生产中会做主从架构实现读写分离从而减轻 MySQL 压力,简单架构图如下
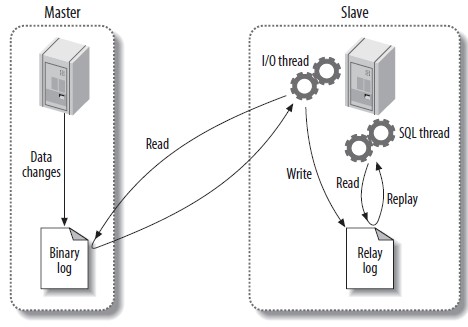
主从复制主要靠三个线程来实现
Master Binlog dump thread:响应 Slave I/O 并发送 Binlog 二进制内存;在一主多从模式下,会为每个 Slave I/O thread 创建 Binlog dump threadSlave I/O thread:当执行start slave命令后创建 I/O 线程,从 master 的指定位置读取数据保存到本地的relay-log,下次读取位置保存到master-infoSlave SQL thread: 读取relay-log内存并在本地数据库执行,此过程称为重演
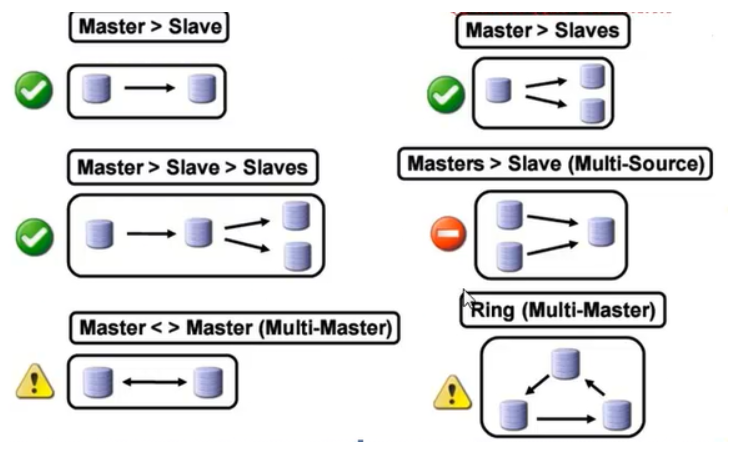
单向主从模式如上图所示,但也可以扩展形成以下几种模式
部署
每个节点上的部署没有特别之处,参考CDH 离线部署笔记 ,只需注意几个配置即可。
server-id:主从节点不能相同expire_logs_days:设置日志过期,单位天binlog_format: binlog 格式- ` STATEMENT `:修改数据的 sql 语句才记录到 binlog,可以减少日志量但有可能导致主从数据不一致
- ` ROW `:仅记录那些数据被修改,修改成什么,日志量会很大;本案例推荐
- ` MIXED
:以上两种模式混合,先用STATEMENT,不好使才用ROW`
log-bin:binlog 日志文件存储目录
两个节点都部署成功之后,开始配置
-
Master
# 主库上创建一个 复制用户 mysql> grant replication slave on *.* to repluser@'%' identified by '123456'; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) # 查看当前同步点 mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000010 | 593 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) # binlog 就在/usr/local/mysql/arch/mysql-bin.000010 -
Slave
# 由于master 之前有数据需同步,先用mysqldump 导入到 slave # 在 master 备份所有库操作 hadoop001:mysqladmin:/usr/local/mysql:>mysqldump -uroot -p123456 -A > tmp/allbak.sql hadoop001:mysqladmin:/usr/local/mysql:>scp tmp/allbak.sql root@hadoop004:/root/tmp # slave 恢复 hadoop004:mysqladmin:/usr/local/mysql/:>mysql -uroot -p123456 -A < /root/tmp/allbak.sql # slave 设置同步点 mysql> change master to -> master_host='hadoop001', -> master_port=3306, -> master_user='repluser', -> master_password='123456', -> master_log_file='mysql-bin.000010', -> master_log_pos=593; Query OK, 0 rows affected, 2 warnings (0.02 sec) # slave 开启同步 mysql> start slave; Query OK, 0 rows affected (0.00 sec) # 检测 I/O、sql 进程是否启动 mysql> show slave status\G; ... Slave_IO_Running: Yes Slave_SQL_Running: Yes ... # 接下来在master 操作就会同步到 slave 上
故障案例
# slave sql 线程挂了
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: hadoop001
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000013
Read_Master_Log_Pos: 103741
Relay_Log_File: relay-log.000010
Relay_Log_Pos: 103568
Relay_Master_Log_File: mysql-bin.000013
Slave_IO_Running: Yes
Slave_SQL_Running: No
......
Last_Errno: 1032
Last_Error: Coordinator stopped because there were error(s) in the worker(s).
The most recent failure being: Worker 0 failed executing transaction 'ANONYMOUS'
at master log mysql-bin.000013, end_log_pos 103710. See error log and/or
performance_schema.replication_applier_status_by_worker table for more details
about this failure or others, if any.
Skip_Counter: 0
看 Last_Error 执行Master的 mysql-bin.000013 的 103710 时发生错误。此时先停止同步 stop slave ,然后再来看具体错误是什么
# 看 master mysql-bin.000013 文件
# 先把 binlog 转化成 sql
hadoop001:mysqladmin:/usr/local/mysql/arch:>mysqlbinlog --no-defaults --base64-output=decode-rows -v -v mysql-bin.000013 > ../1.sql
# 查看pos 是在 9:17:52 分钟发生
hadoop001:mysqladmin:/usr/local/mysql/arch:>cat ../1.sql | grep "end_log_pos 103710"
#191119 9:17:52 server id 1739 end_log_pos 103710 CRC32 0x6aaf1e91 Update_rows: table id 305 flags: STMT_END_F
hadoop001:mysqladmin:/usr/local/mysql/arch:>more ../1.sql
#191119 9:17:52 server id 1739 end_log_pos 103710 CRC32 0x6aaf1e91 Update_rows: table id 305 flags: STMT_END_F
### UPDATE `rz_db`.`wc_offset`
### WHERE
### @1='eebce1812c5c80033d7e024be4f73800' /* VARSTRING(32) meta=32 nullable=0 is_null=0 */
### @2='wc' /* VARSTRING(64) meta=64 nullable=1 is_null=0 */
### @3='sscOffset' /* VARSTRING(64) meta=64 nullable=1 is_null=0 */
### @4=0 /* INT meta=0 nullable=1 is_null=0 */
### @5=8 /* LONGINT meta=0 nullable=1 is_null=0 */
### SET
### @1='eebce1812c5c80033d7e024be4f73800' /* VARSTRING(32) meta=32 nullable=0 is_null=0 */
### @2='wc' /* VARSTRING(64) meta=64 nullable=1 is_null=0 */
### @3='sscOffset' /* VARSTRING(64) meta=64 nullable=1 is_null=0 */
### @4=0 /* INT meta=0 nullable=1 is_null=0 */
### @5=10 /* LONGINT meta=0 nullable=1 is_null=0 */
看上面sql是更新 partiton=0 数据的 offset=10,那为何会发送错误呢?难道 slave 表里没有 partiton=0 数据数据?
# slave
mysql> select * from wc_offset;
+----------------------------------+-------+-----------+----------+--------+
| primaryKey | topic | groupid | partiton | offset |
+----------------------------------+-------+-----------+----------+--------+
| 46a5760632f2b517aa348efd07883f31 | wc | sscOffset | 1 | 6 |
+----------------------------------+-------+-----------+----------+--------+
1 row in set (0.00 sec)
slave 还真没有这条数据(为何没有?手动删除的才能复现故障,所以千万不要在 slave 表做删除操作),导致在更新时出错了。问题找到了,该如何修复呢?
# slave 设置 sql_slave_skip_counter
mysql> set global sql_slave_skip_counter=1;
# 重新开启 slave
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: hadoop001
Master_User: repluser
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000013
Read_Master_Log_Pos: 420720
Relay_Log_File: relay-log.000011
Relay_Log_Pos: 74942
Relay_Master_Log_File: mysql-bin.000013
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
.....
sql_slave_skip_counter 就能修复,我们一起来看看原理吧。 SET GLOBAL sql_slave_skip_counter = N 跳过N 个 event,event 的范围跟表有关系
- 非事务表:
- 每个 event 对应一个 sql
- 事务表:
- 每一个event 对应事务,无论事务是对应几条 sql;但若是发生错误的sql 是第一条语句,而我们想继续同步同个事务里的后几条语句,就需要用 ` slave_exec_mode ` 参数(设置 sql_slave_skip_counter 是会跳过整个事务)。
拓展
主从从
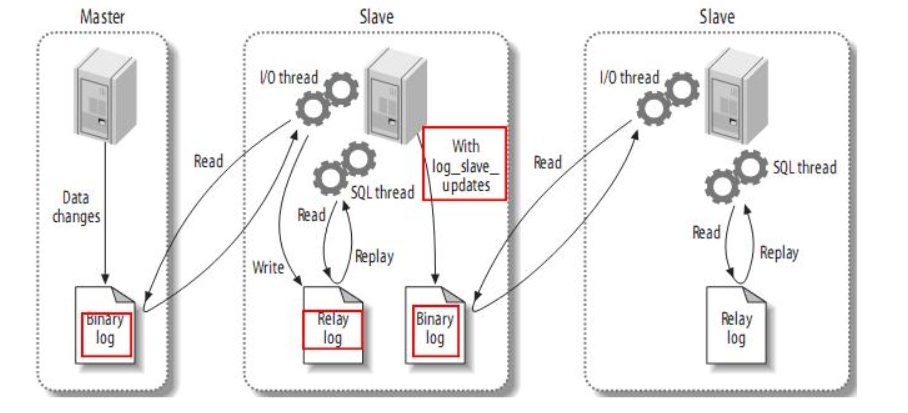
其中一个节点既要当从点也要当下一个从点的主节点,那么也是需要创建复制用户来访问;另外在 my.cnf 特别关注的配置
# 1 设置 从机日志才会写入 binlog,这样从从机才能获取 binlog
log_slave_updates=1
其他几种模式的主从模式该如何操作?