一条 SQL 的执行顺序想必大家都了解:
- from join:数据源
- where:指定条件对记录筛选
- group by:数据分组
- 聚合函数计算
- having:条件筛选,与 group by 搭配使用
- 计算表达式
- select 字段
- order by:结果集排序
(8)SELECT (9) DISTINCT (11) <TOP_specification> <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) WITH {CUBE | ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
以上是执行顺序的规则,但 SQL 最终的执行顺序在原有的基础上会做一些优化。在 Spark 中,Catalyst 就是 SQL 优化的组件。
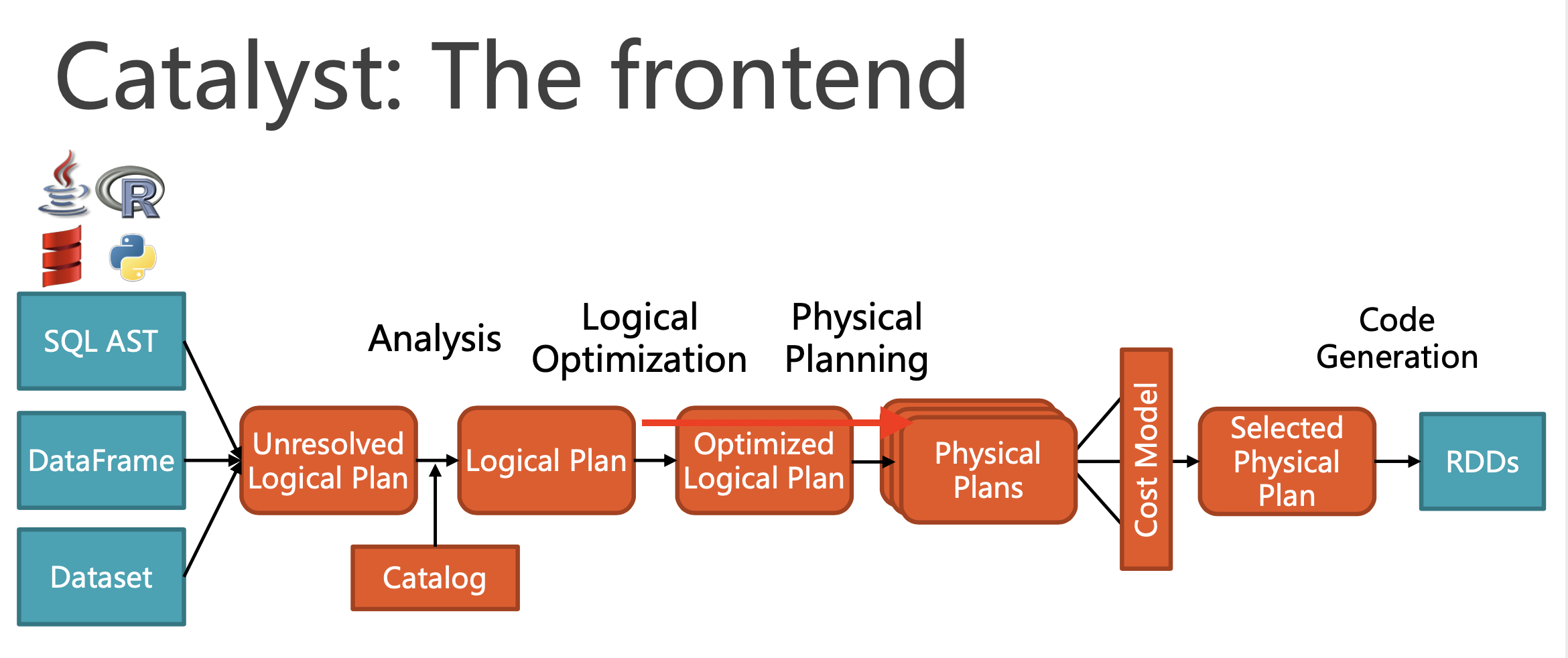
上图是 Catalyst 在 Spark SQL 中的位置,可以简化来看就是对查询计划的优化。
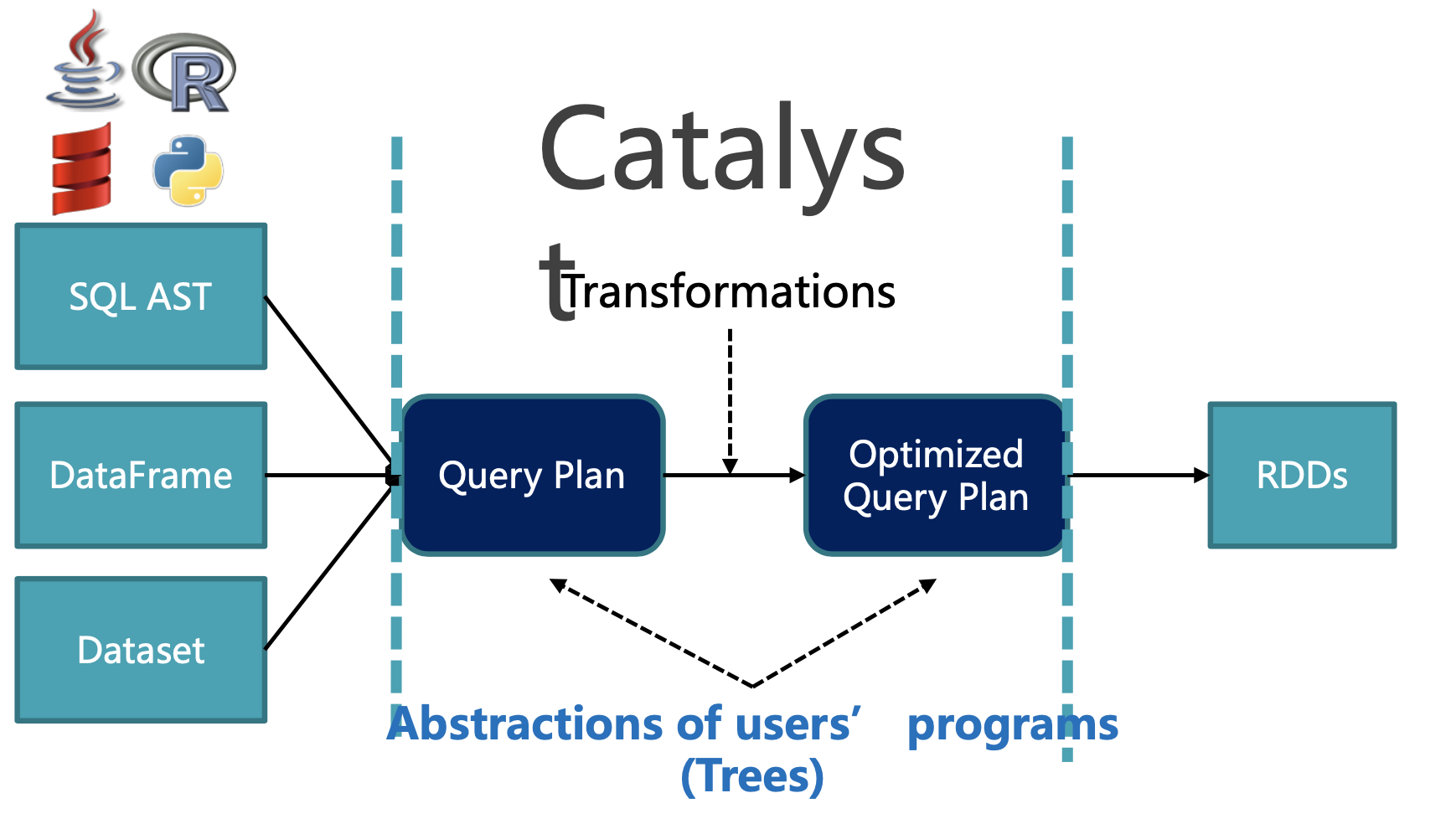
下面以一条有 join 的 SQL 为例,看看 Catalyst 做了那些优化。
SELECT sum(v)
FROM ( SELECT t1.id,
1 + 2 + t1.value AS v
FROM t1 JOIN t2
WHERE t1.id = t2.id AND t2.id > 50 * 1000) tmp
在没有 Catalyst 下,SQL 逻辑和物理计划
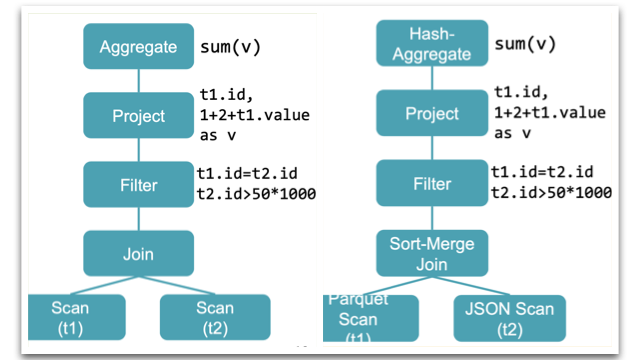
如上图所示,SQL 执行顺序没有做任何调整。
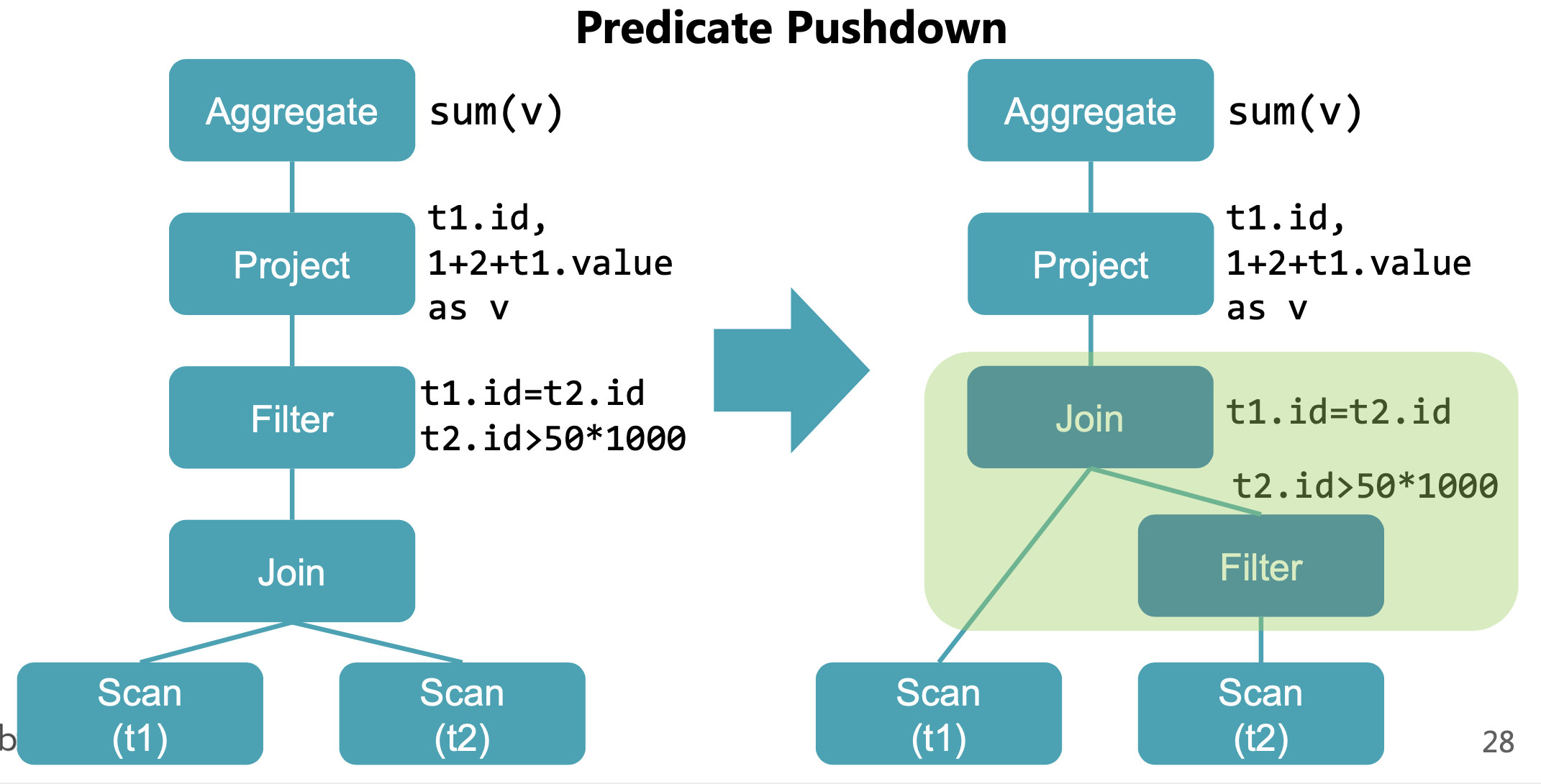
Catalyst 优化
Predicate Pushdown
中文翻译成谓词下推,在 join 前先过滤以减少 shuffle 数据量
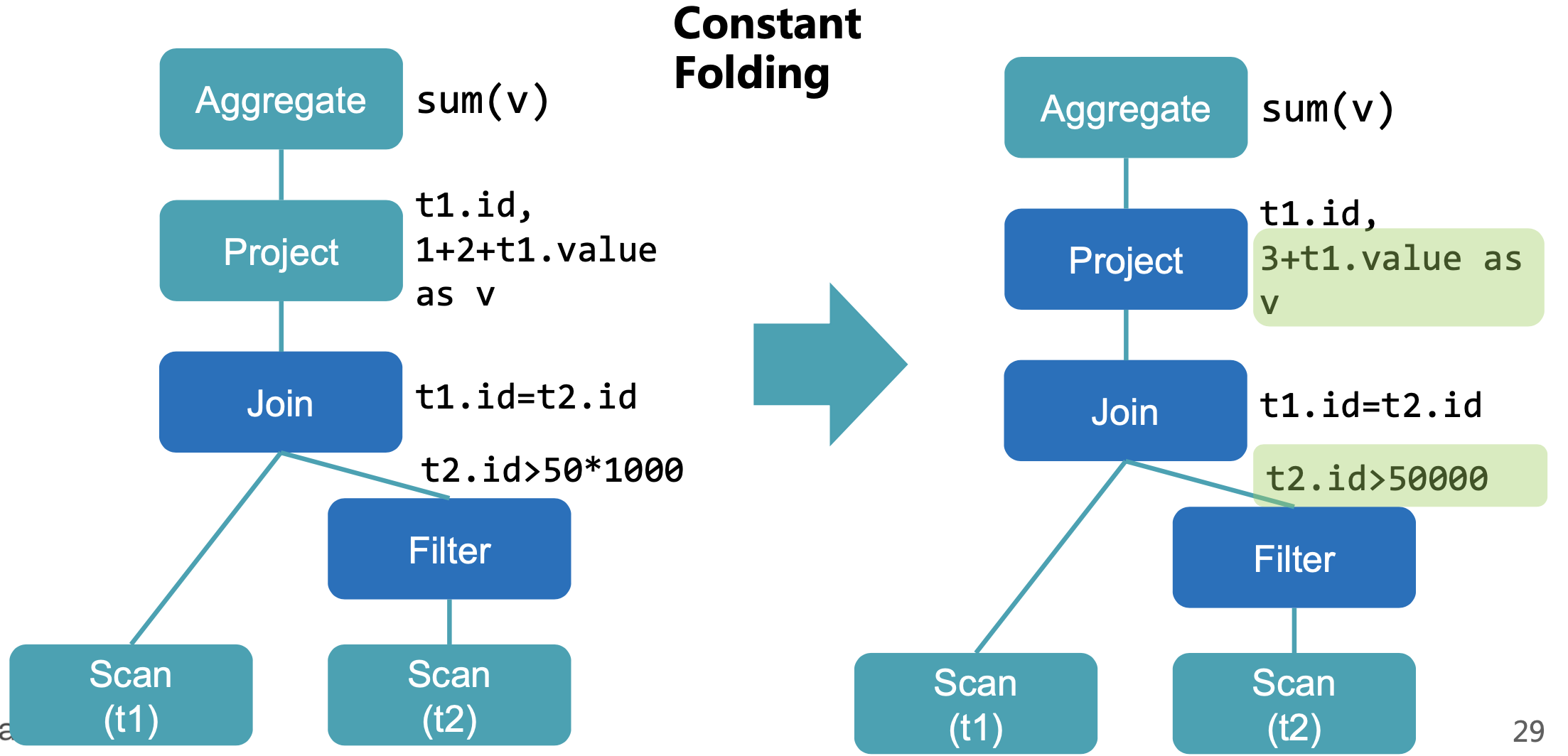
Constant Folding
常量合并,相当于做了预处理,省去每次都要计算常量表达式
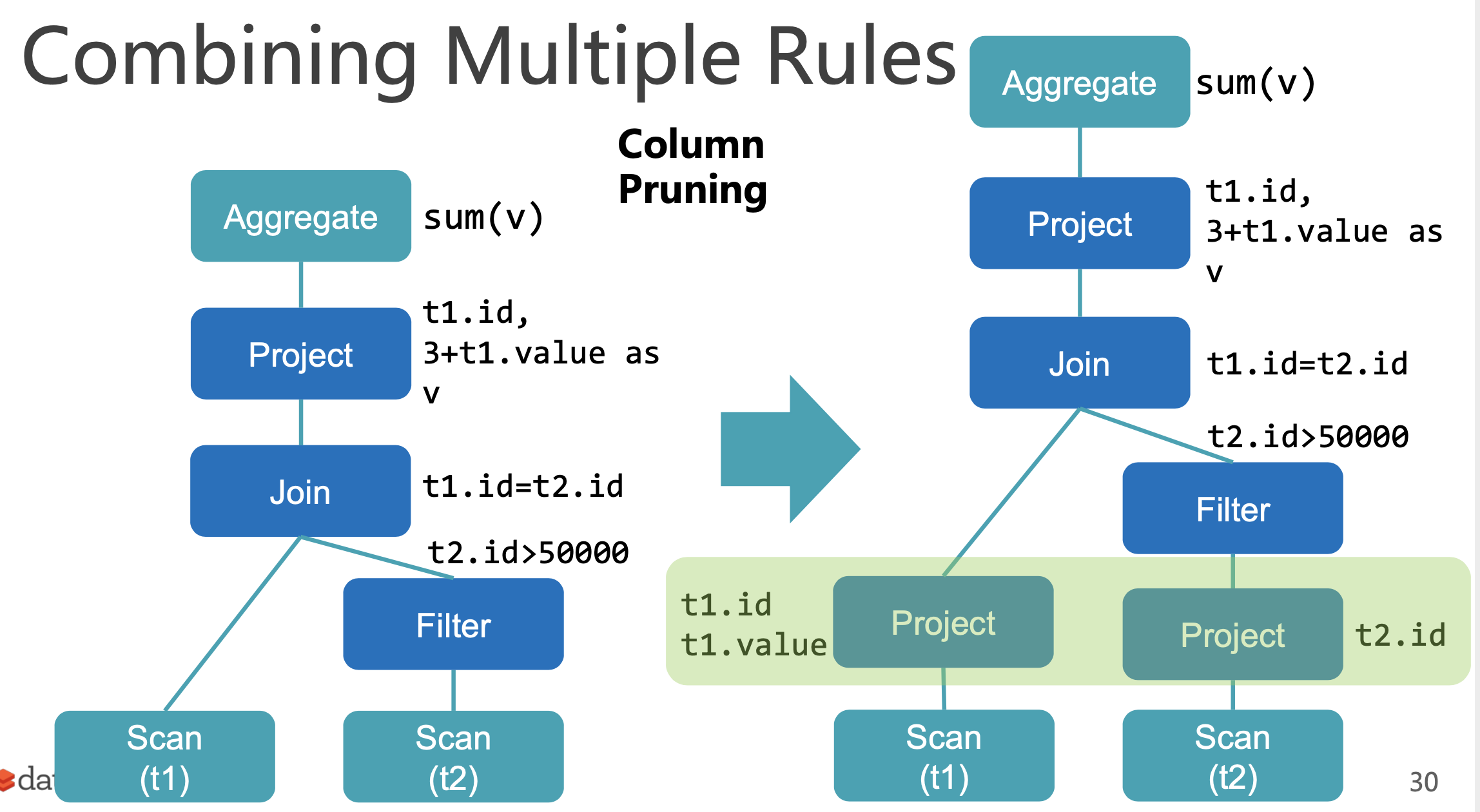
Column Pruning
列裁剪,Scan 时只获取需要的字段,在列式存储下可以减少 I/O 开销。在设计 Spark 外部数据源时,我们有必要去支持列裁剪的功能。
最优逻辑计划
执行顺序做了调整提高整体执行效率

Whole-stage code generation
Spark 1.x 版本中,执行 SQL 的查询策略是基于 Volcano Iterator Model(火山迭代模型)。一个查询会包含多个 Operator,每个 Operator 都会实现一个接口,提供一个 next() 方法,该方法返回 Operator Tree 的下一个 Operator,能够让查询引擎组装任意 Operator,而不需要去考虑每个 Operator 具体的处理逻辑,所以 Volcano Iterator Model 才成为了30年中 SQL 执行引擎最流行的一种标准。但 Volcan 模型相比于手写 Java 代码来说,性能相差一个等级。主要在于 Volcan 模型在执行 Operator 操作是,有以下性能开销
- 虚函数调用(Virtual Function Dispatch):
Volcano Iterator Model至少需要调用一次next()获取下一个Operator,在操作系统层面会被编译为Virtual Function Dispatch,会执行多个CPU指令,并且速度慢。而直接编写的Java代码中没有任何函数调用逻辑。 - 内存缓存:
Volcano Iterator Model将数据交给下一个Operator时,都需要将数据写入内存缓冲,但是在手写代码中,JVM JIT编译器会将这些数据写入 CPU 寄存器,CPU直接从寄存器中读写数据比在内存缓冲中读写数据的性能要高一个数量级。 - 编译器Loop Unrolling:手写代码针对某特定功能使用简单循环,而现代的编译器可以自动的对简单循环进行
Unrolling,生成单指令多数据流(SIMD),在每次CPU指令执行时处理多条数据。而这些优化特点无法在Volcano Iterator Model复杂的函数调用场景中施展。
在上面的技术背景下,Spark 2.x 基于 Tungsten 引擎产生了 Whole-stage code generation 技术。
SQL 语句编译后的 Operator-Tree 中,每个 Operator 不再执行逻辑,而是通过全流式代码生成技术在运行时动态生成代码
whole-stage code generation 技术是从 CPU 密集操作的方面进行性能调优,对 IO 密集操作的层面是无法提高效率(本文只做简单介绍,后续有文章专门展开研究)。以下是 1.x 和 2.x 的性能比对
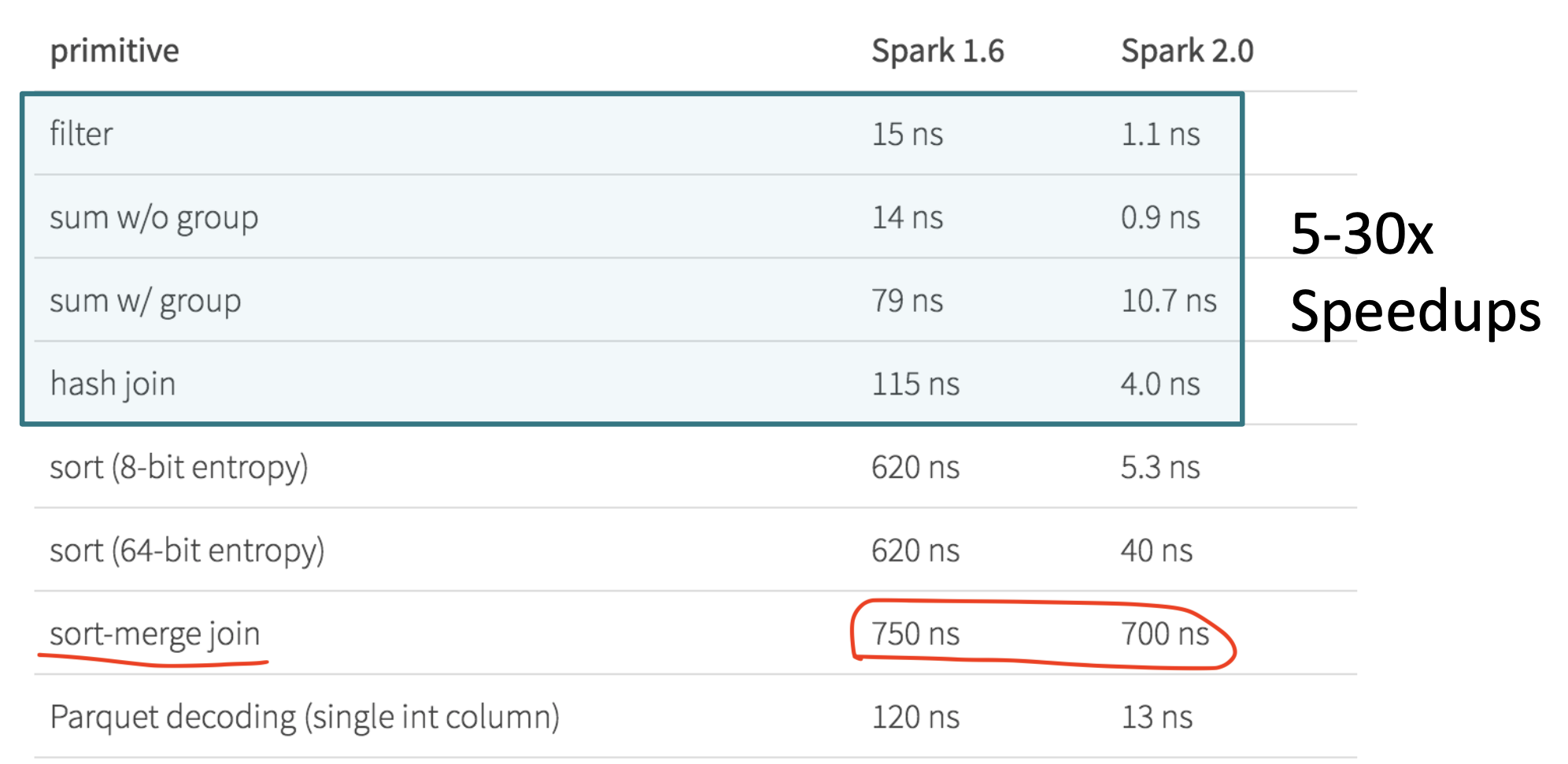
- spark.sql.parquet.enableVectorizedReader:向量化计算,不同于以前单条记录计算,这种模式下是批量计算,性能提升数倍。
参考资料
SQL 查询优化原理与 Volcano Optimizer 介绍