Spark shuffle的概念与hadoop shuffle不同
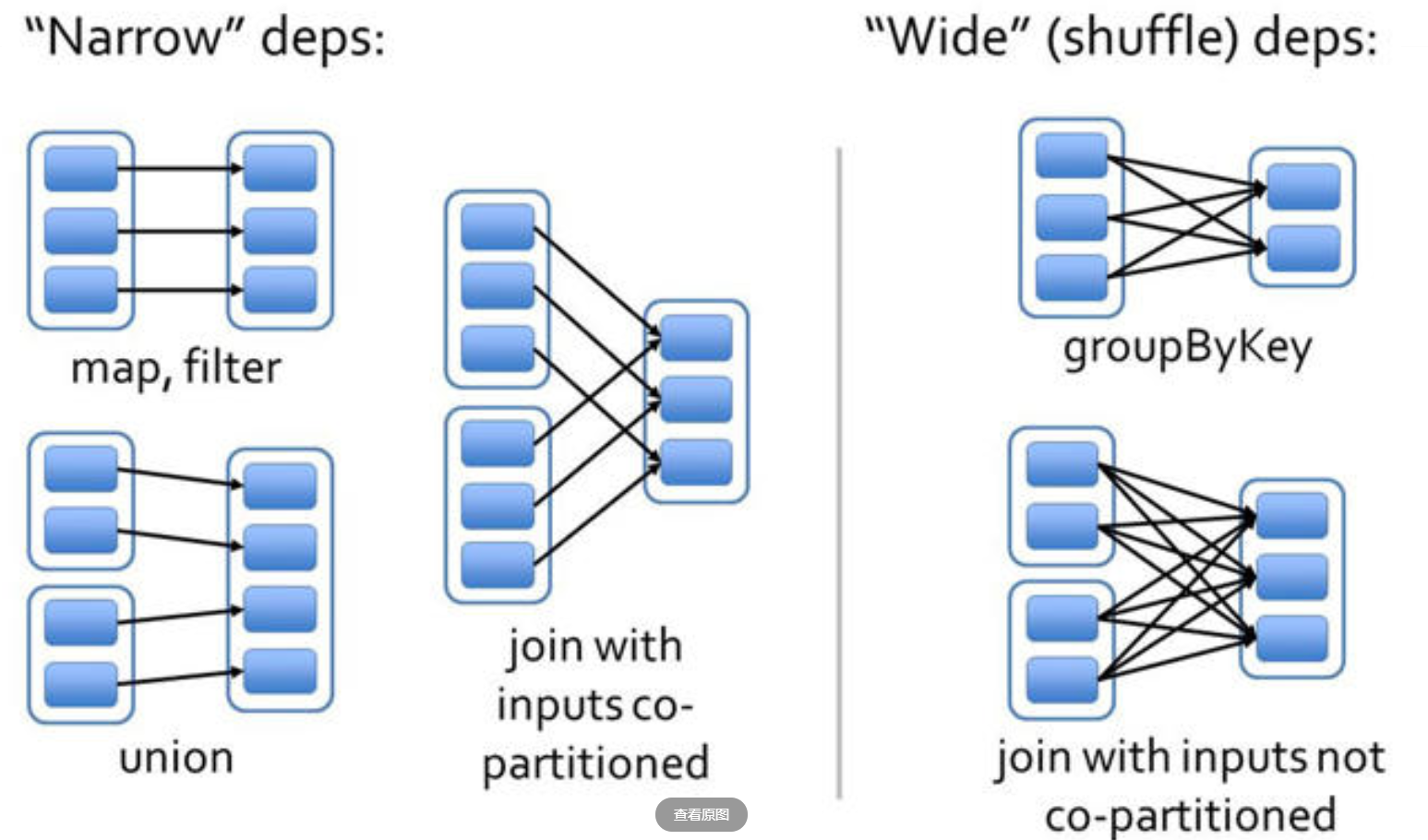
在 Hadoop 中,shuffle 是发送在 map -> reduce 之间的数据传输,而在 Spark 中 shuffle 是发生在 窄依赖 -> 宽依赖 之间。那窄依赖、宽依赖是如何定义?
- 窄依赖:
父 RDD的每个分区只被一个子 RDD的分区使用 - 宽依赖:
父 RDD的每个分区有可能被多个子 RDD的分区使用
确认好什么时候后会发送 shuffle 后,来看看 Spark shuffle 的演变之路 : SparkEnv
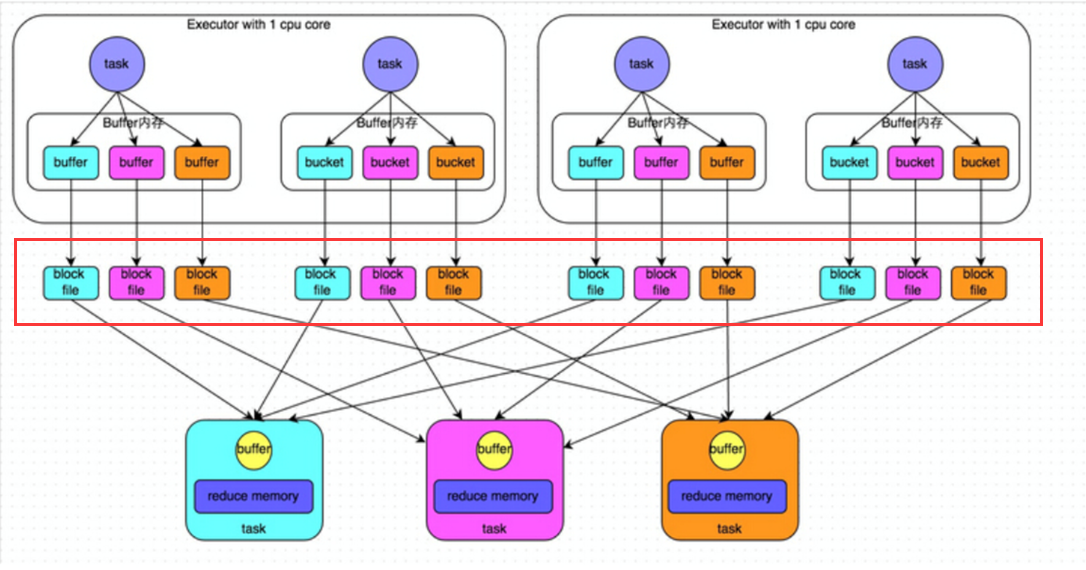
HashShuffle
Spark 最初的版本就是 HashShuffle,勉强能用但有很多缺点。在 shuffle 会产生很多的小文件(shuffle 时若内存放不下会落到磁盘文件,而默认shuffle 内存大小是 32k, spark.shuffle.file.buffer 参数 ):每个 task 根据下游的reduce 任务个数产生一个小文件,故小文件个数为 n mapTask * m reduceTask ;在实际生产在 n、m基数都是很大的,不免会产生海量的小文件可能导致 OOM。
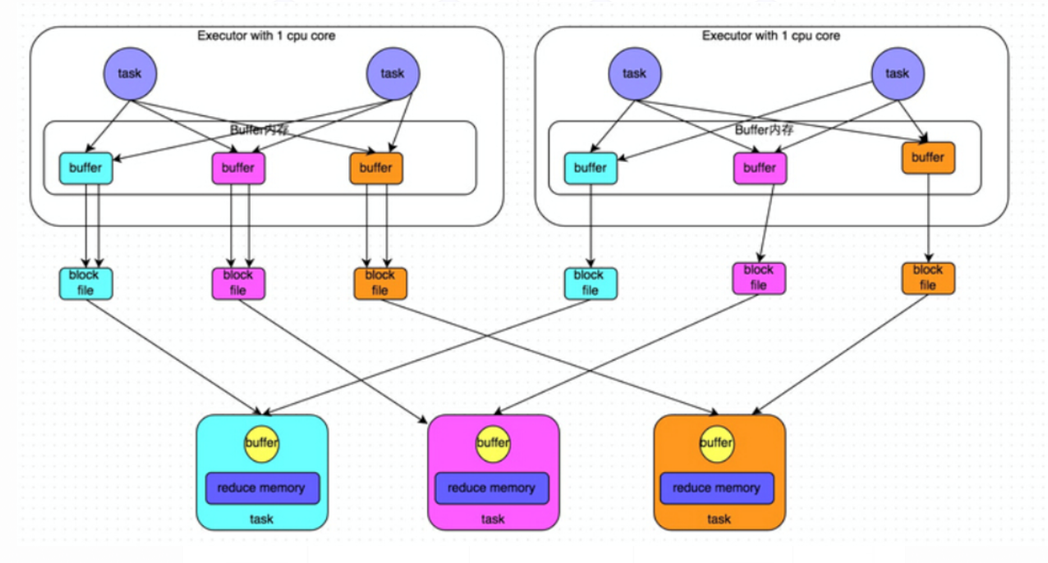
Consolidated HashShuffle
HashShuffle 会产生这么多小文件,Consolidated HashShuffle 就是对它的改进。Consolidated HashShuffle 下,同个Core上执行的 task 会共用 shuffle 文件即一个 Core 上不管有多少个 task 都只会生成 m reduceTask 个 shuffle 文件,对比于HashShuffle 是少了很多
SortShuffle
上述两种方式产生的小文件个数都是两个数的乘积,若两个数的基数不小那难免还是会产生大量的小文件。在 Spark 1.1.0 引进SortShuffle 就很好的解决了难题:shuffle 文件个数与 m reduceTask无关,只与任务的 Exceutor 个数相关
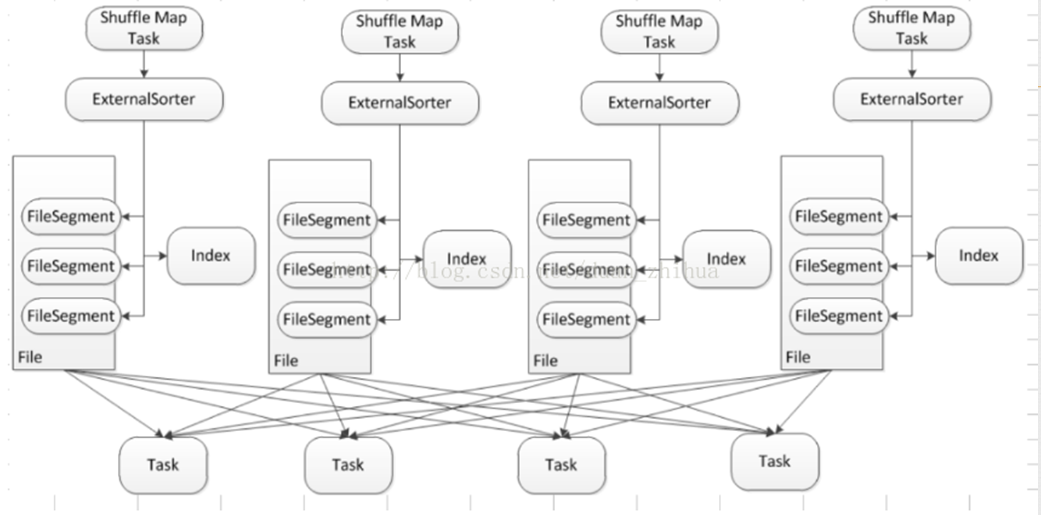
如上图所示,每个 mapTask 只产生2个文件:data、index
参数
Spark 的 shuffle 演变之路我们已经看过了,下面来看看 shuffle 过程中那些参数可以调整
spark.shuffle.manager:指定shuffle 类型:hash、Consolidated、sortspark.shuffle.file.buffer: shuffle 时可占用内存大小,默认32kb,可适当翻倍- ` spark.reducer.maxSizeInFlight
:shuffle 时 reduce 端拉取数据可占用内存大小,默认48M`,可适当翻倍 - ` spark.shuffle.io.maxRetries `:shuffle 获取数据失败重试次数,默认 3次
- ` spark.shuffle.io.retryWait `:shuffle 获取数据失败后设定延迟几秒再获取,默认5s ;可得数据获取失败响应时间是 3 *5 s = 15 s
- ` spark.shuffle.sort.bypassMergeThreshold
:sorthash` 模式才能使用,设定reducer 端超过几个任务就自动归并排序;显然大多数情况是多余操作(要归并排序作业会指定),考虑增大该值 - ` spark.shuffle.spill.compress
:shuffle 的落盘文件是否压缩,spark.io.compression.codec ` 指定压缩方法 spark.io.compression.codec:spark 作业过程中指定的压缩方法:lz4,lzf,snappy, andzstd- ` spark.shuffle.compress
:map 输出是否压缩,spark.io.compression.codec ` 指定压缩方法
总结
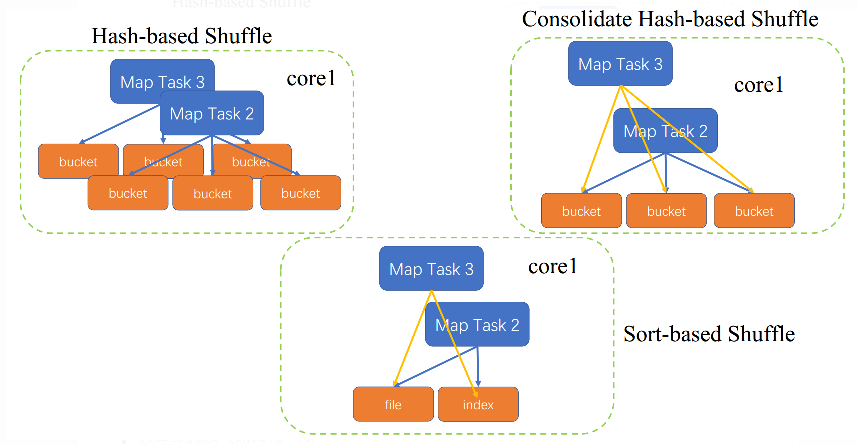
shuffle 文件数:M = mapTask,C = 任务的 core 个数,R = reduceTask
basic hashshuffle:M * RConsolidated HashShuffle:C * RSortShuffle:2 * M