本节深入源码去理解 Flink + Kafka 实现 Exactly Once ( At Least Once 只是 barrier 无需对齐)的原理。相对于 Spark 而言, Flink 的 state 是很大亮点。Flink 可以将算子的每一步状态都记录下来,然后通过 checkpoint 持久化。当程序异常退出或者升级时,可以通 checkpoint 恢复到以前的状态继续运行。这里可以简单的介绍 checkpoint 运行机制(Apache Flink 进阶教程(三):Checkpoint 的应用实践):
- JobManager 中的 Checkpoint Coordinator 向所有 Source 发送 trigger Checkpoint
- Source 向下游 task 广播 barrier
- 下游 task 算子当前 event 执行结束后先暂停,接着先将 barrier 继续向下游传递,然后将 state 备份将地址( state handle) 通知到给 Checkpoint Coordinator,最后继续处理下一个 event 的
- Sink 节点也会保存 state ,并将地址通知给 Checkpoint Coordinator
- 当 Checkpoint Coordinator 集齐所有 task 的 task handle之后,会整合成 completed Checkpoint Meta 并持久化到后端(Memery、FS、Rocksdb)。至此,一个 barrier 的 checkpoint 完成。
Checkpoint 机制保证在算子运算过程中实现 Exactly Once,那 Source 和 Sink 端的是如何实现呢?
Sink
以 Kafka Sink 为例,介绍 Flink 的实现方式。数据输出时需要保证每个数据都成功,但在分布式环境中每个 task 只能感知自身。由此引出协调者,可以去感知所有 task 状态并决定后续如何处理。Flink 实现的是 Two-Phase Commit协议:
- 所有 task 向协调者发送 preCommit 结果;
- 协调者确认所有 task 结果都成功才向 task 发送
commit,否则发送回滚操作。
Flink 的 TwoPhaseCommitSinkFunction 是基于上述的二阶段提交实现。
/**
This is a recommended base class for all of the {@link SinkFunction} that intend to implement exactly-once semantic
**/
public abstract class TwoPhaseCommitSinkFunction<IN, TXN, CONTEXT>
extends RichSinkFunction<IN>
implements CheckpointedFunction, CheckpointListener {
// 处理每一条数据
protected abstract void invoke(TXN transaction, IN value, Context context) throws Exception;
// 开始一个事务,返回事务信息的句柄
protected abstract TXN beginTransaction() throws Exception;
// 预提交(即提交请求)阶段的逻辑
protected abstract void preCommit(TXN transaction) throws Exception;
// 正式提交阶段的逻辑
protected abstract void commit(TXN transaction);
// 取消事务,Rollback 相关的逻辑
protected abstract void abort(TXN transaction);
}
public interface CheckpointedFunction {
// checkpoint 时执行
void snapshotState(FunctionSnapshotContext context) throws Exception;
// rich function open函数之前 调用
/**
* StreamTask.java
* public final void invoke() {
* initializeState();
* openAllOperators();
*/
void initializeState(FunctionInitializationContext context) throws Exception;
}
public interface CheckpointListener {
// 一个 barrier checkpoint 成功后,回调函数
void notifyCheckpointComplete(long var1) throws Exception;
}
整体执行流程如下:
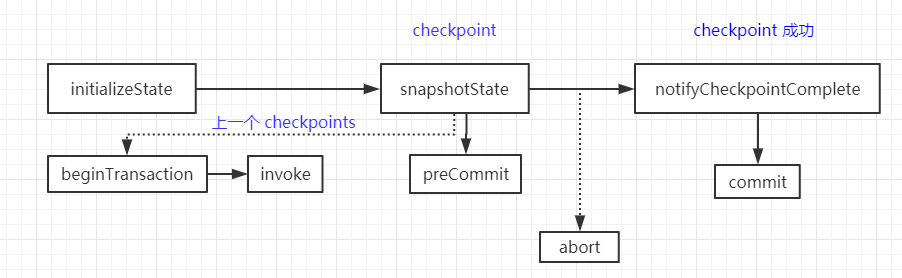
由上可知,一次 checkpoint 才会发送写一次数据,这一定程度会导致数据延迟,需要合理设置 checkpoint 间隔(太短频繁 checkpoint 压力打,太长数据延迟严重)。
以下是源码中涉及到几个函数调用
// TwoPhaseCommitSinkFunction
public void snapshotState(FunctionSnapshotContext context) throws Exception {
...
preCommit(currentTransactionHolder.handle);
...
currentTransactionHolder = beginTransactionInternal();
...
}
// beginTransaction
private TransactionHolder<TXN> beginTransactionInternal() throws Exception {
return new TransactionHolder<>(beginTransaction(), clock.millis());
}
// notifyCheckpointComplete
public final void notifyCheckpointComplete(long checkpointId){
commit(pendingTransaction.handle);
}
// FlinkKafkaProducer
public class FlinkKafkaProducer<IN>
extends TwoPhaseCommitSinkFunction{
...
public void snapshotState(FunctionSnapshotContext context) throws Exception {
super.snapshotState(context);
...
nextTransactionalIdHintState.add(new FlinkKafkaProducer.NextTransactionalIdHint(
getRuntimeContext().getNumberOfParallelSubtasks(),
nextFreeTransactionalId));
}
// preCommit
protected void preCommit(FlinkKafkaProducer.KafkaTransactionState transaction) {
...
// transaction.producer.flush();
flush(transaction);
}
// beginTransaction
protected FlinkKafkaProducer.KafkaTransactionState beginTransaction() {
FlinkKafkaInternalProducer<byte[], byte[]> producer = createTransactionalProducer();
producer.beginTransaction();
return new FlinkKafkaProducer.KafkaTransactionState(producer.getTransactionalId(), producer);
}
// invoke
public void invoke(FlinkKafkaProducer.KafkaTransactionState transaction, IN next, Context context){
record = new ProducerRecord<>(
targetTopic,
flinkKafkaPartitioner.partition(next, serializedKey, serializedValue, targetTopic, partitions),
timestamp,
serializedKey,
serializedValue);
...
transaction.producer.send(record, callback);
}
// commit
protected void commit(FlinkKafkaProducer.KafkaTransactionState transaction) {
// kafkaProducer.commitTransaction();
transaction.producer.commitTransaction();
}
// abort
protected void abort(FlinkKafkaProducer.KafkaTransactionState transaction) {
if (transaction.isTransactional()) {
transaction.producer.abortTransaction();
recycleTransactionalProducer(transaction.producer);
}
}
}
以上机制保证 Flink -> Kafka 所有 task 都能正常走到 commit,但若是在 commit 时有些 task 出现异常呢?
Commit 期间如果出现其中某个并行度出现故障,JobManager 会停止此任务,向所有的实例发送通知,各实例收到通知后,调用 close 方法,关闭 Kafka 事务 Producer。 checkpoint 会将 Commit 的事务保存在状态里 ,重启时没有commit 成功的继续 commit。
// FlinkKafkaProducer
public void close() throws FlinkKafkaException {
currentTransaction.producer.close();
}
Source
Kafka -> Flink 关键是维护好
offset,显然是把offset当作 state ,checkpoint 持久化存储。
// FlinkKafkaConsumerBase
// 运行时针对单个 Operator 实例(并行度) 保存的offset
private transient volatile TreeMap<KafkaTopicPartition, Long> restoredState;
/** Accessor for state in the operator state backend. */
// offset state checkpoint 时状态,ListState(OperateState)
// 一个Flink 并行度可能消费多个 Kafka 分区 (Spark 中任务并行度和Kafka 分区一致)
private transient ListState<Tuple2<KafkaTopicPartition, Long>> unionOffsetStates;
// FlinkKafkaConsumerBase
// ------------------------------------------------------------------------
// Checkpoint and restore
// ------------------------------------------------------------------------
@Override
public final void initializeState(FunctionInitializationContext context){
// 获取 state
OperatorStateStore stateStore = context.getOperatorStateStore();
// subTask 获取全量 state,包含所有分区的 offset
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint<Tuple2<KafkaTopicPartition, Long>>() {})));
// populate actual holder for restored state
for (Tuple2<KafkaTopicPartition, Long> kafkaOffset : unionOffsetStates.get()) {
restoredState.put(kafkaOffset.f0, kafkaOffset.f1);
}
}
每个 Operate 实例的 offset 问题解决了,那 Flink 并行度和Kafka 分区是如何分配的呢?
// FlinkKafkaConsumerBase
public void open(Configuration configuration) {
...
final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions();
...
for (Map.Entry<KafkaTopicPartition, Long> restoredStateEntry : restoredState.entrySet()) {
// restoredFromOldState 指从flink 1.2 恢复,当前版本1.9,永远为 false
if (!restoredFromOldState) {
// seed the partition discoverer with the union state while filtering out
// restored partitions that should not be subscribed by this subtask
// 分配分区
if (KafkaTopicPartitionAssigner.assign(
restoredStateEntry.getKey(), getRuntimeContext().getNumberOfParallelSubtasks())
== getRuntimeContext().getIndexOfThisSubtask()){
// 恢复当前subTask 负责分区的 offset
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
} else {// when restoring from older 1.1 / 1.2 state, the restored state would not be the union state;
// in this case, just use the restored state as the subscribed partitions
subscribedPartitionsToStartOffsets.put(restoredStateEntry.getKey(), restoredStateEntry.getValue());
}
}
...
}
// KafkaTopicPartitionAssigner
/*
* Utility for assigning Kafka partitions to consumer subtasks.
* @param partition the Kafka partition
* @param numParallelSubtasks total number of parallel subtasks
*
* @return index of the target subtask that the Kafka partition should be assigned to.
*/
public static int assign(KafkaTopicPartition partition, int numParallelSubtasks) {
int startIndex = ((partition.getTopic().hashCode() * 31) & 0x7FFFFFFF) % numParallelSubtasks;
// here, the assumption is that the id of Kafka partitions are always ascending
// starting from 0, and therefore can be used directly as the offset clockwise from the start index
return (startIndex + partition.getPartition()) % numParallelSubtasks;
}
显然是轮循策略,根据 topic_name 的hash 值和并行数确定 startIndex 然后将分区轮循给 subTask:假设分区数 7,subTask 数 3,startIndex 为2,那么结果就是
| subTask0 | subTask1 | subTask2 | |
|---|---|---|---|
| Kafka 分区 | 1、4 | 2、5 | 0、3、6 |
若任务重启时修改了并行数即 subTask 对应的分区有变化,Flink 能恢复 对应 offset 吗?
| subTask0 | subTask1 | subTask2 | subTask3 | |
|---|---|---|---|---|
| Kafka 分区 | 1、4 | 2、5 | 2、6 | 3 |
由上可知,subTask 原有的分区被打乱,Flink 针对这种情况是如何处理的。
public final void initializeState(FunctionInitializationContext context){
// subTask 获取全量 state,包含所有分区的 offset
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint<Tuple2<KafkaTopicPartition, Long>>() {})));
...
}
public void open(Configuration configuration) {
...
// 第一次获取所有分区数:可以感知 Kafka 的分区变化
// 后续分区分配如常,因为subTask 得到全分区的 offset
final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions();
...
}
initializeState 函数先 restore offset,open 函数再为subTask 分配分区并校准 offset
Kafka 动态新增 分区,Flink 该如何感知?
KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS 参数设置间隔多长时间去检测 Kafka 是否有新增分区
// FlinkKafkaConsumerBase
public void run(SourceContext<T> sourceContext) throws Exception {
...
// KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS 参数判断
if (discoveryIntervalMillis == PARTITION_DISCOVERY_DISABLED) {
kafkaFetcher.runFetchLoop();
} else {
runWithPartitionDiscovery();
}
}
private void runWithPartitionDiscovery() throws Exception {
final AtomicReference<Exception> discoveryLoopErrorRef = new AtomicReference<>();
// 创建 发现Kafka 新分区 线程
createAndStartDiscoveryLoop(discoveryLoopErrorRef);
// 消费 Kafka 数据
kafkaFetcher.runFetchLoop();
...
}
private void createAndStartDiscoveryLoop {
// 间隔 discoveryIntervalMillis 去检测发现新分区添加到 kafkaFetcher
discoveryLoopThread = new Thread(() -> {
try {
// --------------------- partition discovery loop ---------------------
// throughout the loop, we always eagerly check if we are still running before
// performing the next operation, so that we can escape the loop as soon as possible
while (running) {
final List<KafkaTopicPartition> discoveredPartitions;
try {
// 发现新分区
// discoverPartitions 第一次调用会返回当前 subTask 消费的所有分区
// 非第一次调用,则返回当前 subTask 消费的 新分区
discoveredPartitions = partitionDiscoverer.discoverPartitions();
}
...
// no need to add the discovered partitions if we were closed during the meantime
if (running && !discoveredPartitions.isEmpty()) {
// 添加新分区去消费
kafkaFetcher.addDiscoveredPartitions(discoveredPartitions);
}
// do not waste any time sleeping if we're not running anymore
if (running && discoveryIntervalMillis != 0) {
try {
Thread.sleep(discoveryIntervalMillis);
} catch (InterruptedException iex) {
// may be interrupted if the consumer was canceled midway; simply escape the loop
break;
}
}
}
}
...
discoveryLoopThread.start();
}
参考资料
Flink 中如何保证 Exactly Once?