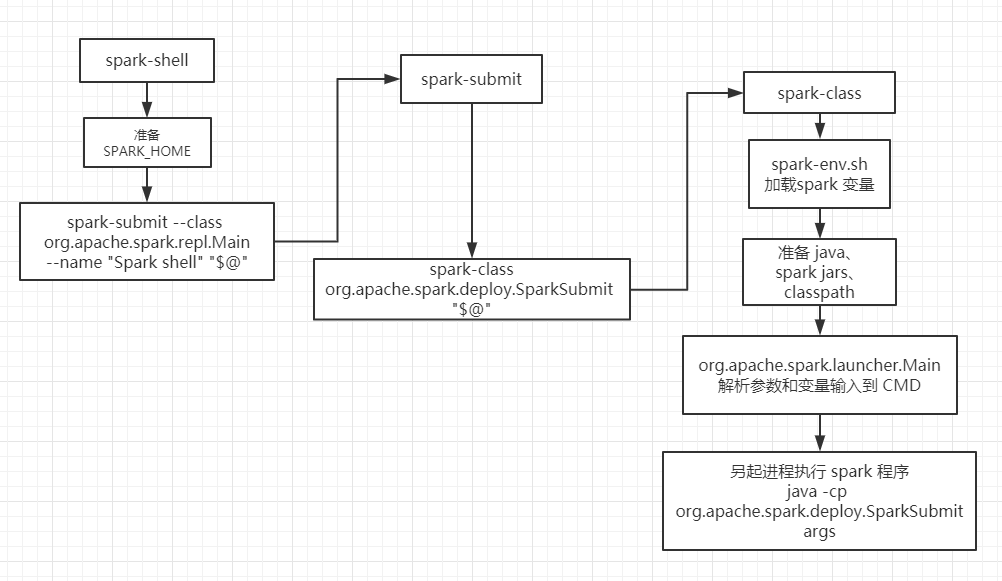
spark-shell 经常接触,其执行步骤却没怎么了解过。本节一起去了解下 spark-shell 的执行步骤。
spark-shell --master yarn
spark-shell
# spark-shell
cygwin=false
case "$(uname)" in
CYGWIN*) cygwin=true;;
esac
# Enter posix mode for bash
set -o posix
if [ -z "${SPARK_HOME}" ]; then
# dirname "$0" = dirname spark-shell = spark-shell 路径
# 执行 spark/bin/find-spark-home 脚本获取 SPARK_HOME
source "$(dirname "$0")"/find-spark-home
fi
export _SPARK_CMD_USAGE="Usage: ./bin/spark-shell [options]
Scala REPL options:
-I <file> preload <file>, enforcing line-by-line interpretation"
# SPARK-4161: scala does not assume use of the java classpath,
# so we need to add the "-Dscala.usejavacp=true" flag manually. We
# do this specifically for the Spark shell because the scala REPL
# has its own class loader, and any additional classpath specified
# through spark.driver.extraClassPath is not automatically propagated.
SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true"
function main() {
if $cygwin; then
# Workaround for issue involving JLine and Cygwin
# (see http://sourceforge.net/p/jline/bugs/40/).
# If you're using the Mintty terminal emulator in Cygwin, may need to set the
# "Backspace sends ^H" setting in "Keys" section of the Mintty options
# (see https://github.com/sbt/sbt/issues/562).
stty -icanon min 1 -echo > /dev/null 2>&1
export SPARK_SUBMIT_OPTS="$SPARK_SUBMIT_OPTS -Djline.terminal=unix"
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
stty icanon echo > /dev/null 2>&1
else
export SPARK_SUBMIT_OPTS
"${SPARK_HOME}"/bin/spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
fi
}
# Copy restore-TTY-on-exit functions from Scala script so spark-shell exits properly even in
# binary distribution of Spark where Scala is not installed
exit_status=127
saved_stty=""
# restore stty settings (echo in particular)
function restoreSttySettings() {
stty $saved_stty
saved_stty=""
}
function onExit() {
if [[ "$saved_stty" != "" ]]; then
restoreSttySettings
fi
exit $exit_status
}
# to reenable echo if we are interrupted before completing.
trap onExit INT
# save terminal settings
saved_stty=$(stty -g 2>/dev/null)
# clear on error so we don't later try to restore them
if [[ ! $? ]]; then
saved_stty=""
fi
main "$@"
# record the exit status lest it be overwritten:
# then reenable echo and propagate the code.
exit_status=$?
onExit
# find-spark-home
FIND_SPARK_HOME_PYTHON_SCRIPT="$(cd "$(dirname "$0")"; pwd)/find_spark_home.py"
# Short circuit if the user already has this set.
if [ ! -z "${SPARK_HOME}" ]; then
exit 0
elif [ ! -f "$FIND_SPARK_HOME_PYTHON_SCRIPT" ]; then
# If we are not in the same directory as find_spark_home.py we are not pip installed so we don't
# need to search the different Python directories for a Spark installation.
# Note only that, if the user has pip installed PySpark but is directly calling pyspark-shell or
# spark-submit in another directory we want to use that version of PySpark rather than the
# pip installed version of PySpark.
# $(dirname "$0") = $(dirname find-spark-home) = spark/bin/
# cd "$(dirname "$0")"/.. = cd spark/bin/.. = spark/
# SPARK_HOME = spark/ 找到 SPARK_HOME
export SPARK_HOME="$(cd "$(dirname "$0")"/..; pwd)"
else
# We are pip installed, use the Python script to resolve a reasonable SPARK_HOME
# Default to standard python interpreter unless told otherwise
if [[ -z "$PYSPARK_DRIVER_PYTHON" ]]; then
PYSPARK_DRIVER_PYTHON="${PYSPARK_PYTHON:-"python"}"
fi
export SPARK_HOME=$($PYSPARK_DRIVER_PYTHON "$FIND_SPARK_HOME_PYTHON_SCRIPT")
fi
- 确认执行环境是否为
cygwin(win 下安装的linux环境) ,后续在 main函数特殊处理 - 确认准备好环境变量
SPARK_HOME,若原先无SPARK_HOME则调用find-spark-home去获取 - 调用
main执行- 设置环境变量
SPARK_SUBMIT_OPTS= ="$SPARK_SUBMIT_OPTS -Dscala.usejavacp=true -Djline.terminal=unix" - 执行
spark-submit --class org.apache.spark.repl.Main --name "Spark shell" "$@"
- 设置环境变量
- 执行
onexit退出
spark-shell 实际是调用 **spark-submit **去执行,设置 name = Spark shell ,class = org.apache.spark.repl.Main
spark-submit
# spark-sumbit
# 如果是 spark-shell 进来的话,确定有 SPARK_HOME,否则与 spark-shell 一样要去获取 SPARK_HOME
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
只有一行语句 spark-class org.apache.spark.deploy.SparkSubmit "$@",串起来就是
spark-class org.apache.spark.deploy.SparkSubmit
--class org.apache.spark.repl.Main
--name "Spark shell"
--master yarn
spark-submit 底层是调用
spark-class
spark-class
if [ -z "${SPARK_HOME}" ]; then
source "$(dirname "$0")"/find-spark-home
fi
# 执行 load-spark-env.sh 就是去执行 conf/spark-env.sh 来设置 spark 环境变量
. "${SPARK_HOME}"/bin/load-spark-env.sh
# RUNNER = java
# Find the java binary
if [ -n "${JAVA_HOME}" ]; then
RUNNER="${JAVA_HOME}/bin/java"
else
# "command -v java" 命令可以获取 java 可执行文件目录
if [ "$(command -v java)" ]; then
RUNNER="java"
else
echo "JAVA_HOME is not set" >&2
exit 1
fi
fi
# Find Spark jars.
if [ -d "${SPARK_HOME}/jars" ]; then
SPARK_JARS_DIR="${SPARK_HOME}/jars"
else
SPARK_JARS_DIR="${SPARK_HOME}/assembly/target/scala-$SPARK_SCALA_VERSION/jars"
fi
if [ ! -d "$SPARK_JARS_DIR" ] && [ -z "$SPARK_TESTING$SPARK_SQL_TESTING" ]; then
echo "Failed to find Spark jars directory ($SPARK_JARS_DIR)." 1>&2
echo "You need to build Spark with the target \"package\" before running this program." 1>&2
exit 1
else
LAUNCH_CLASSPATH="$SPARK_JARS_DIR/*"
fi
# Add the launcher build dir to the classpath if requested.
if [ -n "$SPARK_PREPEND_CLASSES" ]; then
LAUNCH_CLASSPATH="${SPARK_HOME}/launcher/target/scala-$SPARK_SCALA_VERSION/classes:$LAUNCH_CLASSPATH"
fi
# For tests
if [[ -n "$SPARK_TESTING" ]]; then
unset YARN_CONF_DIR
unset HADOOP_CONF_DIR
fi
# The launcher library will print arguments separated by a NULL character, to allow arguments with
# characters that would be otherwise interpreted by the shell. Read that in a while loop, populating
# an array that will be used to exec the final command.
#
# The exit code of the launcher is appended to the output, so the parent shell removes it from the
# command array and checks the value to see if the launcher succeeded.
build_command() {
"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"
printf "%d\0" $?
}
# Turn off posix mode since it does not allow process substitution
set +o posix
CMD=()
# build_command 逐行输出解析好的参数
# ARG 接收参数
while IFS= read -d '' -r ARG; do
CMD+=("$ARG")
done < <(build_command "$@")
COUNT=${#CMD[@]}
LAST=$((COUNT - 1))
LAUNCHER_EXIT_CODE=${CMD[$LAST]}
# Certain JVM failures result in errors being printed to stdout (instead of stderr), which causes
# the code that parses the output of the launcher to get confused. In those cases, check if the
# exit code is an integer, and if it's not, handle it as a special error case.
if ! [[ $LAUNCHER_EXIT_CODE =~ ^[0-9]+$ ]]; then
echo "${CMD[@]}" | head -n-1 1>&2
exit 1
fi
if [ $LAUNCHER_EXIT_CODE != 0 ]; then
exit $LAUNCHER_EXIT_CODE
fi
CMD=("${CMD[@]:0:$LAST}")
exec "${CMD[@]}"
- 执行
spark-env.sh设置 spark 运行时环境变量 - 设置
RUNNER= java 可执行文件路径 - 设置
SPARK_JARS_DIR=spark/jars目录 - 设置
LAUNCH_CLASSPATH=spark/jars/* build_command执行"$RUNNER" -Xmx128m -cp "$LAUNCH_CLASSPATH" org.apache.spark.launcher.Main "$@"解析参数和环境变量存入CMDexec "${CMD[@]}":启动CMD进程开始真正的 spark 程序
build_command 的 java 是 执行哪个类带什么参数
# Main 里解析好参数和环境变量后输出,刚好被 CMD 接收
org.apache.spark.launcher.Main 带参数
org.apache.spark.deploy.SparkSubmit
--class org.apache.spark.repl.Main
--name "Spark shell"
--master yarn
最后看看 CMD 里究竟是什么东西
# 还是 java 进程
/home/hadoop/app/jdk1.8.0_45/bin/java -cp /home/hadoop/app/spark/conf/:/home/hadoop/app/spark/jars/*:/home/hadoop/app/hadoop-2.6.0-cdh5.15.1/etc/hadoop/
-Dscala.usejavacp=true
# 设置 1G
-Xmx1g
# SparkSubmit spark程序入口
org.apache.spark.deploy.SparkSubmit
--master yarn
--class org.apache.spark.repl.Main
--name Spark shell
spark-shell
总结
以一副流程图来梳理下 spark-shell 的执行步骤