在上一节 大致了解 HBase 框架,本节补充知识点。
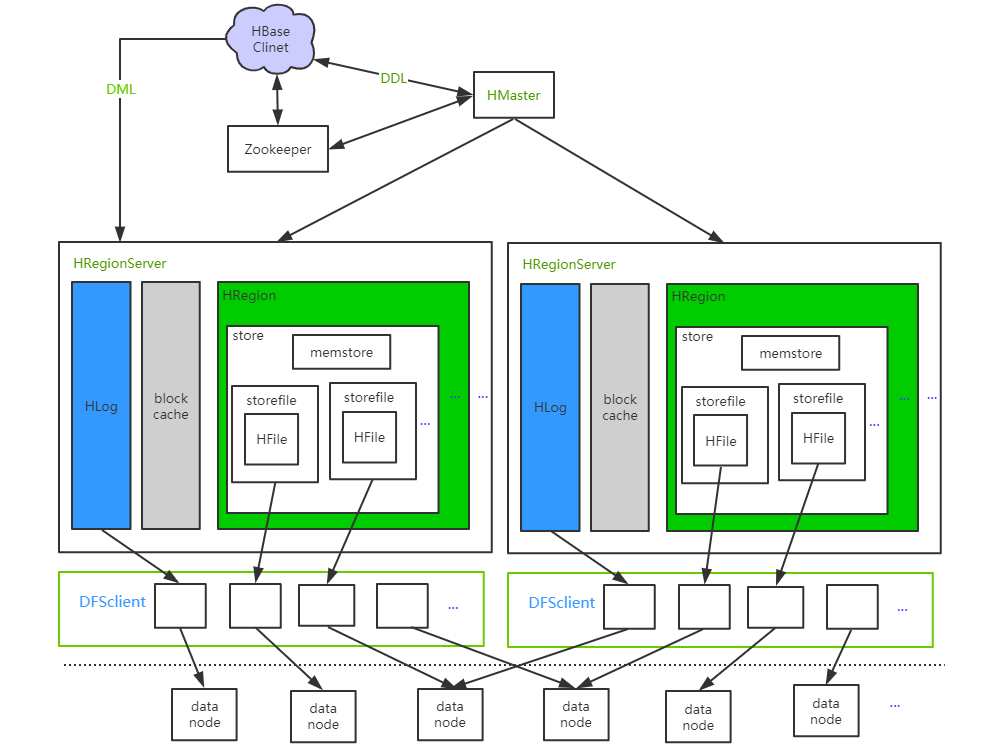
HLog:Write Ahead Log,预写日志(节点上所有region 的写操作)memstore:先写 HLog,再写memStore- 超过阈值会 flush 成一个
storeFile(flush 影响性能) - 当
storeFile文件数量增加到一定阈值,会触发 compaction 合并(会发生GC)
- 超过阈值会 flush 成一个
storeFile:小的file 合并成大文件,文件大小超过阈值又会分裂blockCache:读缓存,RegionServer上所有 region 共享;系统启动时完成初始化工作
写流程
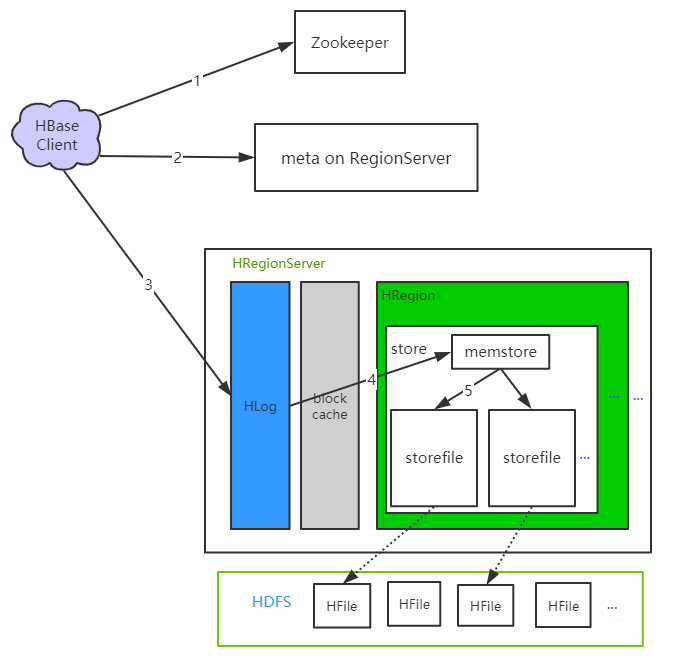
写流程不经过 HMaster
- Clinet 向zk
/hbase/meta-region-server,获取 hbase:meta 表所在的 RS 节点 - 向meta RS 获取
hbase:meta,并根据rowkey找到对应的 RS 节点和 Region - 写请求发送到对应 RS ,依次写入 HLog 以及对应的 memstore
- memstore 超过阈值,会异步 flush 成 storeFile
读流程
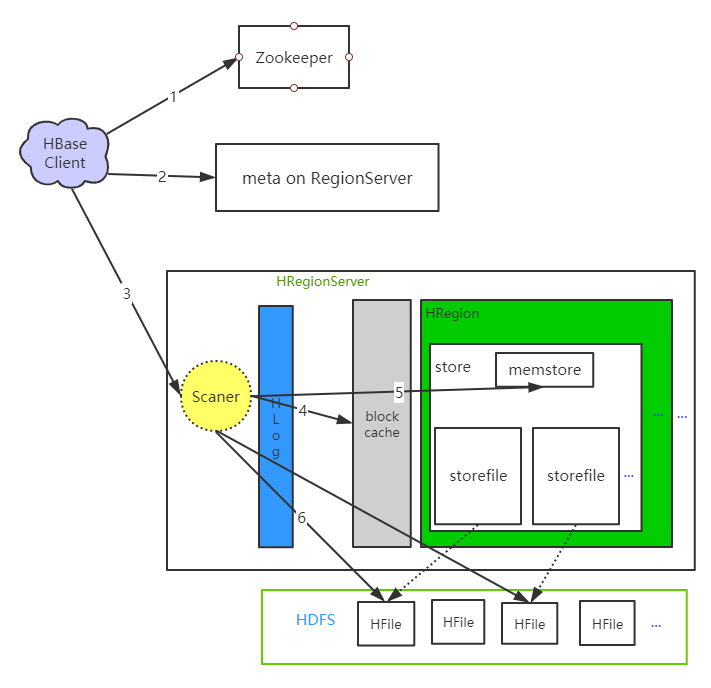
写流程不经过 HMaster
- Clinet 向zk
/hbase/meta-region-server,获取 hbase:meta 表所在的 RS 节点 - 向meta RS 获取
hbase:meta,并根据rowkey找到对应的 RS 节点和 Region,缓存在本地 - 将读请求发送到对应的RS 节点进行处理
- 先在
memstore读取数据,找不到则去blockcache读取,再查不到去HFile。
读取的优先级 memstore <— blockcache <— HFile,如果到HDFS 上读取显然是慢了,为了提高读取速度,可以适当加大 blockcache 容量(基于此有些人会认为 HBase 重写轻读,这显然是不合适的)。为了提高读取速度想使用 blockcache ,先确认在表列簇属性 BLOCKCACHE 是否开启,默认为 true。
上面的步骤只是读取到对应 rowkey 数据,其实在这之后是还有一步需要处理的。当数据有多版本下需要筛选出最新数据;数据有 delete 时需要去除。写数据时只管写,而读数据可能要跨region 获取且结果还要处理,显然对于 HBase 是重写轻读。
调优
总所周知,memstore 超过阈值会 flush 成 storefile,sorefile 可能会历经合并、分割,region 也可能被分割。这些都是需要参数去设置,也是生产上的调优点。
flush
HBase 会在如下几种情况下触发 flush 操作
- memstore 级别:
- region 中任意一个 memstore 大小超过阈值(
hbase.hregion.memstore.flush.size默认128M),就会触发flush;生产上该参数可适当调成倍数。
- region 中任意一个 memstore 大小超过阈值(
- region 级别:
- 当region 中所有 memstore 大小之和超过
hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multipiler(默认是2),触发 flush;生产中 multipiler 可设置为4,列簇一般不超过3,这样region级别的 flush 就不会触发
- 当region 中所有 memstore 大小之和超过
- RegionServer 级别:这个层次发生 flush 是灾难性的,要避免
RegionServer java heap:RegionServer java 堆大小hbase.regionserver.global.memstore.sizeorhbase.regionserver.global.memstore.upperLimit:高水位线,regionserver heap 中供 memstore 占用的总大小,默认0.4hbase.regionserver.global.memstore.size.lower.limitorhbase.regionserver.global.memstore.lowerLimit:低水位线系数,默认0.95- 当 regionserver 的所有的 memstore 的 size 之和,超过低水位线(RS heap * upperlimit * lower);RS 强制 flush,从 memstore 最大的
region开始,直到总的 memstore 之和降到水位线之下。 - 达到低水位线之后如果继续频繁写,会达到高水位线(RS heap * upperlimit);此时 RS 阻塞读写,强制 flush 直至降到低水位线之下。
- HLog:
- ` hbase.regionserver.maxlogs
:HLog 文件大小超过阈值,会触发Regionsflush,经验值32 * 128M=4G`
- ` hbase.regionserver.maxlogs
- 定期 flush:
- ` hbase.regionserver.optionalcacheflushinterval ` :默认为1小时,如果interval 时间内 Region 都没有flush,则自动去flush(设置为0则关闭,单位是ms);为防止一次性有过多memstore flush,会有0-5分钟延迟;检测 region 是否有 flush 是
RegionServer中 ` PeriodicMemStoreFlusher ` 线程来实施
- ` hbase.regionserver.optionalcacheflushinterval ` :默认为1小时,如果interval 时间内 Region 都没有flush,则自动去flush(设置为0则关闭,单位是ms);为防止一次性有过多memstore flush,会有0-5分钟延迟;检测 region 是否有 flush 是
- 手动:
- shell 命令执行
flush 'table name'orflush 'region name',分别对表或者Region flush。
- shell 命令执行
合并
合并可分为 HFile 和 Region
HFile
上一段描述了何时会将 memstore 落盘成 HFile,时间久了会生成很多个 HFile,这不利于 HBase 读请求。此时 HBase 会去将小 HFile合并成大的 HFile(若都是 memstore 级别 flush 是不会形成小文件的)。
合并操作主要是在一个Store里边找到需要合并的 HFile,然后把它们合并起来,合并在大体意义上有两大类Minor Compation 和 Major Compaction:
Minor Compaction:将 store 中**多个HFile **合并成一个 HFile,期间会将达到 TTL(默认3个月)会被移除,触发频率很高。Major Compaction:将 store 中所有 HFile **合并成一个 HFile,期间将标记为删除**的和超过maxVersion 的数据移除。频率较低(默认7天)但性能消耗很大,最好手动控制防止出现在业务高峰期。hbase.hregion.majorcompaction:默认7天,生产中设置为0,不启用然后手动hbase.hregion.majorcompaction.jitter:合并时间随机范围,默认0.5 天- 合并策略:当 memstore flush 成 HFile 需要做合并判断
- 当HFile 大小小于 ` hbase.hstore.compaction.min.size ` (若无设置使用
hbase.hregion.memstore.flush.size),则该文件加入合并队列 - 当HFile 大小小于 ((所有文件大小 - 该文件大小) * 例子因子)也加入合并队列
- 当合并队列里的文件数大于 ` hbase.hstore.compaction.min `(默认为3),则会进行合并
- 若合并队列里的文件数还大于 ` hbase.hstore.compaction.max
(默认为10),那么需要将**合并队列拆分**,当拆分后的队列文件数还大于hbase.hstore.compaction.min`,那么该队列里的问价进行合并
- 当HFile 大小小于 ` hbase.hstore.compaction.min.size ` (若无设置使用
拆分
拆分是指对于一个 大的Region 拆分为几个小的 Region。
RowKey
rowkey 设计最主要的是打散数据,不要存在热点问题;高频查询的字段,尽可能的放到 rowkey 中。rowkey 设计时越短越好,每条记录都有rowkey ,当数据量很大时光rowkey 就会占据很大空间。
“加盐”
HBase 创建盐表:
create ‘ruozesalt’, ‘order’, SPLITS => [‘a’, ‘b’, ‘c’, ‘d’],
插入数据时加随机前缀
put ‘ruozesalt’,’b-k300’, ‘order:orderno’,’v300
可将数据打散。但这种方式第一个 Region 必定是空的,消耗了不必要的内存(hbase.hregion.memstore.mslab.chunksize 控制每个 Region 初始大小,默认2M)。