核心术语
- Producer:生产者,生产中常为
flume - Consumer:消费者,生产中常为
ss/sss/flink/- 容错性的消费机制:
- 一个消费组内共享一个公共的消费 group id;
- 组内所有的消费者协调在一起消费指定 Topic 的所有分区;
- 每个分区只能由一个消费组的一个消费者来消费,绝不会出现一个分区被同一个消费组的不同消费者进行重复消费
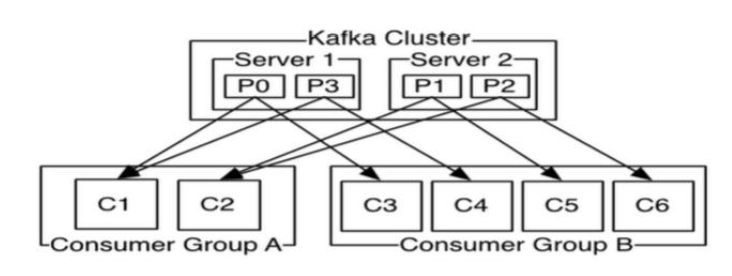
- 容错性的消费机制:
- Broker:消息处理节点(
kafka集群节点) - Controller:集群中的
broker选举出一个broker作为 Controller 节点- 负责整个集群的管理: broker 管理,topic 管理,Partition Leader 管理
- 选举方式是成功在
zookeeper创建节点,与NameNode一致
- Leader:副本管理
- Controller 在同个分区的几个副本节点中选取出一个 Leader,其他为 Follower
- Follower 从 Leader 中同步数据
- Leader 跟踪保持同步
Isr(In Sync Replica)==> 副本节点
- Topic:消息主题,数据记录发布的地方
- Partition:
topic物理上的分组- 一个
topic可以指定多个分区,提高并行度; - 每个分区是一个有序队列,其实就是一个文件夹/目录
- 分区命名规则为 主题名-序号,比如
test-0,test-1,test-2
- 一个
- Segment:分段
- 一个分区可以被切割为多个相同大小的
segment - 分区全局的第一个
segment必然是从0开始,后续的segment名称为上一个segment的最后一个消息的 offset 来标识 segment的切割由log.segment.bytes来决定
- 一个分区可以被切割为多个相同大小的
- replication-factor:副本数
- 分区会指定复制几份,与
HDFS的block副本数类似,提高容错性,常用为 3
- 分区会指定复制几份,与
存储
创建主题:指定三个分区且副本数为2
[hadoop@izbp1cyvm0mbu85rgyqrizz bin]$ ./kafka-topics.sh --create --zookeeper danner002:2181/kafka --replication-factor 2 --partitions 3 --topic test
Created topic test.
分区
[hadoop@izbp1cyvm0mbu85rgyqrizz bin]$ ./kafka-topics.sh --describe --zookeeper danner002:2181/kafka --topic test
Topic:test PartitionCount:3 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test Partition: 2 Leader: 0 Replicas: 0,1 Isr: 0,1
test 主题有三个分区,表现形式就是在 节点0 机器有 test-2 目录,节点1有 test-0 目录,节点2 有 test-1 目录
# broker 1 机器数据
[hadoop@izbp1cyvm0mbu85rgyqrizz log]$ cd kafka-logs/
[hadoop@izbp1cyvm0mbu85rgyqrizz kafka-logs]$ ll
total 24
-rw-rw-r-- 1 hadoop hadoop 0 Oct 23 11:30 cleaner-offset-checkpoint
-rw-rw-r-- 1 hadoop hadoop 4 Oct 23 14:45 log-start-offset-checkpoint
-rw-rw-r-- 1 hadoop hadoop 54 Oct 23 11:30 meta.properties
-rw-rw-r-- 1 hadoop hadoop 22 Oct 23 14:45 recovery-point-offset-checkpoint
-rw-rw-r-- 1 hadoop hadoop 22 Oct 23 14:45 replication-offset-checkpoint
drwxrwxr-x 2 hadoop hadoop 4096 Oct 23 14:44 test-0
drwxrwxr-x 2 hadoop hadoop 4096 Oct 23 14:44 test-2
副本
[hadoop@izbp1cyvm0mbu85rgyqrizz bin]$ ./kafka-topics.sh --describe --zookeeper danner002:2181/kafka --topic test
Topic:test PartitionCount:3 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 1 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test Partition: 2 Leader: 0 Replicas: 0,1 Isr: 0,1
每个分区有两个副本且有一个为 Leader,以分区0为例,副本存放的 broker 为 1和 2,broker 0为 Leader 。
分区数一般为 broker 数量,副本数 <= 3
index 文件
每个 segment 都文件如下
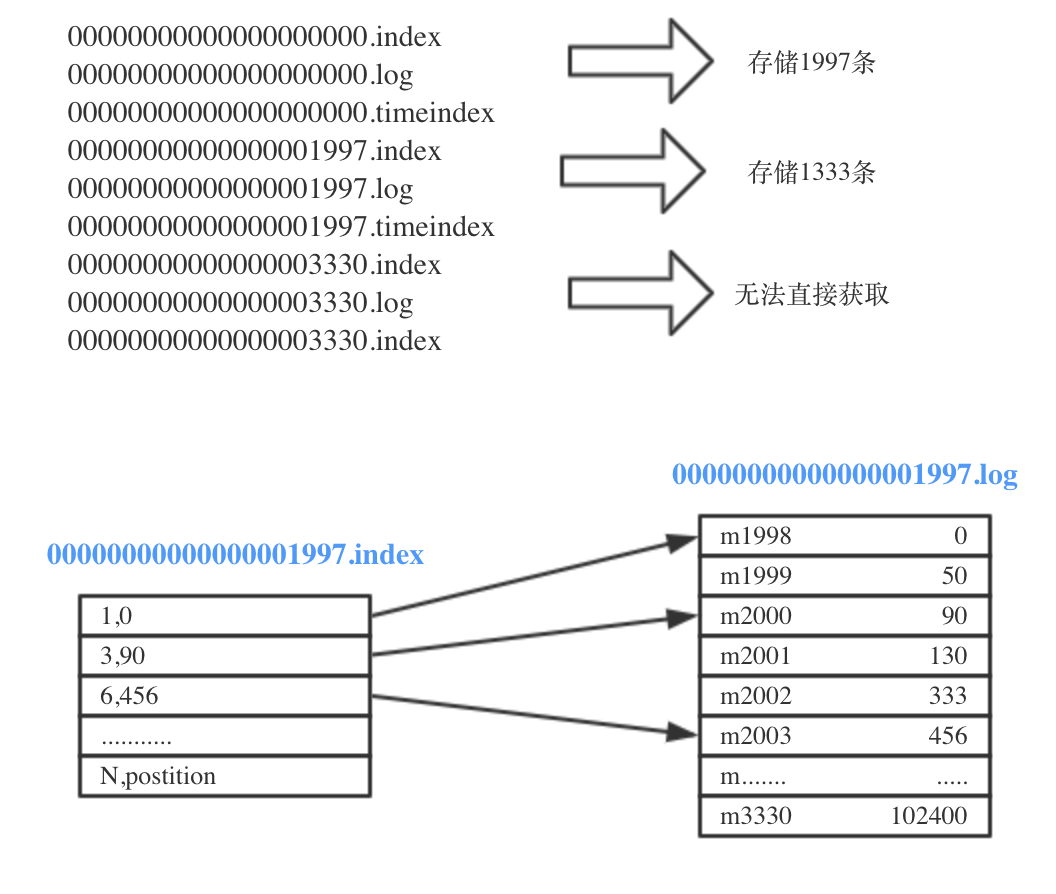
偏移量索引文件
- 存储相对 offset,分区内每个 segment 的 log 唯一 (从1 开始)
- 物理地址,消息在 log文件的物理地址 byte ;
3,90指该segment 的第六条消息在文件的偏移地址为 90 - 稀疏表维护:并不是每一条消息的的相对 offset 和物理地址都维护;上图2、4、5就没维护
log 文件
存储消息
kafka 是如何找到 offset 为 2002 的消息
- 二分查找到 <= 2002 的最大 segment 文件,本例中为 1997
- 确定好segment 文件后,计算相对 offset = 2002 - 1997 = 5
- 在
1997.index中二分查找 <= 5 的offset,本例中为 3,对应偏移量为 90 - 从
1997.log的 90 位置开始,直至找到 绝对 offset 为2002 的消息m2002
交付语义
消息传递机制有以下几种
- At most once: Messages may be lost but are never redelivered( 最多一次 0-1 )
- At least once: Messages are never lost but may be redelivered ( 最少一次 >= 1 )
- Exactly once: this is what people actually want, each message is delivered once and only once ( 精准消费,只做一次)
在 Apache kafka 0.11 版本开始,可以保证生成者的精准一次(幂等性),那么我们只需要保证消费语义的精准一次即可。
消费语义
在实际生产案例中,kafka 下游是 SS。那么我们就需要保证 kafka+SS 精准一次消费语义,Spark 官方提供三种方式
- Checkpoints :
kafka消息偏移记录到 checkpoint ;这种方式会有几个问题:必须保证消息处理和偏移记录的事务性(相当于是为解决一个问题而产生新的问题);checkpoint 会产生小文件 - Kafka itself:
kafka自身可以记录消费偏移值,此种方式是至少一次消费语义,需要搭配下游才能实现精致一次。官方推荐和生产中大部分情况下适用 - Your own data store:自己处理偏移量,但要支持事务性,这可以实现精准一次消费,但自己实现代码有点复杂的哦。
在实际生产案例中,大多数是使用 kafka itself 方式,下游紧跟 upset ( 有数据就 update )语法保证数据不重复从而实现幂等性。
分区选择
kafka 如何为消息指定分区呢?
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
- 有 key 则直接对 key 做 hash 并取模
- 无 key 则去获取当前主题的消息数并加1 当作key,然后再对 key 做hash 取模
由上可知,传递消息时还是加上 key 比较好,这样在确定分区时可以节省时间
局部有序
在实际案例中有这么一种需求:用户的行为产生一系列消息后存入 kafka ,下游处理时必须按时间顺序来处理。这里涉及到的是 kafka 分区问题:只保证分区内的消息有序,不保证消息全局有序。
一个简单的想法:此主题只设置一个分区,那么分区内有序也就保证了此主题的全局有序。这种方式问题是解决了,但只有一个分区违背多分区原则并不是最优解。
其实解决方案也简单,还是利用分区内消息有序和分区选择:将同个用户的行为消息 key 都设置为相同,由分区选择可知,相同key 存储到相同的分区,那么同个用户的消息就是全局有序了。
优化
Producer
acks: all
buffer.memory: 536870912
compression.type :snappy
# 数据只写 1次,若失败重复 100次,保证数据不会多写
retries: 100
max.in.flight.requests.per.connection = 1
# 字节,不是条数
batch.size: 10240
max.request.size = 2097152
# 大于 replica.lag.time.max.ms
request.timeout.ms = 360000
metadata.fetch.timeout.ms= 360000
timeout.ms = 360000
linger.ms 5s (生产不用)
max.block.ms 1800000
kafka 消息是存在本地磁盘,所有 producer 在发送消息时不是一条一条写数据而是按批次。
- batch.size:定义每个分区批次大小,超过阈值后整个批次落盘
- buffer.memory:一个 producer 的缓存大小,包含所有分区
- max.request.size:每次发送最大字节数
- linger.ms:间隔多长时间,buffer 数据落盘
- acks:producer 发送信息到 broker 的反馈,kafka 自己内部实现,发送失败会重试 (
retries)- 0:producer 只管发送
- 1:Leader 落盘才算是发送成功,不管 follower 同步,默认设置
- 2 or all:follower 同步成功才算发送成功
producer 消息落盘条件:batch.size or linger.ms;kafka 数据不丢失:多副本的情况下,acks=all
Consumer
# https://issues.apache.org/jira/browse/SPARK-22968
# 默认 1048576
max.partition.fetch.bytes = 5242880
# 默认 60000
request.timeout.ms = 90000
# 默认 30000
session.timeout.ms = 60000
heartbeat.interval.ms = 5000
receive.buffer.bytes = 10485760
分区分配策略
以下的消费者都是指同个消费者组
RangeAssignor:默认设置- 首先分区按数字排序,消费者按字典排序
- 分区数/消费者 能整除,按照排序依次分配即可;若无法整除,则排前面的消费者多消费一个
- 案例:消费者 C0,C1,topic t0,t1且每个topic 有三个分区,最终分配如下
- C0: [t0p0, t0p1, t1p0, t1p1]
- C1: [t0p2, t1p2]
- 显然这种方式会导致分配不均匀,C0 消费者压力大
RoundRobinAssignor:- 消费者按字典排序,分区按数字排序
- 所有分区(包含不同topic) 尽可能的均匀分配消费组
- 案例1:消费者 C0,C1,topic t0,t1且每个topic 有三个分区,此时分区有 t0p0, t0p1, t0p2, t1p0, t1p1, and t1p2,分配如下,显然是优于第一种方式
- C0: [t0p0, t0p2, t1p1]
- C1: [t0p1, t1p0, t1p2]
- 案例2:消费者数,主题数和分区数都为3,但只消费 t0p0, t1p0, t1p1, t2p0,t2p1, t2p2,且C0 只消费t0,C1消费 t0,t1,C2消费 t0,t1,t2;结果分配如下
- C0: [t0p0]
- C1: [t1p0]
- C2: [t1p1, t2p0, t2p1, t2p2]
StickyAssignor:经可能的均匀(在有消费者下线时,只是把下线消费者的分区重分配,而不是整体重新分配),在0.11版本才出现;不熟悉或者没有特殊需求,就用这个
Broker
# CDH 版本
# 1条消息的大小
message.max.bytes 2560KB
zookeeper.session.timeout.ms 180000
# 大于 message.max.bytes
replica.fetch.max.bytes 5M
num.replica.fetchers 6
replica.lag.max.messages 6000
replica.lag.time.max.ms 15000
log.flush.interval.messages 10000
log.flush.interval.ms 5s
超时时间可以稍微调大一点
max.request.size和max.partition.fetch.bytes可以调大一点
message.max.bytes<=replica.fetch.max.bytes
监控
在 CDH 环境,配置 SQL 监控 Kafka 接收和处理数据
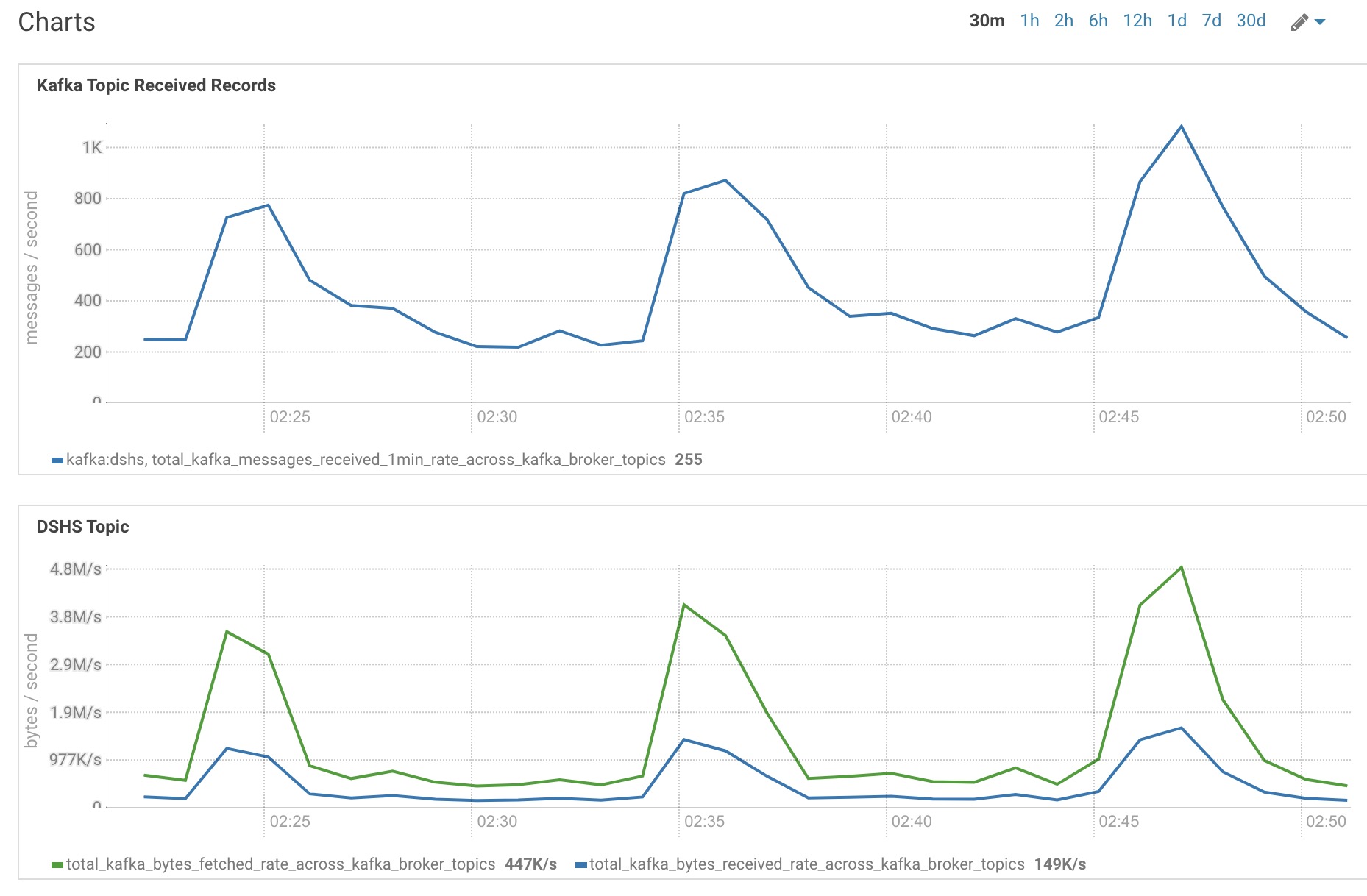
上图就是运行正常的 kafka 监控图,包含以下信息
- 读写趋势一致
- 读写数据量时间点吻合,读数据量比写大是因为读取时除了消息本身还有 header ( 时间,分区 … )
以上信息说明 kafka 消费及时,没有延迟,kafka 没有压力。
故障案例
以下都是 CDH 环境下
案例一
kafka 把磁盘撑爆了
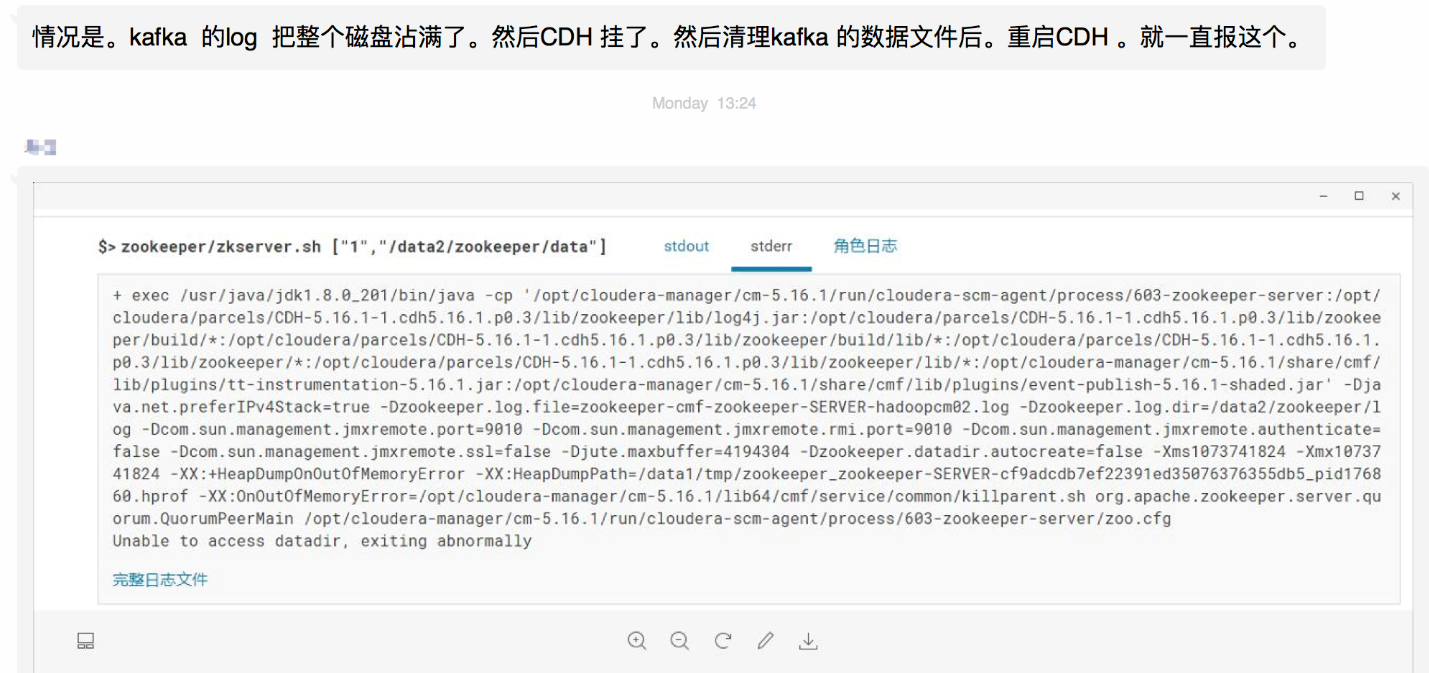
排查结果是有个 zk 文件被损坏了。
复盘:预警真的很重要,一定要设置预警。
案例二
集群正常工作中,突然断电了。集群重新启动后,kafka 状态是绿色(正常),但发现 生产者和消费者都无法正常工作。
修复过程:
- 停止服务
- 删除
kafka并重新安装 - 重新刷数据,从断电前2个小时的数据开始刷
总结
生产案例架构:
flume/maxwell ==> kafka ==> ss/flink
kafka 作为消息中间件,提供实时的读写特性;面对上游的数据高峰期间,kafka 能起到缓冲作用,避免下游的数据同步和计算压力的井喷,导致夯住!当然下游的流处理系统要有反压机制,保证整个系统能稳稳的消费。整个数据处理流程中一定要牢牢遵循
要么一起成功 要么一起失败