Spark 是基于内存的分布式计算引擎,很显然其内存管理是很重要的。在整个Spark 作业中,涉及到 Driver 端和 Executor 端。Driver 端的内存管理与普通JVM 进程差别不大,详情看下图。
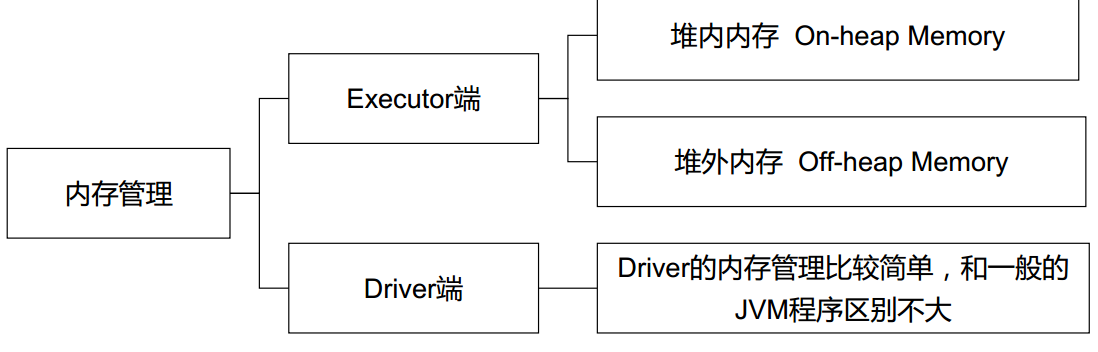
本文具体来看看 Executor 端的内存管理。在详细分析之前,先看看Spark 作业提交时有关的参数设置
| 参数 | 描述 |
|---|---|
| executor-memory MEM | Memory per executor (e.g. 1000M, 2G) (Default: 1G) |
| driver-memory MEM | Memory for driver (e.g. 1000M, 2G) (Default: 1024M) |
| executor-cores NUM | Number of cores per executor. (Default: 1 in YARN mode, or all available cores on the worker in standalone mode) |
| num-executors NUM | Number of executors to launch (Default: 2). If dynamic allocation is enabled, the initial number of executors will be at least NUM. |
Spark 作业默认是启动 2个 Executor ,每个 Executor 启动1个Core,且Executor 默认是1G,Driver 默认也是 1G。下文涉及到的 Executor 端内存计算都是在 1G 内存的基础上展开。
内存管理
Spark 为执行内存和存储内存的管理提供了统一的接口 MemoryManager。执行内存:计算时需要的内存(shuffle、joins、sorts、agg);存储内存:cache 和广播变量。由于历史版本原因,Spark 有StaticMemoryManager 和 UnifiedMemoryManager都是实现接口。
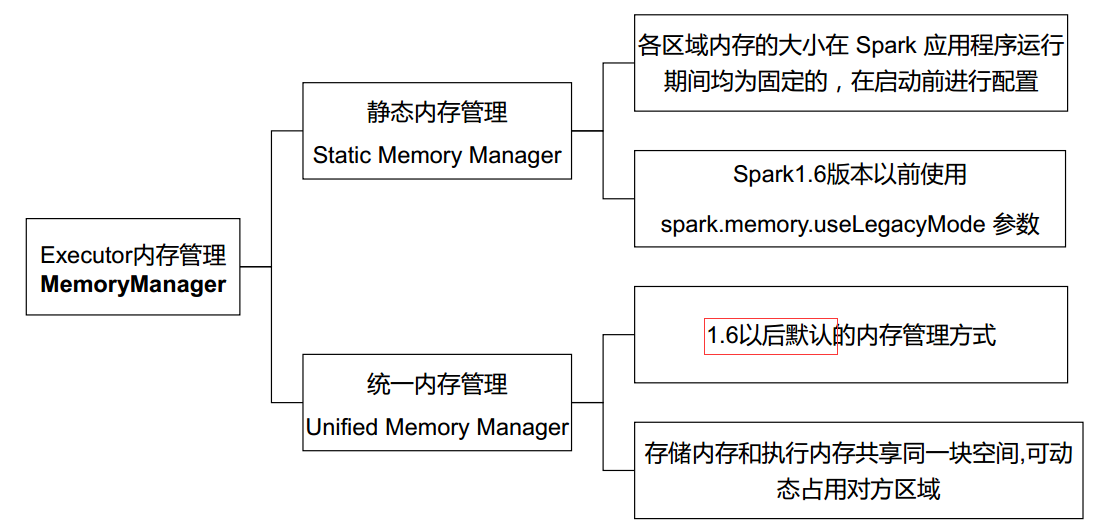
由此可见,1.6 版本前后内存管理的方式不同的,在源码中有可以体现。
// org.apache.spark.SparkEnv.create()
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
下面从执行内存和存储内存两个方面来分析 StaticMemoryManager 和 UnifiedMemoryManager 不同
StaticMemoryManager
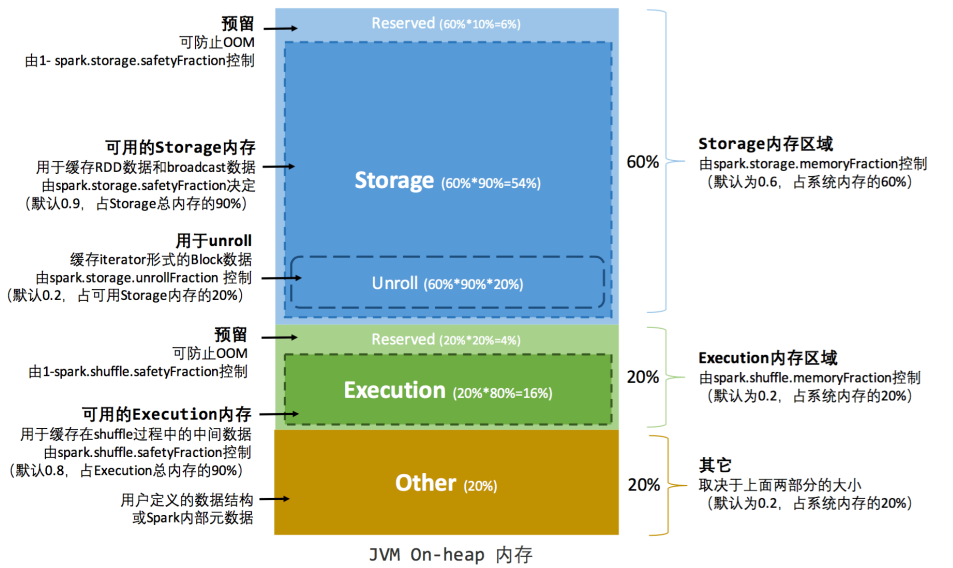
static 表示执行内存和存储内存分配之后就固定了,在总内存 1G 基础上看看内存是如何分配的。
// StaticMemoryManager
// 存储内存大小计算
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
private val maxUnrollMemory: Long = {
(maxOnHeapStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}
// 执行内存大小计算
private def getMaxExecutionMemory(conf: SparkConf): Long = {
// executor 内存必须大于 32M
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
...
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
- 执行内存:
1G * 0.2=200Mspark.shuffle.memoryFraction:控制执行内存与总内存的占比- Executor :
200 M * 0.8=160M;spark.shuffle.safetyFraction控制执行内存中可用内存的占比 - Reserved:
200M *(1 - 0.8)=40M,防止OOM
- 存储内存:
1G * 0.6=600Mspark.storage.memoryFraction:控制存储内存与总内存占比- Storage:
600 M * 0.9=540 M;spark.storage.safetyFraction控制存储内存中可用内存的占比UnrollMemory:540 M * 0.2=108 M
- Reserved:
600M *(1 - 0.9)=60M,防止OOM
- Other :
1G * 0.2=200 M- 用户定义的数据结构或 Spark 内部元数据
由此可见,在 static 模式下,存储内存占大头,执行内存只占20%,一不小心就会 OOM 哦。详细的内存看下图
UnifiedMemoryManager
Unified 是存储和执行内存先按比例分配,运行过程中可以共享。
// UnifiedMemoryManager
private def getMaxMemory(conf: SparkConf): Long = {
// (max*0.91- 300M) * 0.6
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else 300 M)
...
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
(usableMemory * memoryFraction).toLong
}
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
// onHeapStorageRegionSize = maxMemory*0.5 = (max - 300M) * 0.6 *0.5 = (max - 300M) * 0.3
// onHeapExecutionMemory = maxMemory - onHeapStorageRegionSize = (max - 300M) * 0.3
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
onHeapStorageRegionSize =
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,
numCores = numCores)
}
Reserved:300 Mspark.testing.reservedMemory- 保障留出足够的空间
Other:(1G - 300 M) * (1 - 0.6)=280 Mspark.memory.fraction- 用户定义的数据结构或 Spark 内部元数据
- 存储内存:
(1G - 300 M) * 0.6 * 0.5=210 Mspark.memory.storageFraction:控制存储内存与可用内存占比
- 执行内存:
(1G - 300 M) * 0.6 - 210 M=210 M
很显然在 Unified 模式下,执行内存对存储内存的占比大幅度提升(1:3 升到 1:1),详情看下图。
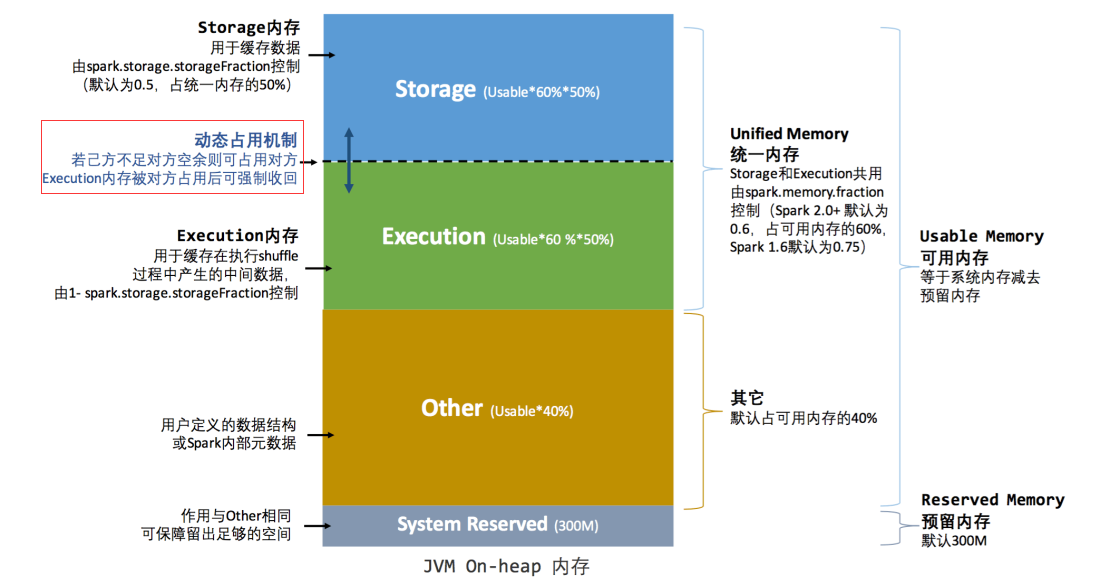
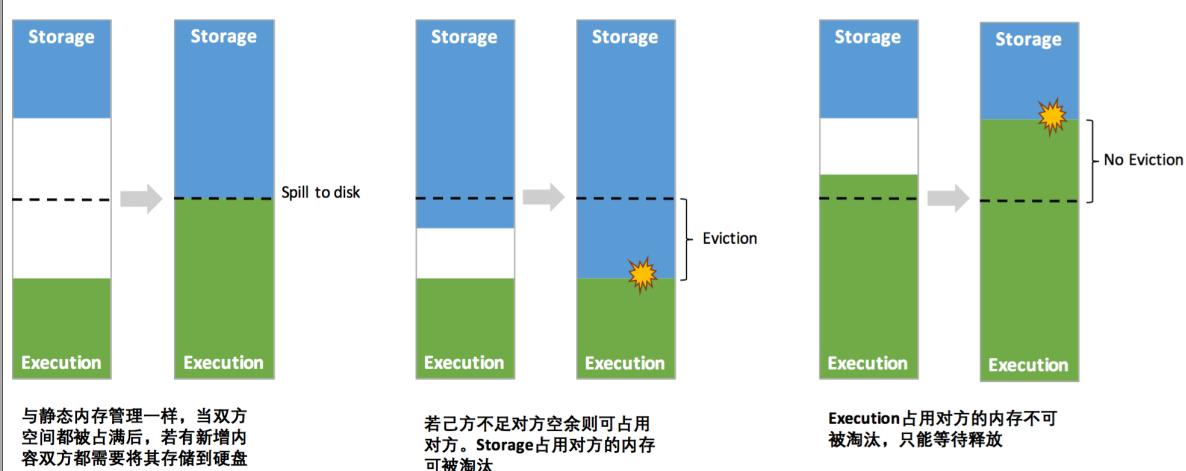
Unified 模式还有个特性是存储内存或执行内存不够时,可以占用对方内存。
- Execution 内存和 Storage 内存可以相互借用
- Execution 内存不够且被Storage 占用了内存的情况下, Storage 占用对方内存会自动淘汰,空出内存还给Execution 使用
- Storage 内存不够且被Execution 占用了内存的情况下,那只能等待Execution 释放被占用的内存才能使用(Spark 中计算比缓存重要多,计算出错整个作业就挂了)。