理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源。在Yarn中,负责给应用分配资源的就是 Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
在Yarn中有三种调度器可以选择:FIFO Scheduler ,Capacity Scheduler,FairScheduler。
FIFO Scheduler:很好理解,任务先进先出,大任务会堵塞后面的其他任务Capacity Scheduler:有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间 ;apache yarn默认调度器FairScheduler: 为所有的应用分配公平的资源 , 每个应用有一定的资源使用(资源单指内存)
三种调度器可以在 yarn-site.xml 中设置
| 属性 | 值 |
|---|---|
| yarn.resourcemanager.scheduler.class | org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler |
CDH yarn 默认调度器是 FairScheduler,调度策略是 DRF:基于 vcore 和内存的策略。CDH 有个资源池的概念,默认是静态资源池。但用在生产中不合适,大部分使用的是动态资源池,何为动态:当其他队列的资源没有被使用时,运行中的作业可以去占用这些资源。根据实际情况,可以两种方式来划分队列:人员角色、项目角色
人员角色
项目中人员大致可以分为三种:测试、开发、生产,由此我们也可以将队列划分三种:qa、dev、pro。
CDH 设置
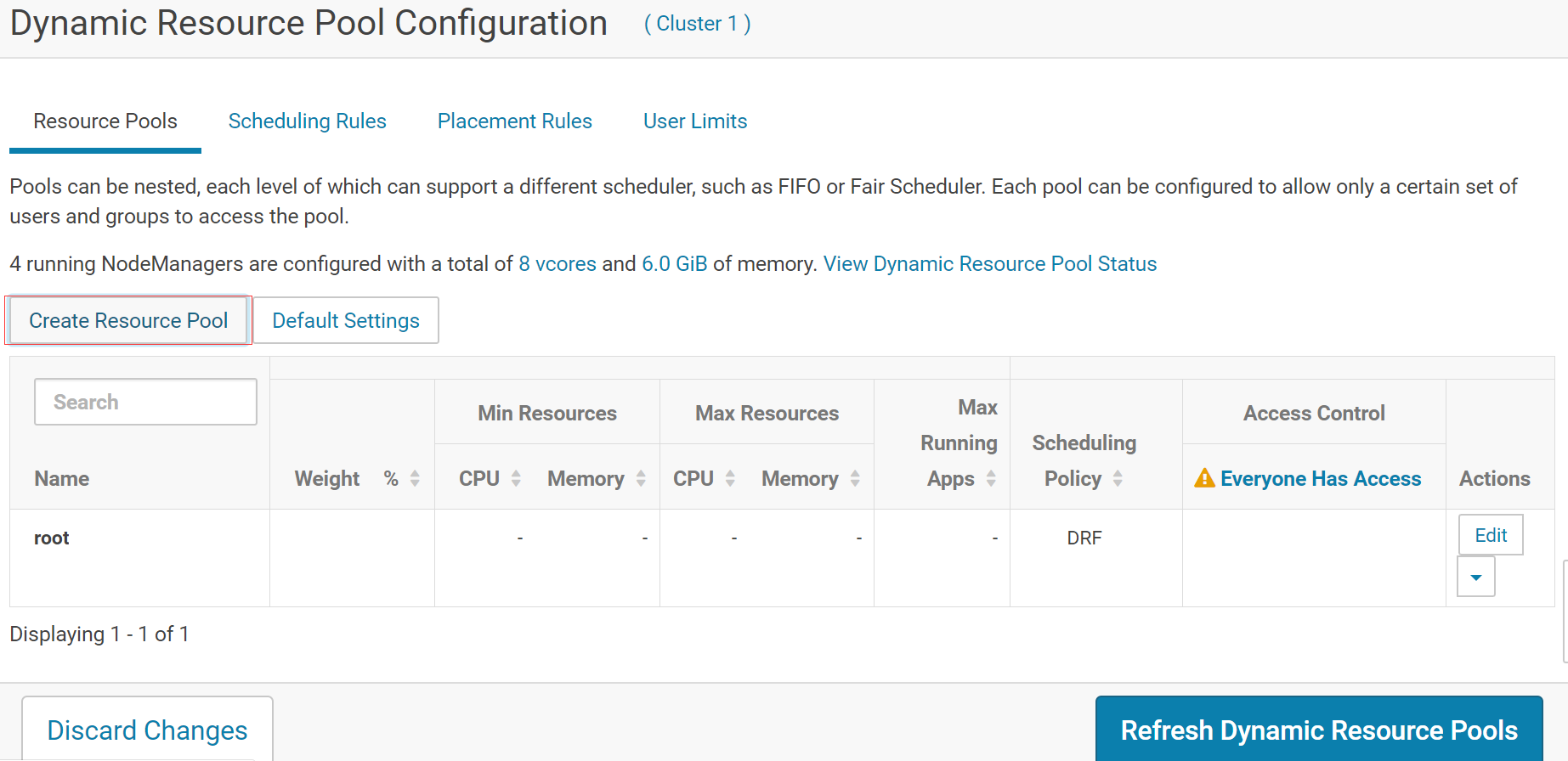
在web 界面创建相应的队列和 default(不在三种角色里的都用 default),并设置放置规则
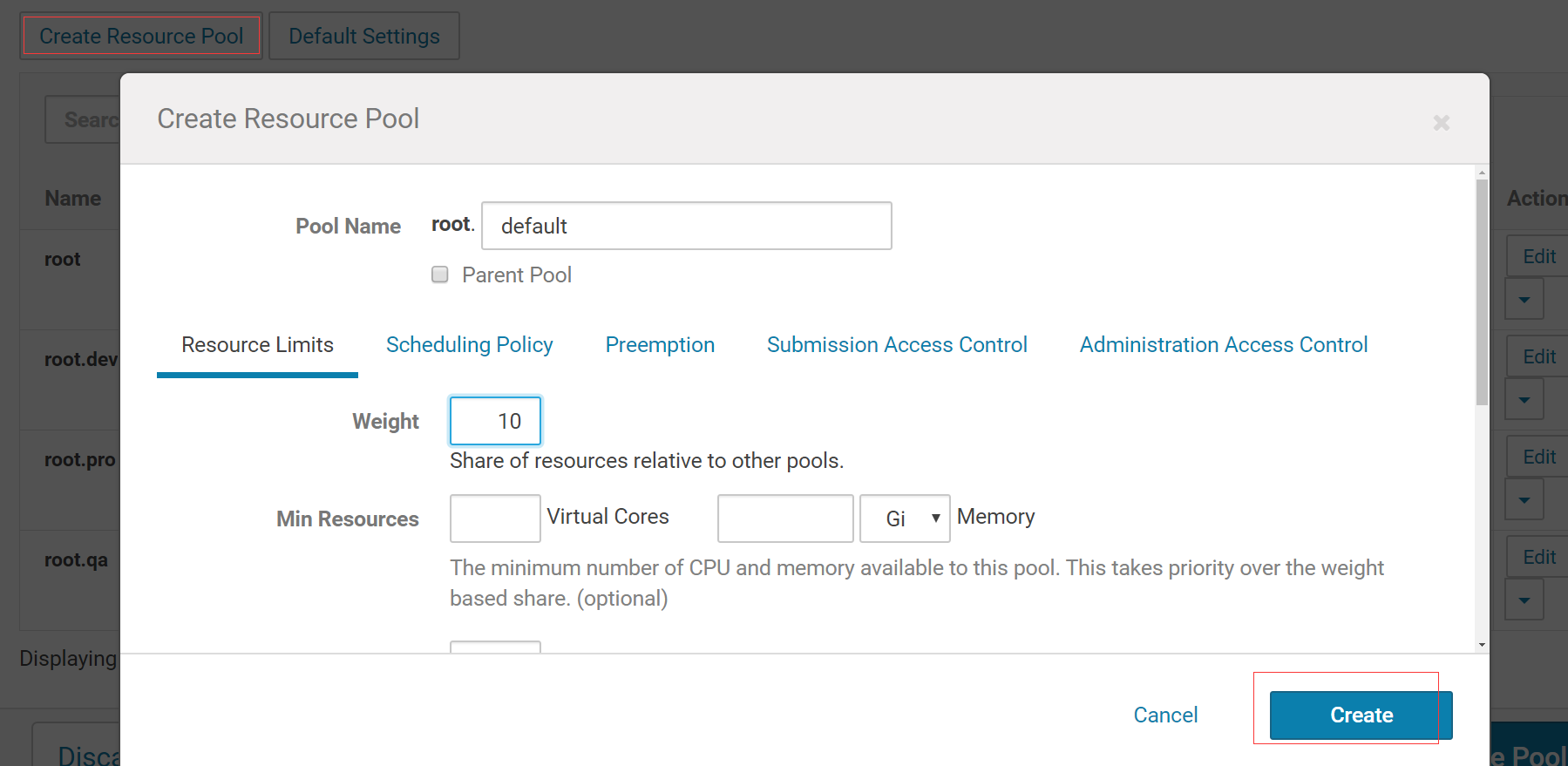
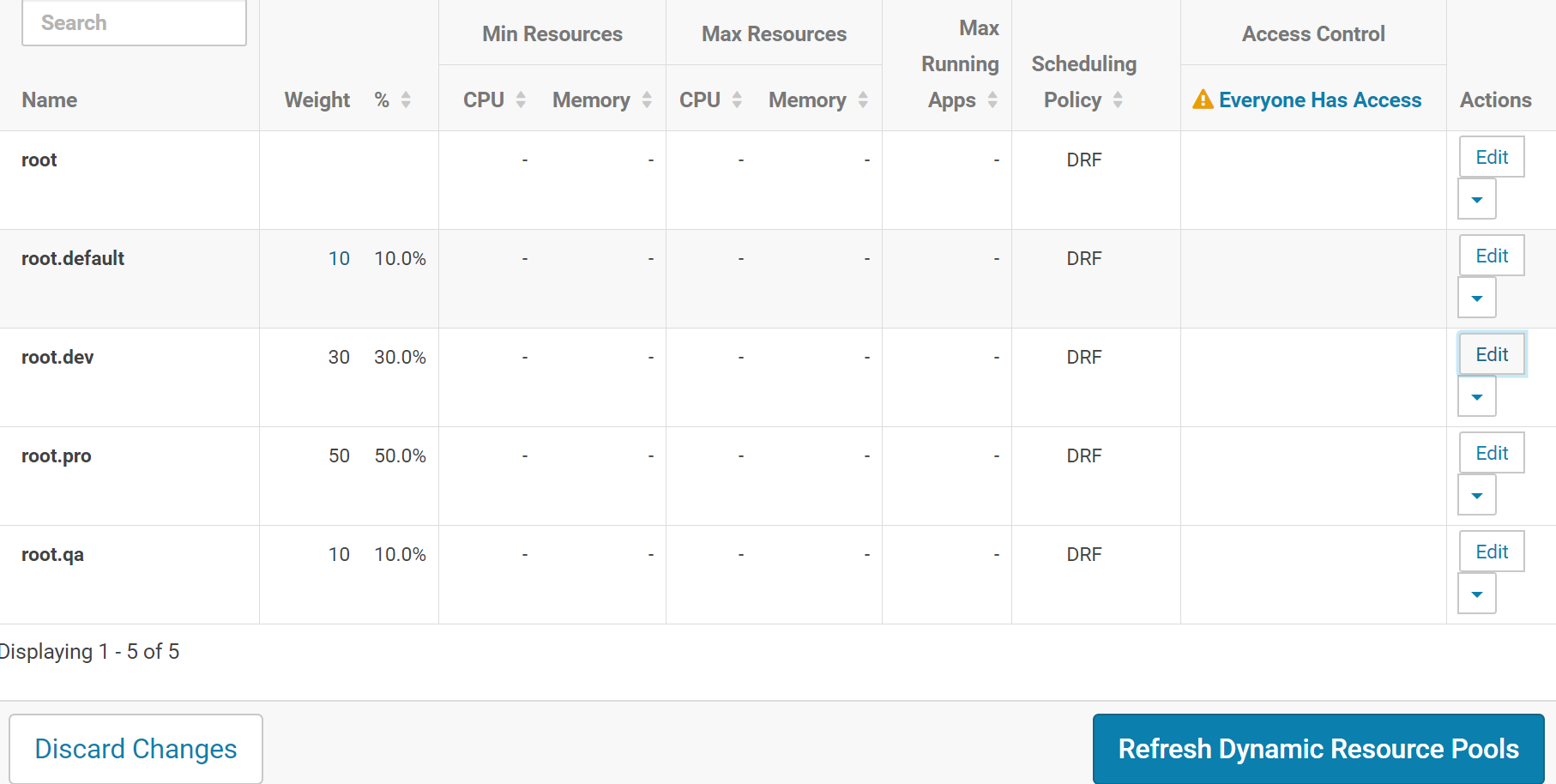
创建qa、dev、pro、default 四个队列
先清空规则
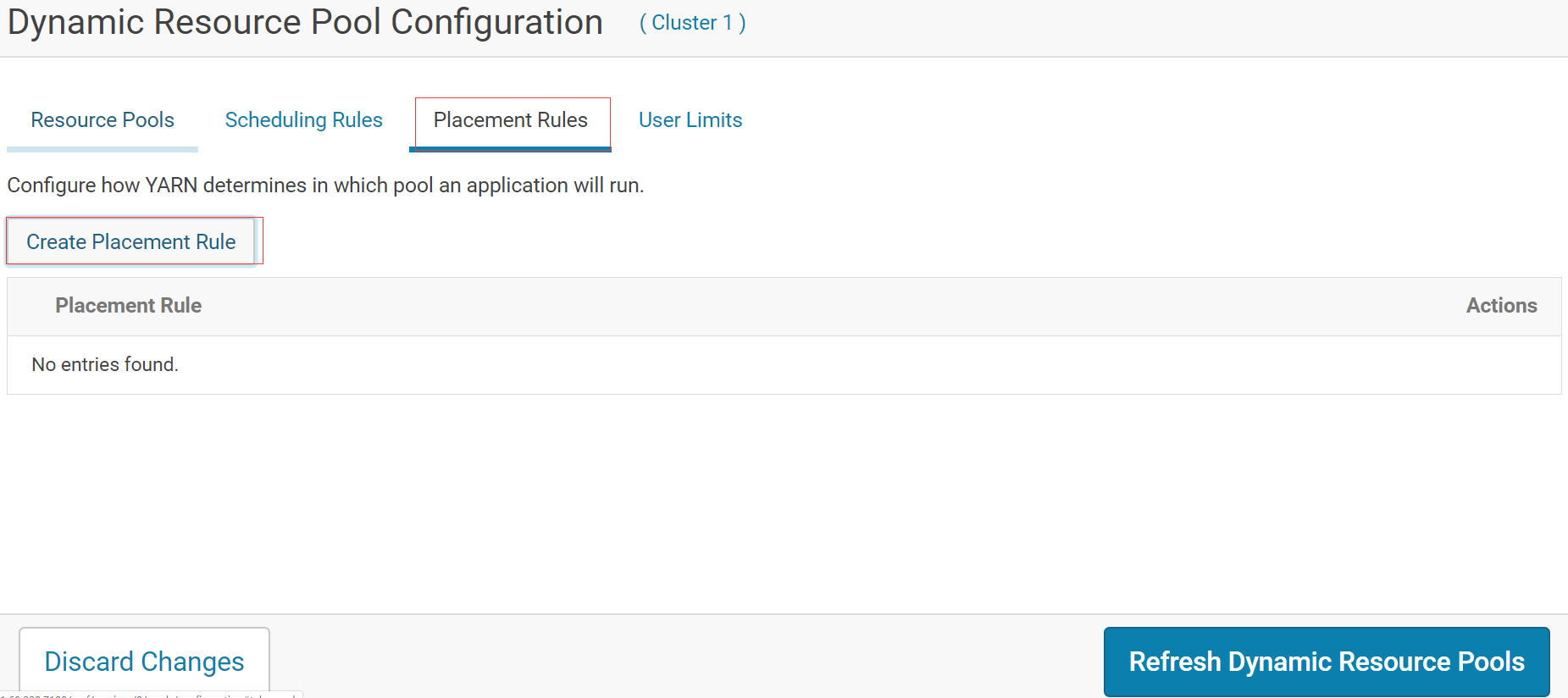
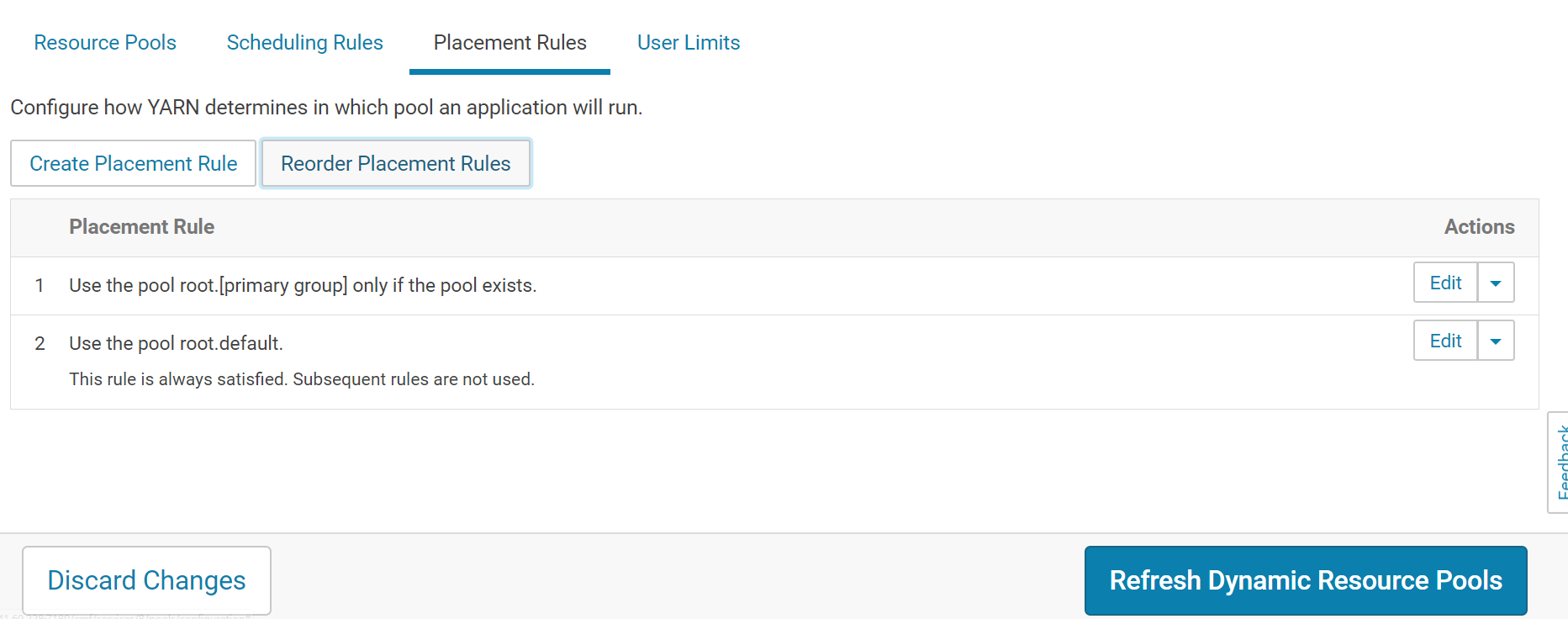
规则如下:若用户组是 qa、dev、pro则放到对应的队列,否则放进 default
用户设置
在web 界面设置的规则是根据用户组来确定放置的队列,那么我们就在机器添加三个用户组并用户添加打对应的组内。
按人员角色分配这种方式,需要在所有机器上都设置所需的用户组和用户。
[root@hadoop001 ~]# groupadd dev
[root@hadoop001 ~]# groupadd qa
[root@hadoop001 ~]# groupadd pro
[root@hadoop001 ~]# useradd -g dev dev1
[root@hadoop001 ~]# useradd -g qa qa1
[root@hadoop001 ~]# useradd -g pro pro
测试
[root@hadoop004 ~]# su - dev1
[dev1@hadoop004 ~]$ spark2-submit --master yarn --deploy-mode cluster
--num-executors 3 --class org.apache.spark.examples.SparkPi
examples/jars/spark-examples_2.11-2.4.0.cloudera2.jar
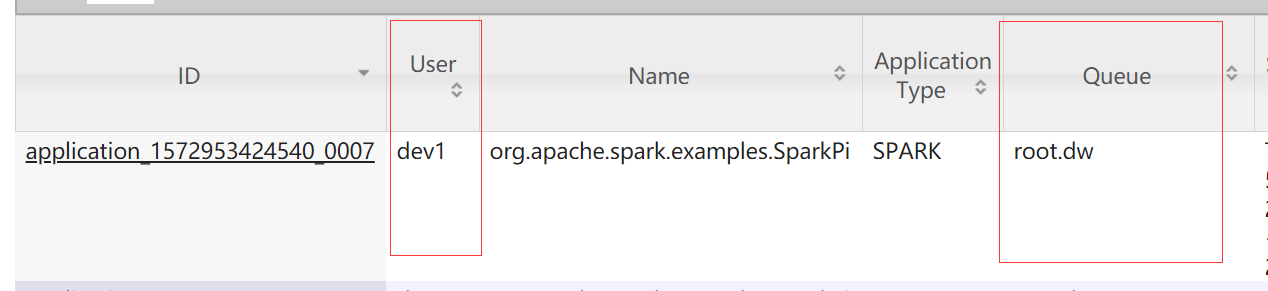
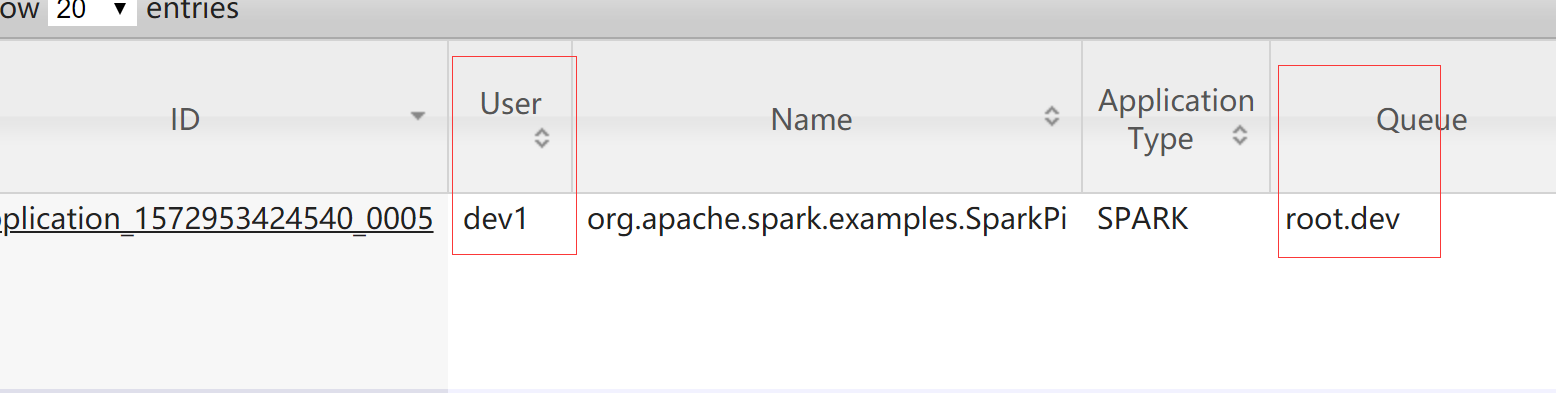
查看 yarn web界面,dev1 用户提交的任务进入 dev 队列
项目角色
每个项目建一个队列,假设公司当前有三个项目:dw、ss、aw。
CDH 设置
相同设置,最终队列如下
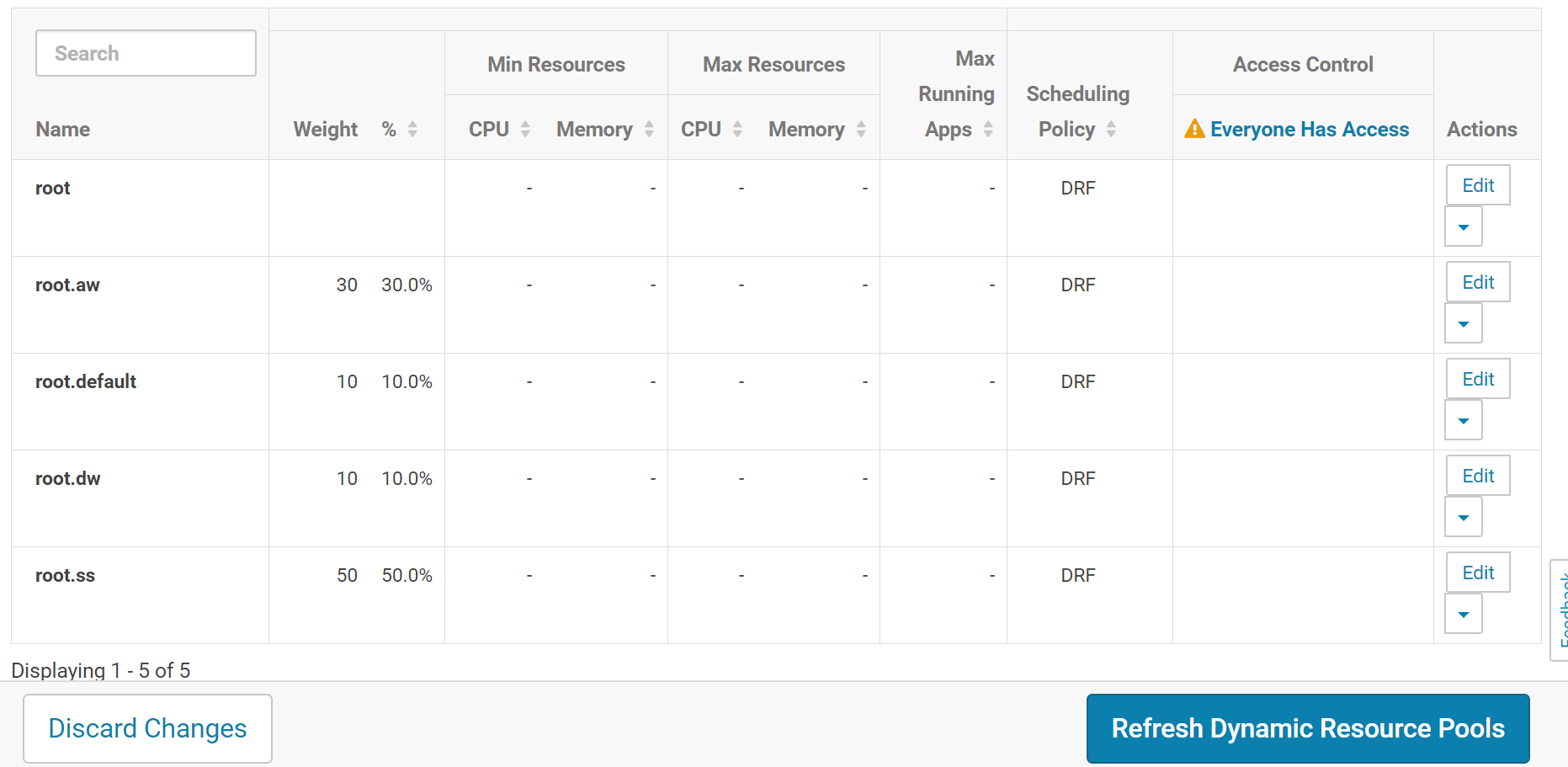
规则设置有所改变
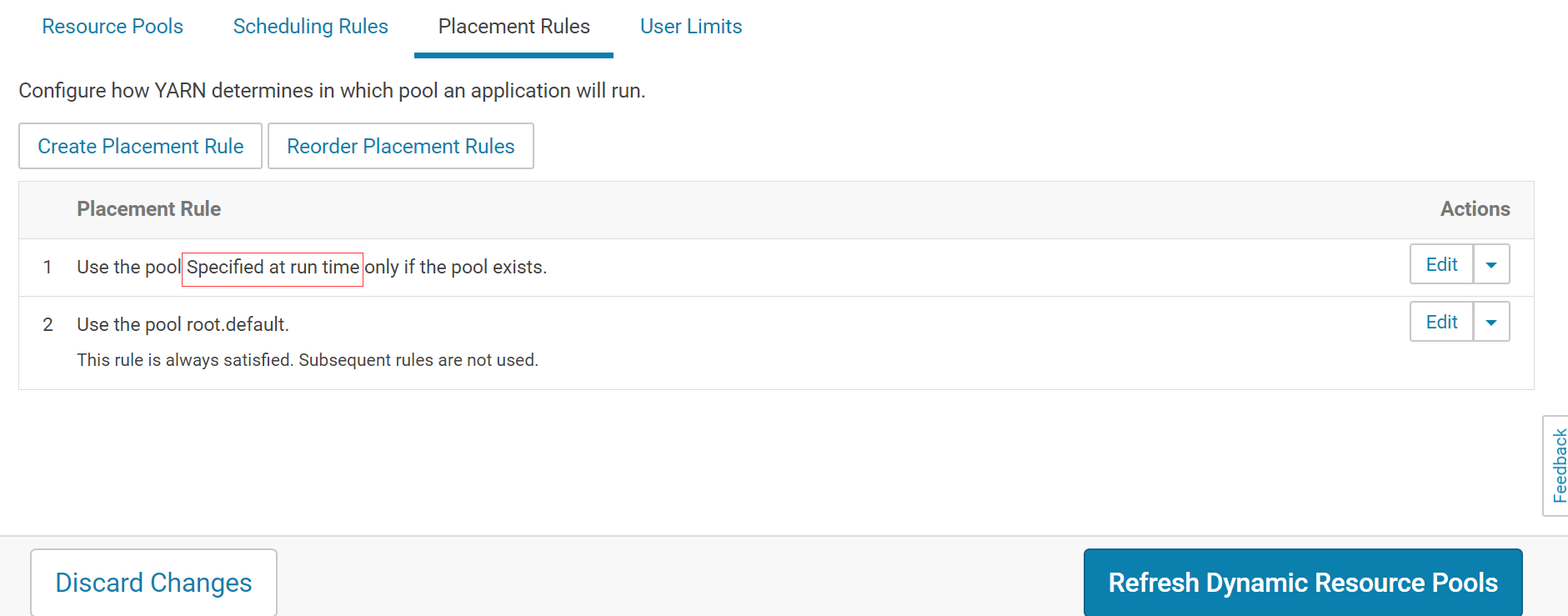
注意规则是 ` Specified at run time `
用户设置
这种方式不需要额外添加用户,但在项目增删时需要更新队列
测试
[dev1@hadoop004 spark2]$ spark2-submit --queue dw --master yarn --deploy-mode cluster
--num-executors 3 --class org.apache.spark.examples.SparkPi
examples/jars/spark-examples_2.11-2.4.0.cloudera2.jar