatorRequest(request: RequestChannel.Request) {
val groupCoordinatorRequest = request.body.asInstanceOf[GroupCoordinatorRequest]
...
// groupID hash ,获取当前消费组 Coordinator 所在的 __consumer_offset 分区
// Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount(默认50)
val partition = coordinator.partitionFor(groupCoordinatorRequest.groupId)
// get metadata (and create the topic if necessary)
// __consumer_offsets topic metadata
val offsetsTopicMetadata = getOrCreateGroupMetadataTopic(request.securityProtocol)
// GroupCoordinatorResponse
val responseBody = if (offsetsTopicMetadata.error != Errors.NONE) {
new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode)
} else {
// coordinatorEndpoint 就是 Coordintor 所在的 broker
val coordinatorEndpoint = offsetsTopicMetadata.partitionMetadata().asScala
.find(_.partition == partition)
// 获取 partition leader 的 broker
.map(_.leader())
coordinatorEndpoint match {
case Some(endpoint) if !endpoint.isEmpty =>
// 正常情况,这里返回(ip,port ...)
new GroupCoordinatorResponse(Errors.NONE.code, endpoint)
case _ =>
new GroupCoordinatorResponse(Errors.GROUP_COORDINATOR_NOT_AVAILABLE.code, Node.noNode)
}
}
...
}
- groupId hashcode % groupMetadataTopicPartitionCount(默认50),得到 __consumer_offset 分区 index
- 获取 index 分区的 leader 节点,此节点就是
Coordinator所在 node - 返回 node 信息
Client
// org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
// 获取 Coordinator 请求返回,回调 GroupCoordinatorResponseHandler
private class GroupCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received group coordinator response {}", resp);
GroupCoordinatorResponse groupCoordinatorResponse = new GroupCoordinatorResponse(resp.responseBody());
// use MAX_VALUE - node.id as the coordinator id to mimic separate connections
// for the coordinator in the underlying network client layer
// TODO: this needs to be better handled in KAFKA-1935
Errors error = Errors.forCode(groupCoordinatorResponse.errorCode());
clearFindCoordinatorFuture();
if (error == Errors.NONE) {
// 正常进入这里
synchronized (AbstractCoordinator.this) {
// 获取 Coordinator
AbstractCoordinator.this.coordinator = new Node(
Integer.MAX_VALUE - groupCoordinatorResponse.node().id(),
groupCoordinatorResponse.node().host(),
groupCoordinatorResponse.node().port());
log.info("Discovered coordinator {} for group {}.", coordinator, groupId);
client.tryConnect(coordinator);
// 心跳
heartbeat.resetTimeouts(time.milliseconds());
}
// 结束
future.complete(null);
...
}
joinGroup
// ensureActiveGroup();
// org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
void joinGroupIfNeeded() {
while (needRejoin() || rejoinIncomplete()) {
// 确认 Coordinator 已存在
ensureCoordinatorReady();
...
RequestFuture<ByteBuffer> future = initiateJoinGroup();
// 直到请求返回
client.poll(future);
resetJoinGroupFuture();
if (future.succeeded()) {
needsJoinPrepare = true;
onJoinComplete(generation.generationId, generation.memberId, generation.protocol, future.value());
}
...
}
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() {
if (joinFuture == null) {
...
state = MemberState.REBALANCING;
// 发送 joinGroup 请求
joinFuture = sendJoinGroupRequest();
joinFuture.addListener(new RequestFutureListener<ByteBuffer>() {
@Override
public void onSuccess(ByteBuffer value) {
// handle join completion in the callback so that the callback will be invoked
// even if the consumer is woken up before finishing the rebalance
synchronized (AbstractCoordinator.this) {
log.info("Successfully joined group {} with generation {}", groupId, generation.generationId);
// joingroup 返回响应后立即发送 syncgroup 请求
// syncgroup 请求返回,状态变为 stable
// SyncGroupResponseHandler
state = MemberState.STABLE;
if (heartbeatThread != null)
heartbeatThread.enable();
}
}
...
}
private RequestFuture<ByteBuffer> sendJoinGroupRequest() {
...
// send a join group request to the coordinator
log.info("(Re-)joining group {}", groupId);
JoinGroupRequest request = new JoinGroupRequest(
groupId,
this.sessionTimeoutMs,
this.rebalanceTimeoutMs,
this.generation.memberId, // memberId 为空
protocolType(),
metadata());
log.debug("Sending JoinGroup ({}) to coordinator {}", request, this.coordinator);
// ApiKeys.JOIN_GROUP,回调 new JoinGroupResponseHandler()
return client.send(coordinator, ApiKeys.JOIN_GROUP, request)
.compose(new JoinGroupResponseHandler());
}
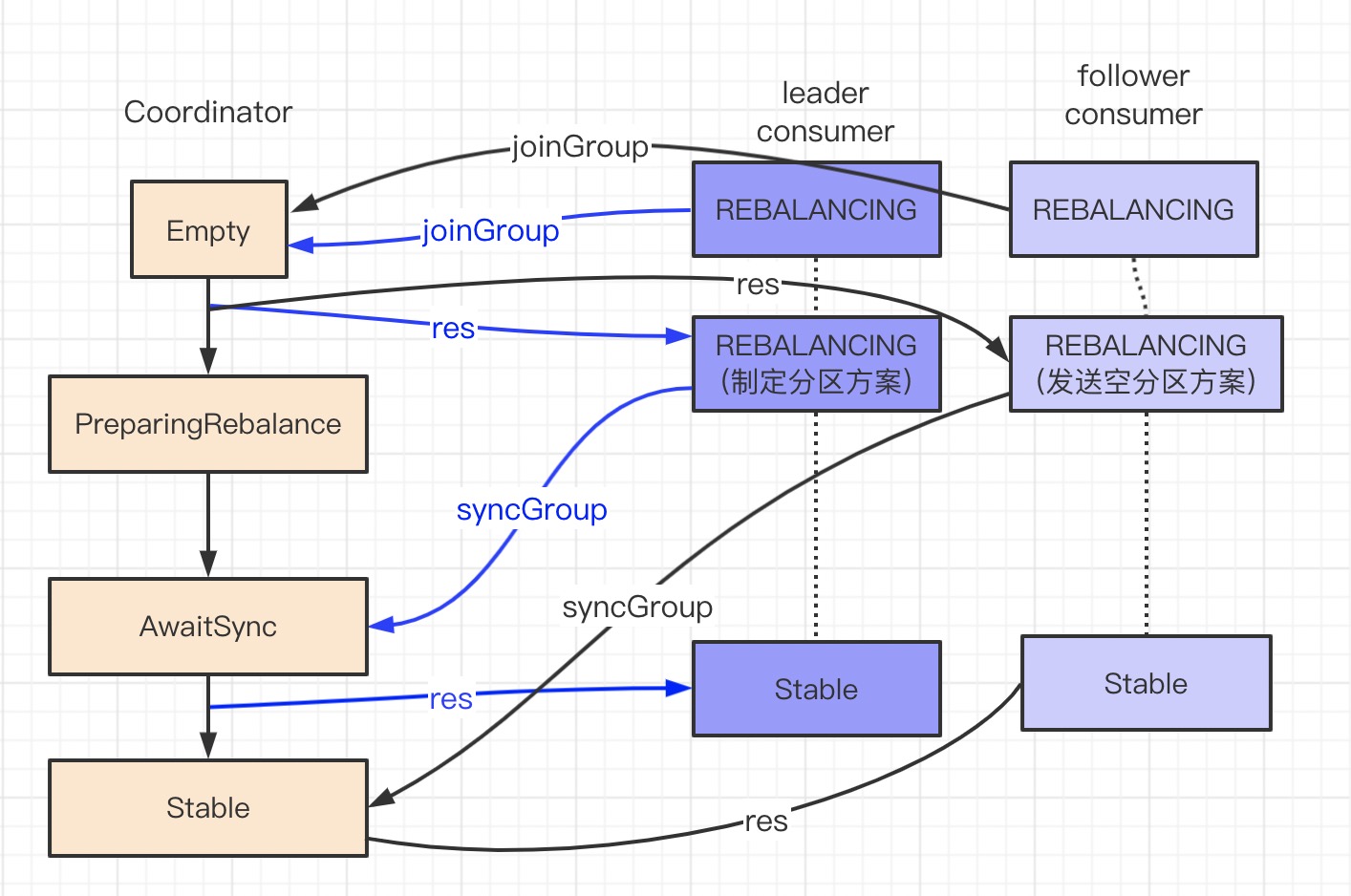
获取 Coordinator 后,向其发送 joinGroup 请求。
此时 consumer 的状态为 REBALANCING
Coordinator
// case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request)
// kafka.server.KafkaApis
def handleJoinGroupRequest(request: RequestChannel.Request) {
import JavaConversions._
val joinGroupRequest = request.body.asInstanceOf[JoinGroupRequest]
val responseHeader = new ResponseHeader(request.header.correlationId)
// joinGroup 回调
def sendResponseCallback(joinResult: JoinGroupResult) {
val members = joinResult.members map { case (memberId, metadataArray) => (memberId, ByteBuffer.wrap(metadataArray)) }
// 返回,附带 leaderID
val responseBody = new JoinGroupResponse(request.header.apiVersion, joinResult.errorCode, joinResult.generationId,
joinResult.subProtocol, joinResult.memberId, joinResult.leaderId, members)
trace("Sending join group response %s for correlation id %d to client %s."
.format(responseBody, request.header.correlationId, request.header.clientId))
requestChannel.sendResponse(new RequestChannel.Response(request, new ResponseSend(request.connectionId, responseHeader, responseBody)))
}
...
// 正常逻辑走这里
val protocols = joinGroupRequest.groupProtocols().map(protocol =>
(protocol.name, Utils.toArray(protocol.metadata))).toList
coordinator.handleJoinGroup(
joinGroupRequest.groupId,
joinGroupRequest.memberId,
request.header.clientId,
request.session.clientAddress.toString,
joinGroupRequest.rebalanceTimeout,
joinGroupRequest.sessionTimeout,
joinGroupRequest.protocolType,
protocols,
sendResponseCallback)
}
}
// kafka.coordinator.GroupCoordinator
def handleJoinGroup {
...
// 上面都是一些错误的情况
// 尝试获取当前 group 的 GroupMetadata
groupManager.getGroup(groupId) match {
case None =>
// memberId 不为空的情况,不应该再发送 joinGroup
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
// 若之前没有 GroupMetadata ,新建
val group = groupManager.addGroup(new GroupMetadata(groupId))
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
case Some(group) =>
// 若已存在 group,加入即可
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
}
}
private def doJoinGroup{
case PreparingRebalance =>
// 后面的 consumer 加入
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
case Empty | Stable =>
// 第一个 consumer 发送 joingroup
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
// memberId 为空,consumer 加入到 group,并赋予 memberId
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
...
}
private def addMemberAndRebalance {
// memberId = clientid_uuid()
val memberId = clientId + "-" + group.generateMemberIdSuffix
val member = new MemberMetadata(memberId, group.groupId, clientId, clientHost, rebalanceTimeoutMs,
sessionTimeoutMs, protocolType, protocols)
member.awaitingJoinCallback = callback
// 加入到 group,选择第一个加入的 consumer 为 consumer leader
group.add(member.memberId, member)
// group 状态切换为 PreparingRebalance
maybePrepareRebalance(group)
member
}
最开始 Coordinator 的状态是 Empty,当有一个 consumer 发送 joinGroup 时,状态转变为 PreparingRebalance。如果在一定时间内,接收到 join-group 请求的 consumer 将被认为是依然存活的,此时 group 会变为 AwaitSync 状态。
Client
private class JoinGroupResponseHandler{
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
...
// 发送 joingroup 时,state 切换为 REBALANCING
AbstractCoordinator.this.generation = new Generation(joinResponse.generationId(),
joinResponse.memberId(), joinResponse.groupProtocol());
AbstractCoordinator.this.rejoinNeeded = false;
if (joinResponse.isLeader()) {
// consumer leader,发送消费分区方案
onJoinLeader(joinResponse).chain(future);
} else {
// 此处也会发送 ApiKeys.SYNC_GROUP,但分区方案为空
onJoinFollower().chain(future);
}
...
}
}
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {
try {
// 制定分区方案
Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.leaderId(), joinResponse.groupProtocol(),
joinResponse.members());
SyncGroupRequest request = new SyncGroupRequest(groupId, generation.generationId, generation.memberId, groupAssignment);
log.debug("Sending leader SyncGroup for group {} to coordinator {}: {}", groupId, this.coordinator, request);
// 分区方案发送给 Coordinator
return sendSyncGroupRequest(request);
} catch (RuntimeException e) {
return RequestFuture.failure(e);
}
}
private RequestFuture<ByteBuffer> sendSyncGroupRequest(SyncGroupRequest request) {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
// ApiKeys.SYNC_GROUP, 回调 SyncGroupResponseHandler
return client.send(coordinator, ApiKeys.SYNC_GROUP, request)
.compose(new SyncGroupResponseHandler());
}
private class SyncGroupResponseHandler extends CoordinatorResponseHandler<SyncGroupResponse, ByteBuffer> {
public void handle {
if (error == Errors.NONE) {
// syncgroup 请求返回成功
// future.complete 回调(initiateJoinGroup),状态切换为stable
future.complete(syncResponse.memberAssignment());
}
}
broker
// case ApiKeys.SYNC_GROUP => handleSyncGroupRequest(request)
def handleSyncGroupRequest(request: RequestChannel.Request) {
import JavaConversions._
val syncGroupRequest = request.body.asInstanceOf[SyncGroupRequest]
// 回调
...
if (!authorize(request.session, Read, new Resource(Group, syncGroupRequest.groupId()))) {
sendResponseCallback(Array[Byte](), Errors.GROUP_AUTHORIZATION_FAILED.code)
} else {
coordinator.handleSyncGroup(
syncGroupRequest.groupId(),
syncGroupRequest.generationId(),
syncGroupRequest.memberId(),
syncGroupRequest.groupAssignment().mapValues(Utils.toArray(_)),
sendResponseCallback
)
}
}
def handleSyncGroup {
...
// 以上错误情况
groupManager.getGroup(groupId) match {
case None => responseCallback(Array.empty, Errors.UNKNOWN_MEMBER_ID.code)
case Some(group) => doSyncGroup(group, generation, memberId, groupAssignment, responseCallback)
}
}
}
private def doSyncGroup {
var delayedGroupStore: Option[DelayedStore] = None
group synchronized {
// 以上错误情况
group.currentState match {
// 以上错误情况
case AwaitingSync =>
// 当 coordintor 收到 joingroup 并在一段时间后确认 consum 存活后转为 AwaitingSync
group.get(memberId).awaitingSyncCallback = responseCallback
if (memberId == group.leaderId) {
// leader consumer 发送 syncgroup
info(s"Assignment received from leader for group ${group.groupId} for generation ${group.generationId}")
// 当消费者个数大于分区主题分区数,注定有些消费者无法消费数据
// 以 空填补 assignment
val missing = group.allMembers -- groupAssignment.keySet
val assignment = groupAssignment ++ missing.map(_ -> Array.empty[Byte]).toMap
delayedGroupStore = groupManager.prepareStoreGroup(group, assignment, (error: Errors) => {
group synchronized {
// another member may have joined the group while we were awaiting this callback,
// so we must ensure we are still in the AwaitingSync state and the same generation
// when it gets invoked. if we have transitioned to another state, then do nothing
if (group.is(AwaitingSync) && generationId == group.generationId) {
if (error != Errors.NONE) {
resetAndPropagateAssignmentError(group, error)
maybePrepareRebalance(group)
} else {
// 保存 leader 发送的 消费分区方案
setAndPropagateAssignment(group, assignment)
// coordinator 状态切换为 stable
group.transitionTo(Stable)
}
}
}
})
}
case Stable =>
// 如果后续再有 follower 发送 syncgroup 请求
// 且此时 coordinator 已经是 stable,直接返回消费分区方案
val memberMetadata = group.get(memberId)
responseCallback(memberMetadata.assignment, Errors.NONE.code)
completeAndScheduleNextHeartbeatExpiration(group, group.get(memberId))
}
}
}
Coordinator 收到 leader consumer 发送的 syncGroup 请求,保存消费分区方案,并将状态转化为 Stable。
在梳理流程之前,先看看 consumer 和 coordinator 的状态变化。
offset
到此 consumer 可以开始真正的消费数据了。
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
...
// 处理拉取到的数据,completedFetches
// 消费数据并存储 offset
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty())
return records;
// 拉取数据请求,与副本数据同步相同,发送 ApiKeys.FETCH
// 拉取到的数据存放到 completedFetches
fetcher.sendFetches();
}
消费数据后,要提交 offset,保存到 __consumer_offset。
// maybeAutoCommitOffsetsAsync(now);
// org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
private void maybeAutoCommitOffsetsAsync(long now) {
if (autoCommitEnabled) {
if (coordinatorUnknown()) {
this.nextAutoCommitDeadline = now + retryBackoffMs;
} else if (now >= nextAutoCommitDeadline) {
// autoCommitIntervalMs 默认 5s
this.nextAutoCommitDeadline = now + autoCommitIntervalMs;
doAutoCommitOffsetsAsync();
}
}
}
private void doAutoCommitOffsetsAsync() {
//
commitOffsetsAsync(subscriptions.allConsumed(), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null) {
log.warn("Auto offset commit failed for group {}: {}", groupId, exception.getMessage());
if (exception instanceof RetriableException)
nextAutoCommitDeadline = Math.min(time.milliseconds() + retryBackoffMs, nextAutoCommitDeadline);
} else {
log.debug("Completed autocommit of offsets {} for group {}", offsets, groupId);
}
}
});
}
public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
// 测试输出
invokeCompletedOffsetCommitCallbacks();
if (!coordinatorUnknown()) {
// 提交
doCommitOffsetsAsync(offsets, callback);
...
}
private void doCommitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) {
this.subscriptions.needRefreshCommits();
// 封装 offset 请求 ApiKeys.OFFSET_COMMIT,回调 OffsetCommitResponseHandler
// OffsetCommitResponseHandler 修改最后提交 offset
RequestFuture<Void> future = sendOffsetCommitRequest(offsets);
...
}
consumer 有两个 offset:
- position:消费到数据的 offset
- committed:已提交到 kafka 的消费 offset