https://azkaban.readthedocs.io/en/latest/getStarted.html#
安装
https://azkaban.readthedocs.io/en/latest/getStarted.html#building-from-source
参考上面官方文档,下载编译安装即可。
在启动之前,先配个用户:
<!-- conf/azkaban-users.xml -->
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<!-- 新增 danner 用户,角色为 admin -->
<user password="123456" roles="admin" username="danner"/>
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
执行 bin/start-solo.sh 启动,会有 AzkabanSingleServer 进程,默认是在 8081 端口
上图蓝色框图内的文字和端口都可以在 conf/azkaban.properties 文件中配置
...
# 时区配置成上海
default.timezone.id=Asia/Shanghai
...
案例
https://azkaban.readthedocs.io/en/latest/useAzkaban.html
按上面文档创建一个项目
https://azkaban.readthedocs.io/en/latest/createFlows.html
按照上面的官方文档配置,上传 Flow 即可执行。下面通过几个小案例来熟悉
Hello Azkaban
创建一个文件夹,包含两个文件,层级如下
hello_azkaban
-- flow20.project // 文件名固定
-- basic.flow // 以 flow 后缀名,yaml 格式
flow20.project : 只写 azkaban-flow-version 版本号
azkaban-flow-version: 2.0
basic.flow: 任务的内容和依赖
nodes:
- name: jobA
type: command
config:
command: echo "hello azkaban ..."
将 hello_azkaban 文件夹打包成 zip 格式,点击 Upload 按钮上传
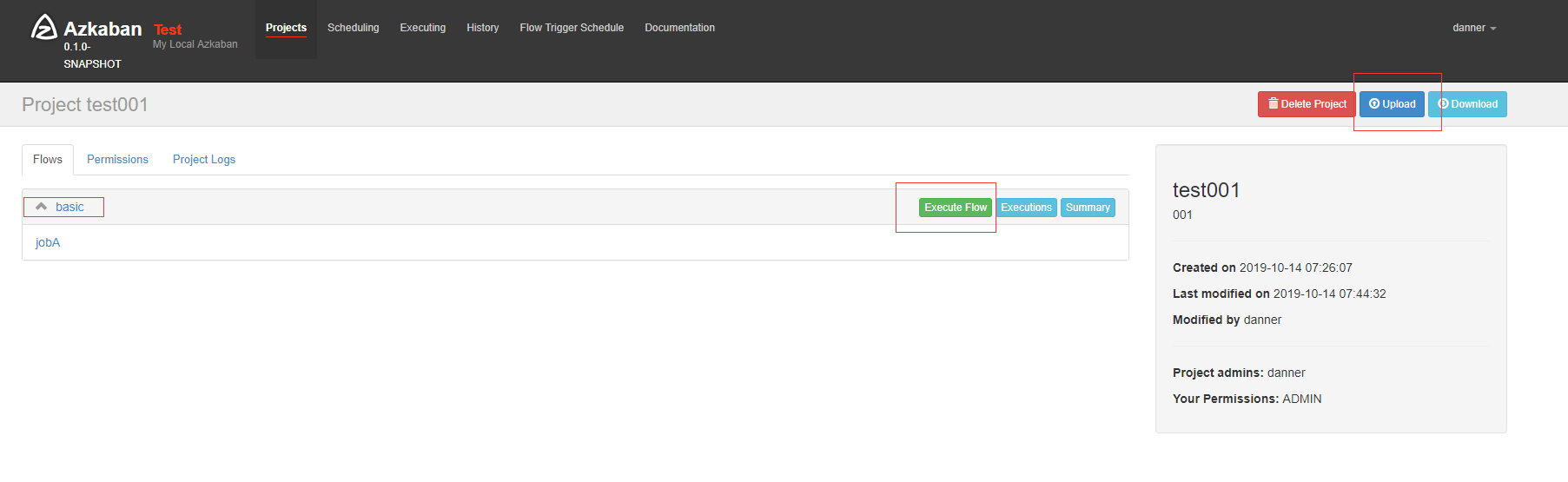
点击 Execute Flow 去执行,执行过程和结果被展示
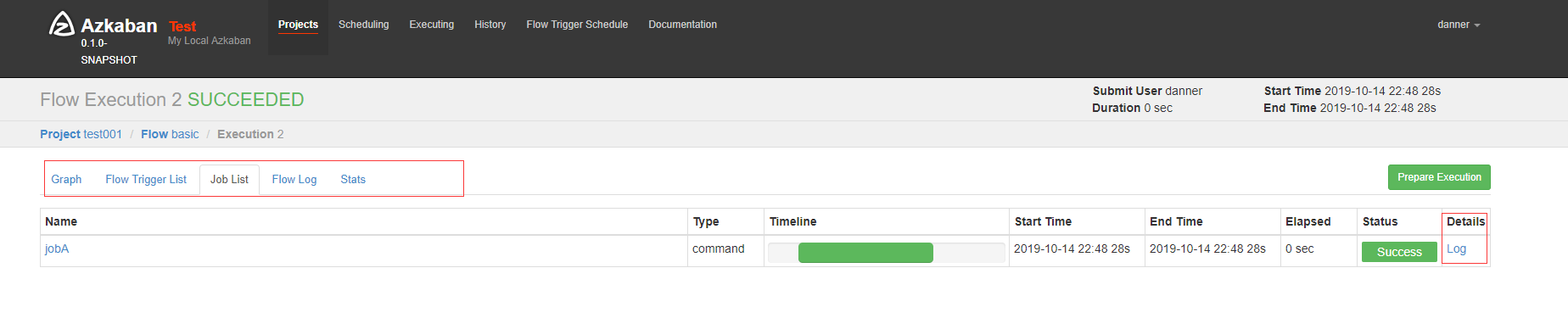
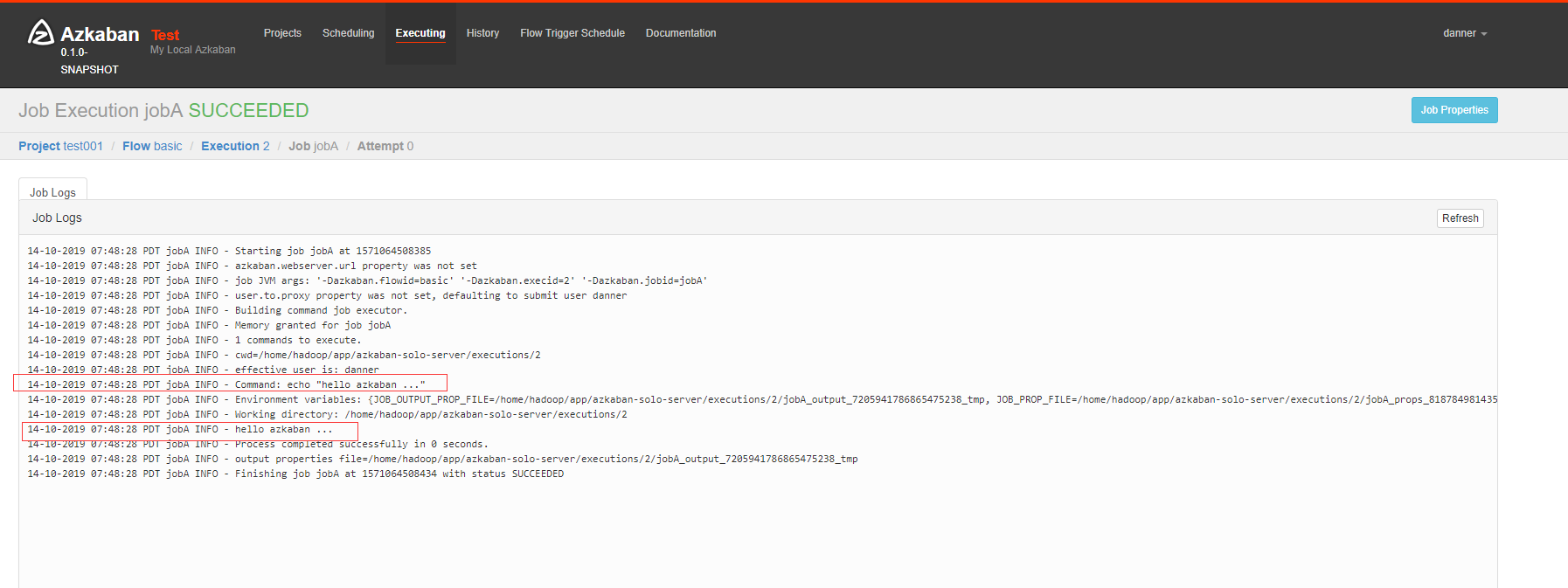
点击 Log 查看
Dependency
上面的案例只是单独任务,若任务之间存在依赖该如何配置呢:flow20.project 内容不变,主要是 basic.flow
nodes:
- name: jobC
type: noop
# jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB
- name: jobA
type: command
config:
command: echo "This is an echoed text."
- name: jobB
type: command
config:
command: pwd
jobC 依赖 jobA 和 jobB,打包上传后在 UI 上看看是如何体现

看任务的执行:jobA 和 jobB 同时执行,但jobC 是在前两个任务都执行完后才执行

MR
如果任务是 MR 该如何配置呢,很简单只是一条命令即可
nodes:
- name: MR
type: command
config:
command: /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin/hadoop jar /home/hadoop/lib/hadoop/G7-41-dwt.jar com.danner.bigdata.hadoop.homework.ETLApp /project/hadoop/access/log/20190917 /project/hadoop/access/out/20190917 /tmp/data/ip.txt
注意:命令和 jar 要写绝对路径
Hive
Hive 也可以用命令或者 shell 搞定,但这里我换一种方式
https://azkaban.readthedocs.io/en/latest/jobTypes.html#hive-type == >
New Hive Jobtype
这里需要注意,像 hive、spark、pig 这种类型是需要插件支持的,所以要先编译插件
- 参考资料三编译插件,需单独编译(插件是放在
azkaban/plugins下,默认无插件) - 配置好 环境变量 和
classpath
运行环境配置好后,跟之前一眼还是写配置
hive
-- flow20.project
-- basic.flow
-- hive.shell
# basic.flow
nodes:
- name: Hive
# hive 这个 type 要插件支持且与 azkaban/plugins/jobtypes 目录下的名称一致
type: hive
config:
hive.script: hive.shell
# hive.shell
# sql 即可;类似在 hive 终端执行
select * from danner_db.platform_stat;