kafka
console-consumer 无法消费 msg
安装好 kafka 后,命令行测试创建主题,生产数据都没有问题,但consumer 始终无法接收到数据。kafka log(/var/local/kafka/data) 下主题文件存在且有数据,--desctibe 查看主题状态读正常。在log 目录 /var/log/kafka 下查看日志发现这么一行
2019-11-01 11:12:17,506 ERROR kafka.server.KafkaApis:
[KafkaApi-43] Number of alive brokers '2' does not meet the required replication factor '3'
for the offsets topic (configured via 'offsets.topic.replication.factor').
This error can be ignored if the cluster is starting up and not all brokers are up yet.
意思是 offsets topic 副本数是3,而当前运行的 kafka broker 只有 2;broker 必须要大于等于 offset副本数,可以配置 offsets.topic.replication.factor 。知道解决方案了,直接去 CDH web 界面的 kafka 配置里修改
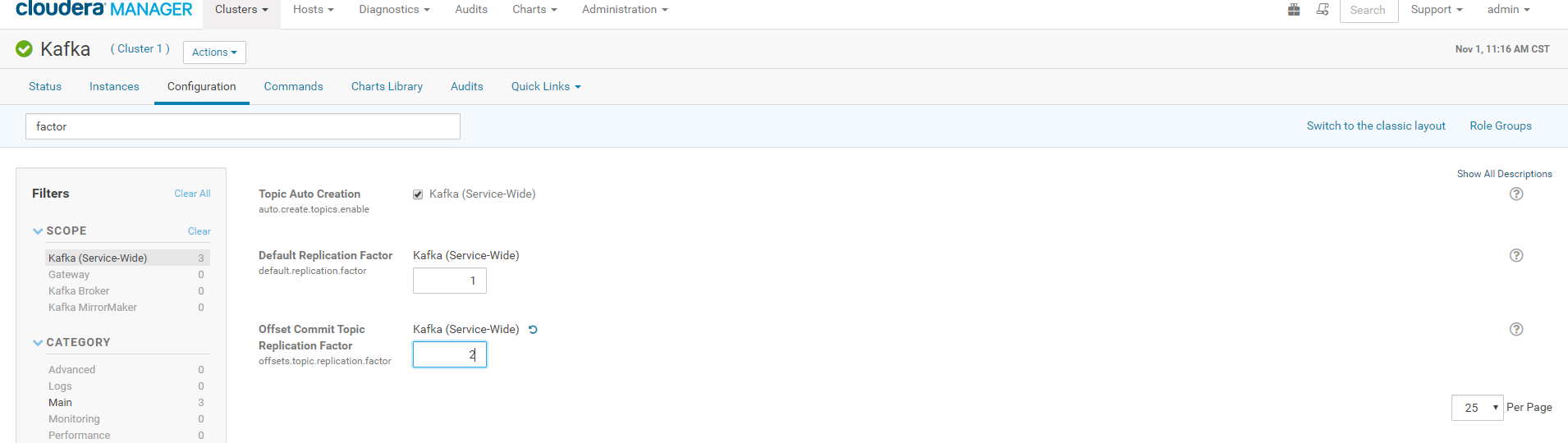
保存配置然后重启 kafka 即可。
问题解决后,我们来说说为什么会有这个问题:刚开始安装 kafka 是有三台的,但有台机器内存吃不消就删除了,导致offset 副本默认是3。
Spark
kafka version
spark + Kafka 处理时,必须上传 kafka-clients 和 spark-streaming-kafka jar。在运行过程中可能提示
19/11/04 19:30:20 INFO utils.AppInfoParser: Kafka version : 0.9.0-kafka-2.0.2
19/11/04 19:30:20 INFO utils.AppInfoParser: Kafka commitId : unknown
Exception in thread "streaming-start" java.lang.NoSuchMethodError: org.apache.kafka.clients.consumer.KafkaConsumer.subscribe(Ljava/util/Collection;)V
提示找不到方法,但我们已经上传 kafka-clients,为什么还是找不到?看日志的第一行,kafka version 是0.9.0,但 CDH 的kafka 版本是2.2.1,为何会这样? 需要在 cdh 的spark 中设置 kafka 版本,默认是 0.9:
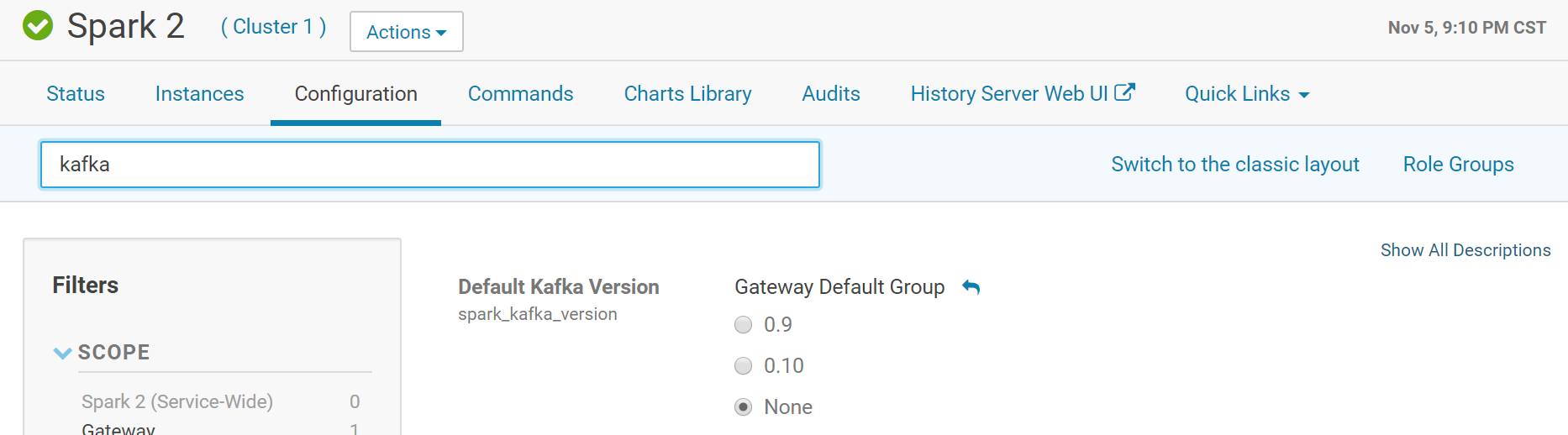
选择 None 就是自动选择 cdh 中安装的 Kafka 版本
19/11/05 09:48:26 INFO utils.AppInfoParser: Kafka version: 2.2.1
19/11/05 09:48:26 INFO utils.AppInfoParser: Kafka commitId: 55783d3133a5a49a
NoSuchMethodError
出现这个错误的原因是类中没有该方法(注意哦,不是找不到类),本质上是与kafka version 的错误一样,jar 版本冲突。以 guava 为例,平台环境(spark + yarn) 用的版本是11.0.1,代码使用的版本是 20.0,很显然20版本中有些函数在 11版本是不存在的。通常情况下,spark 作业执行时肯定是先加载环境的jar 然后再加载作业的jar,则在运行过程中guava 版本为 11,所以就出现 NoSuchMethodError 。解决错误也很简单,只需让运行过程中加载的 guava 版本是20 即可。
local模式:- 所有代码都在
Driver(在本地),只不过跑了多线程而已,spark-submit启动是添加--driver-class-path /.../guava-20.0.jar即可,这样就会预先加载 20版本的guava
- 所有代码都在
yarn-client:- 增加了
Executor,那么就需要对该节点机器设置,增加环境变量--conf spark.executor.extraClassPath=/.../guava-20.0.jar --conf spark.executor.userClassPathFirst=true;指定在Executor 中优先使用用户的 jar ,那么就会只加载 20版本的 guava
- 增加了
yarn-cluster:- Driver 也在远程,设置
--driver-class-path已经没有用了,要按照 Executor 一样设置:--conf spark.driver.extraClassPath --conf spark.driver.userClassPathFirst=true
- Driver 也在远程,设置
以上做了这么多,无非只想做到一点:作业的jar 和平台已有的jar 版本冲突时,先加载作业的jar 包。上面涉及到的参数,看官网的详细描述。