https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
窗口函数
来两个小需求来介绍窗口函数强大的功能
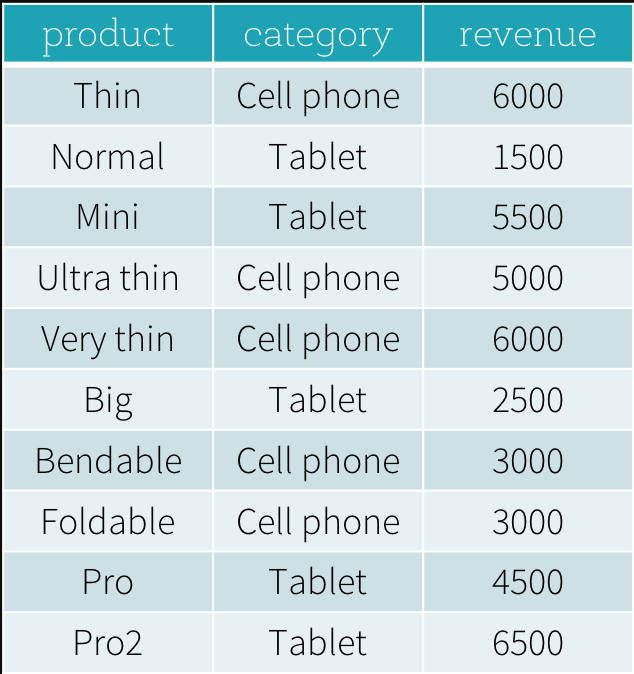
- 求每个标签下,收入排行最高和第二高
- 求每个标签下,每个产品与收入最高的产品的收入差距
需求一
实际需求就是分组排序(注意不是求 TopN,所以这里用 dense_rank),需要分组排序然后对 index <= 2 过滤
SELECT
product,
category,
revenue
FROM (
SELECT
product,
category,
revenue,
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank
FROM productRevenue) tmp
WHERE
rank <= 2
dense_rank() OVER 简单解决分组排序问题,再做过滤即可解决
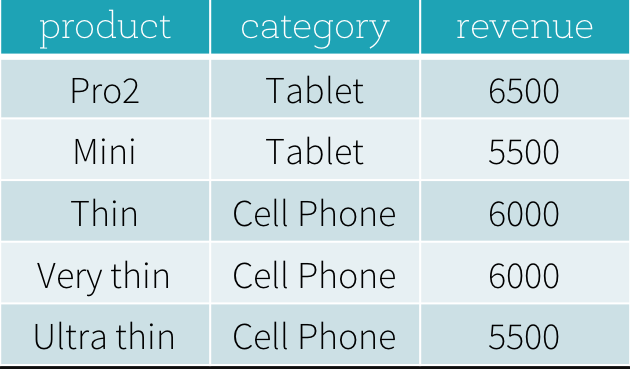
需求二
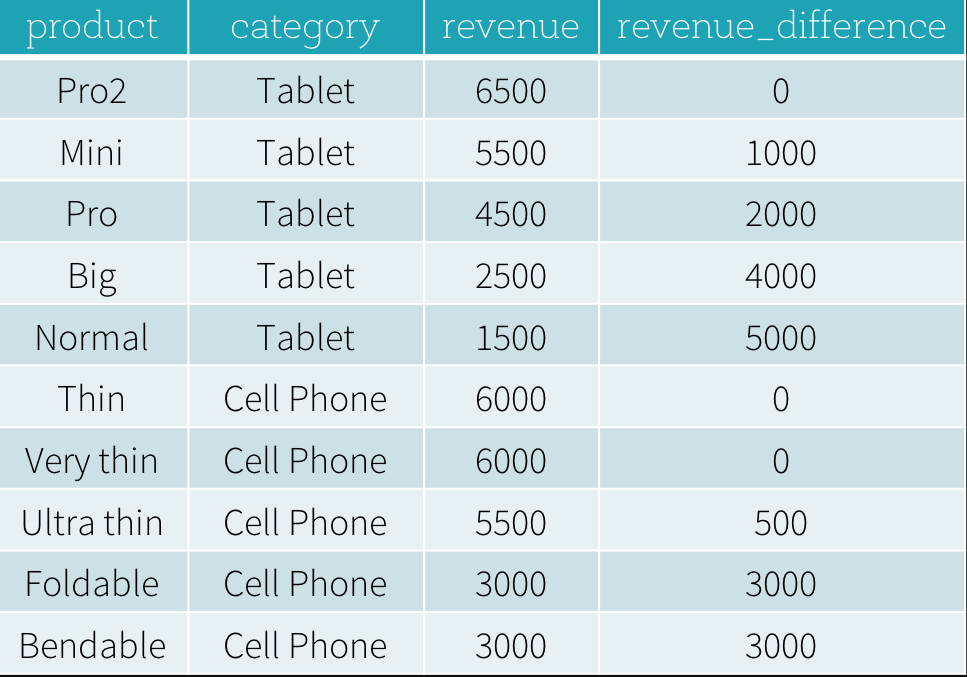
先求标签分组下收入最高,然后最高组内收入相减
# python
import sys
from pyspark.sql.window import Window
import pyspark.sql.functions as func
windowSpec =
Window
.partitionBy(df['category'])
.orderBy(df['revenue'].desc())
.rangeBetween(-sys.maxsize, sys.maxsize)
dataFrame = sqlContext.table("productRevenue")
revenue_difference =
(func.max(dataFrame['revenue']).over(windowSpec) - dataFrame['revenue'])
dataFrame.select(
dataFrame['product'],
dataFrame['category'],
dataFrame['revenue'],
revenue_difference.alias("revenue_difference"))
使用窗口函数
Spark SQL 窗口函数大致可以分为三类:排行函数、分析函数、聚合函数。
| SQL | DataFrame API | |
|---|---|---|
| Ranking functions | rank | rank |
| dense_rank | denseRank | |
| percent_rank | precentRank | |
| ntile | ntile | |
| row_number | row_number | |
| Analytic functions | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | last_value | |
| lag | lag | |
| lead | lead |
rank遇到相同的数据则rank并列,因此rank 值可能是不连续的dense_rank遇到相同的数据则rank并列,但是rank 值一定是连续的row_number很单纯的行号,类似excel的行号,不会因为数据相同而rank 的值重复或者有间隔percent_rank= 相同的分组中 (rank -1) / ( count(score) - 1 )ntile(n)是将同一组数据 循环的往n个 桶中放,返回对应的桶的index,index从1开始。
窗口函数的功能包含以下三部分:
- 分区:指定分区规则并在排序和计算帧之前将同个分区的数据收集到同台机器上
- 排序:指定排序规则确定行数据在分区中的排序位置
- 帧范围:确认 Frame 包含哪些数据 - 当前行以及前三行或者当前行以及后三行或只是当前行
在 SQL 中,partition by 指定分区, order by 指定排序:over (partition by ... order by ...) ;在 API 中,用以下方式指定
import org.apache.spark.sql.expressions.Window
Window.partitionBy().orderBy()
除了分区和排序,还可以去定义帧的开始、结束和类型。边界包含当前行到开始行、当前到尾行、当前行、前几行、后几行;类型分为ROW frame 和 RANGE frame
ROW frame
row frame 是基于当前行位置的物理偏移:指定某行为当前行后,再包含前几行和后几行数据为一帧数据
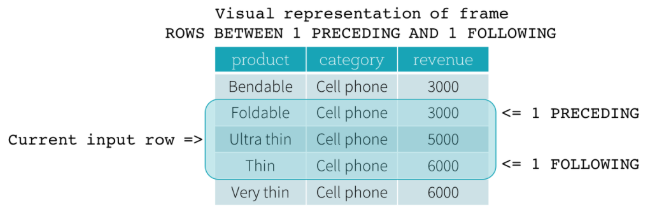
上图的一帧包含:当前行、前一行、后一行
RANGE frame
Range frame 是基于当前行位置的逻辑偏移,与 row frame类似语法也是包含起始和结束。假设要排序的值是key,那么逻辑偏移是值当前行key 值与其他行key 值之间的差值;另外帧内所有行的key 值都是会设置为 当前行key 的值。看下图来理解:key = revenue,开始边界是 2000 PRECEDING 结束边界是 ` 1000 FOLLOWING `
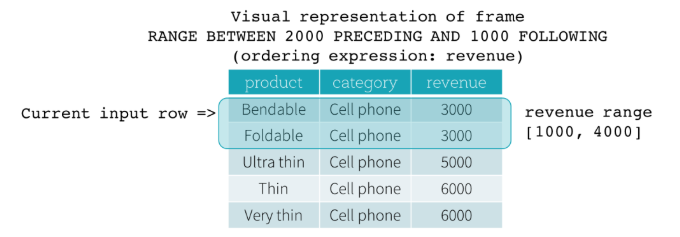
当前行revenue 值为 3000,那么逻辑偏移就是 [1000,4000],就可以得到当前的帧数据是 Bendable 和 Foldable。
到此应该可以理解第二个需求的代码:
func.max(dataFrame['revenue']).over(windowSpec):新增一列数据,该列数据的所有值是分组中收入最高行的收入值- 新增列 -
dataFrame['revenue']:分组内收入最高收入与每行的差值 - 查询中新增列即可