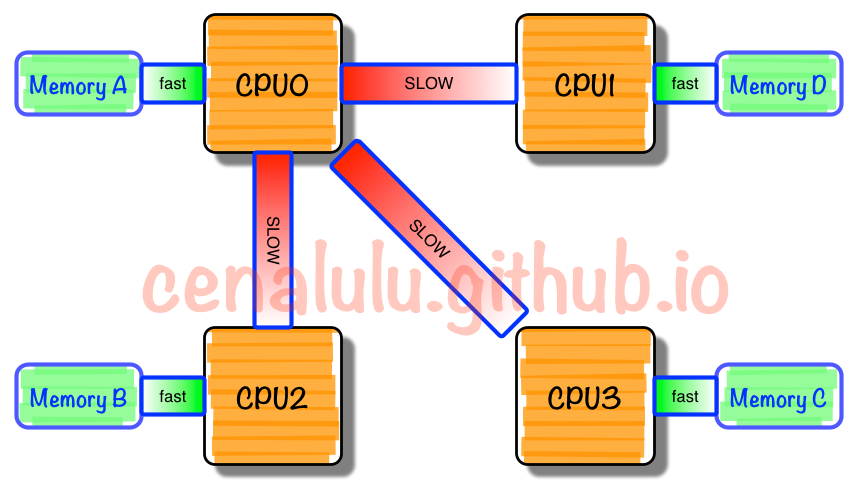
非统一内存访问架构(Non-uniform memory access,简称 NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置 。举个简单的例子: 比如一台机器是有 2 个处理器,有4个内存块。我们将1个处理器和两个内存块合起来,称为一个 NUMA node,这样这个机器就会有两个 NUMA node。在物理分布上,NUMA node 内的处理器和内存块的物理距离更小,因此访问也更快。比如这台机器会分左右两个处理器(cpu1, cpu2),在每个处理器两边放两个内存块(memory1.1, memory1.2, memory2.1,memory2.2),这样 NUMA node1 的 cpu1 访问 memory1.1 和 memory1.2 就比访问 memory2.1 和 memory2.2 更快。
使用
NUMA的模式如果能尽量保证本 node 内的 CPU 只访问本 node 内的内存块,那这样的效率就是最高的。
NUMA 架构导致 cpu 访问不同的内存速度会有快慢。很容易就想到启用 numa node 限制(只使用NUMA node 里的内存),但这里会有一个问题:当 node 的内存用完后,开始使用 SWAP,显然此时处理速度会减慢(swap 磁盘交换,一直swap 会负载攀升,最终导致宕机 ),若机器没有设置 swap 会直接死机;简而言之 node 限制导致空闲其他node 内存和负载飙升,具体参考 SWAP的罪与罚 。
在实际生产中应该如何设置 NUMA
- 如果程序占用大量内存,你可以关闭 numa node 的限制
- 如果程序 只占用少量内存且追求处理速度,你可以开启 numa node 限制,但有可能发生上面提及的问题
NUMA 涉及到内存使用,那么在实际生产中是很容易出问题,一起来看看几个案例
MySQL
机器有大量空闲内存却发生 swap,有时 OOM。
vmstat 命令实时查看 内存使用情况
# 每隔 1 s
[hadoop@danner000 ~]$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 381004 196680 1972148 10 12 23 24 8 37 0 0 100 0 0
0 0 0 380988 196680 1972148 11 15 20 90 142 229 0 1 99 0 0
可以看到 swap 一直发生(si、so 一般都为0),接下来看看内存的使用情况。
[hadoop@danner000 ~]$ free -gt
total used free shared buffers cached
Mem: 256 200 56 0 20 180
内存是空闲很多的,但为何会频繁发生 swap 呢?用 numa 看看
[hadoop@danner000 ~]$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3
node 0 size: 131037 MB
node 0 free: 1851 MB
node 1 cpus: 4 5 6 7
node 1 size: 131071 MB
node 1 free: 38670 MB
node distances:
# 下面cpu 访问内存距离
node 0 1
0: 10 20
1: 20 10
可以看到内存使用严重不均衡(38 vs 1.8),如果此时再向node 0申请大内存就发生 swap。显然是由于开启 NUMA 限制引起的,该如何解决:
-
BIOS 层关闭
NUMA,需重启 - 升级 MySQL 版本到
5.6.27及以后,新增了一个选项innodb_numa_interleave,只需要重启 mysqld 实例,无需重启OS,推荐此方案 - MySQL 版本在
5.6.27之前,带参数启动 ` numactl –interleave=all mysqld_safe &;interleave` 会均匀是用内存,详细看参考资料一
SWAP
内核参数 vm.swappiness 可以设置多大概率使用 swap 。有两种方式可以修改
-
当前立即生效:
[hadoop@danner000 ~]$ cat /proc/sys/vm/swappiness 60 [hadoop@danner000 ~]$ sysctl vm.swappiness=10 -
重启永久生效
[hadoop@danner000 ~]$ echo "vm.swappiness = 10" >> /etc/sysctl.conf [hadoop@danner000 ~]$ sysctl -p
该参数可选范围从 0 - 100,设为 0 就是希望最大限度使用物理内存,尽量不使用swap,设为 100 则是希望积极使用swap。在运行数据库进程的服务器上,我们通常强烈建议这个值小于等于10,最好是设置为 0。原因很简单,对数据库这种需要集中CPU资源、大内存、高I/O的程序而言,如果用SWAP分区代替内存,那数据库服务性能将是不可接受的,还不如直接被 OOM kill 。