Antlr 是一款强大的语法分析器生成器,可以用来读取、处理、执行和转换结构化文本或二进制文件。通过称为文法的形式化语言描述,Antlr 可以为该语言自动生成词法分析器。生成的语法分析器可以自动构建语法分析树,它是表示文法如何匹配输入的数据结构。Antlr 还可以自动生成树遍历器,用来访问树节点以执行特定的代码。
Antlr 的树遍历器分为监听器和访问者。访问者模式遍历语法树是一种更加灵活的方式,可以避免在文法中嵌入繁琐的动作,使解析与应用代码分离,这样不但文法的定义更加简洁清晰,而且可以在不重新编译生成语法分析器的情况下复用相同的语法,甚至能够采用不同的程序语言来实现这些动作。
Antlr 的应用非常广泛,Hive、Prosto、Spark SQL 等大数据引擎的 SQL 编译模块都是基于 Antlr 构建(Flink 使用 Calcite)。下面通过计算器的例子来了解 Antlr 运行过程。
# antlr4 构建计算器
# 词法单元以大写字母开头
# 语法单元以小写字母开头
grammar Calculator;
line : expr EOF ;
expr : '(' expr ')' # parenExpr
| expr op=('*'|'/') expr # multOrDiv
| expr op=('+'|'-') expr # addOrSub
| FLOAT # float ;
WS : [ \t\n\r]+ -> skip ;
FLOAT : DIGIT+ '.' DIGIT* EXPONENT?
| '.' DIGIT+ EXPONENT?
| DIGIT+ EXPONENT? ;
fragment DIGIT : '0'..'9';
fragment EXPONENT : ('e'|'E') ('+'|'-')? DIGIT+ ;
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
- 问号:零或一个
- 加号:一个或多个
- 星号:零个或多个
- expr 每条规则后面的 “#” 是产生式标签名(Alternative LabelName),起到标记不同规则的作用(会自动生成函数)
- skip 跳过六个特殊字符 “[、 、\t、\n、\r、]”,不做处理
-
“ ” 表示不同的表现,可以简单理解为 “or”,FLOAT 在本例中就有三种表现形式 - fragment 表示这是个词片段,不会生成 token
- 最后四行是加减乘除四个字符加标签,相当于宏定义
规则文件定义好了,该如何执行呢?以 IDEA 为例,先安装 Antlr 插件,然后将文件保存为 Calculator.g4(必须与第一行的字符串相同)。右键下图红色框框的单词选择 Test Rule expr,就可以把左侧的字符串解析成右侧的语法树
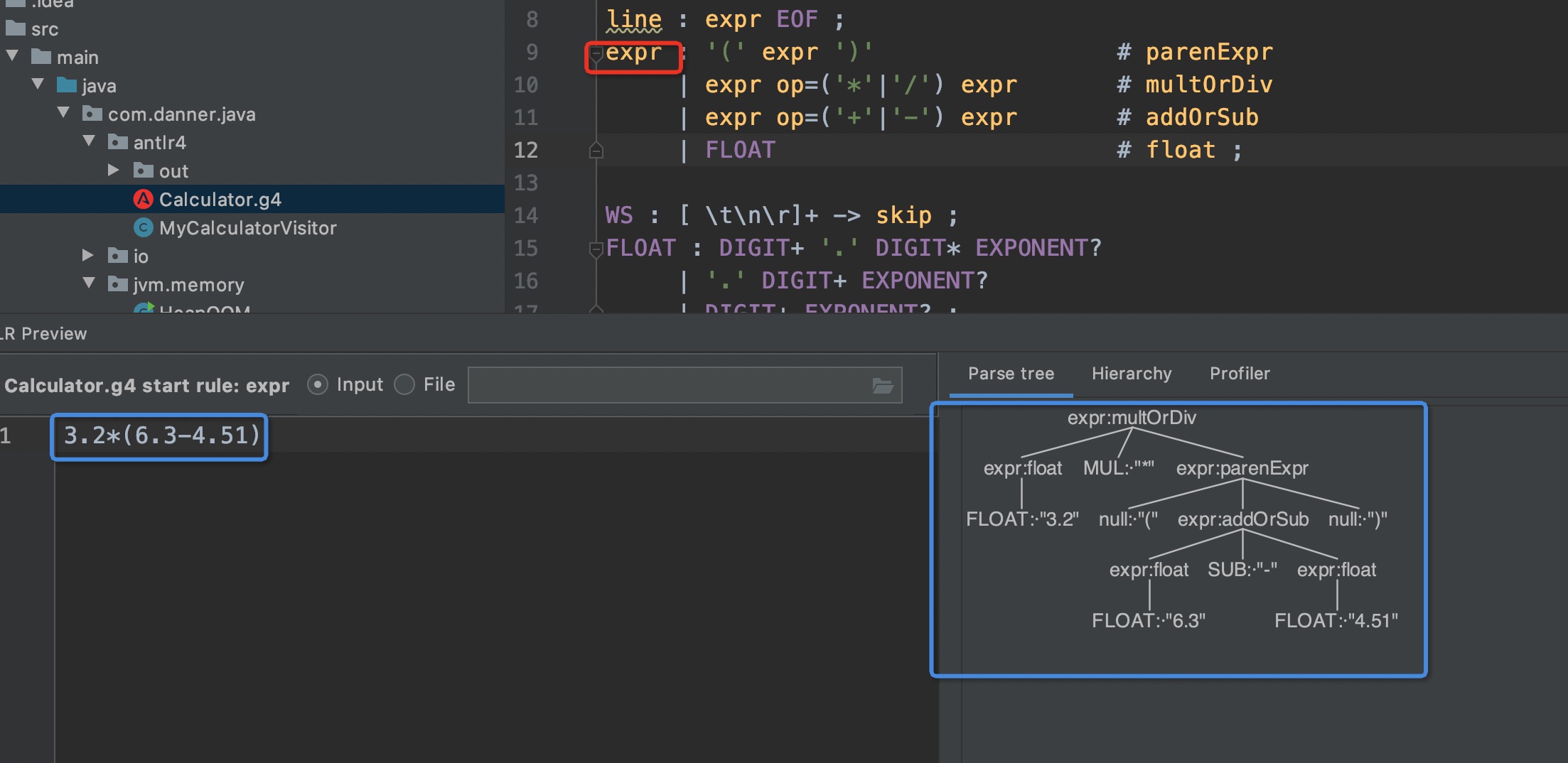
插件可以解析了,按如下步骤编写代码跑案例
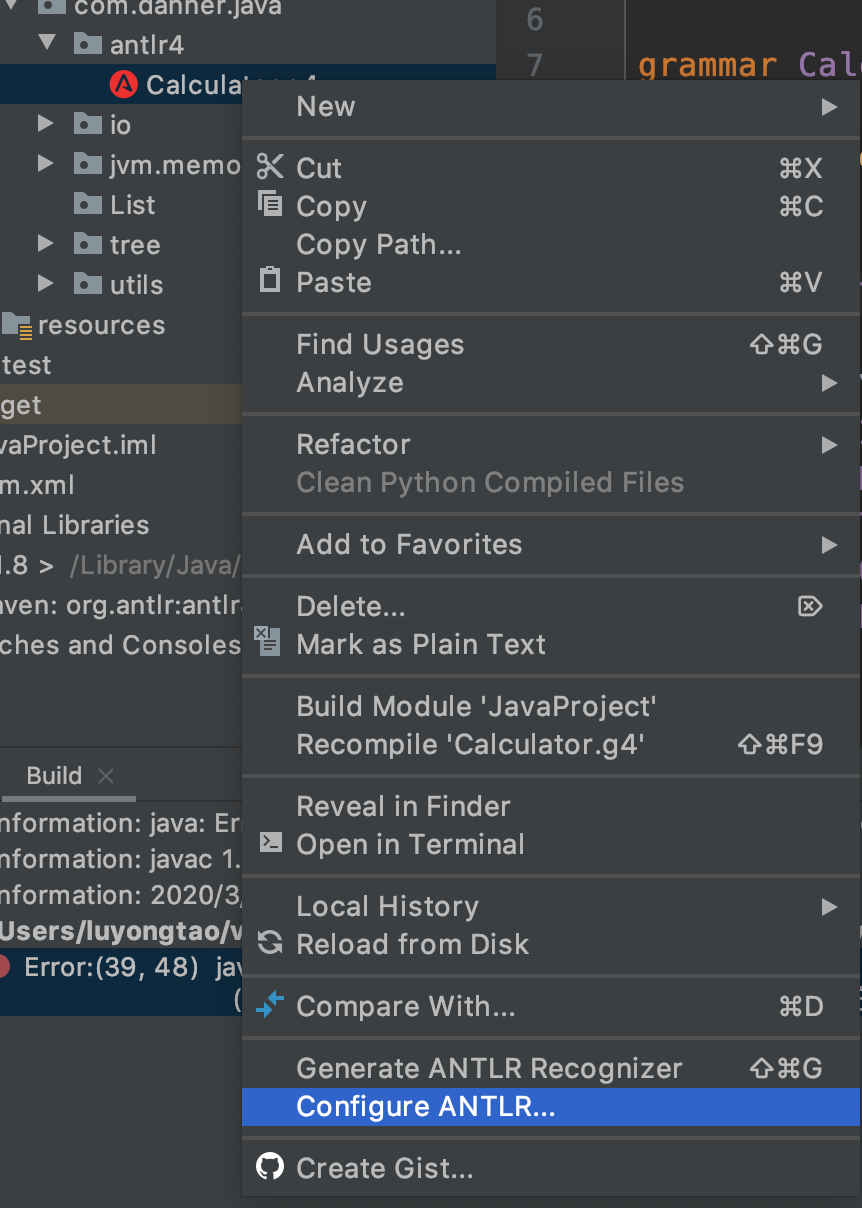
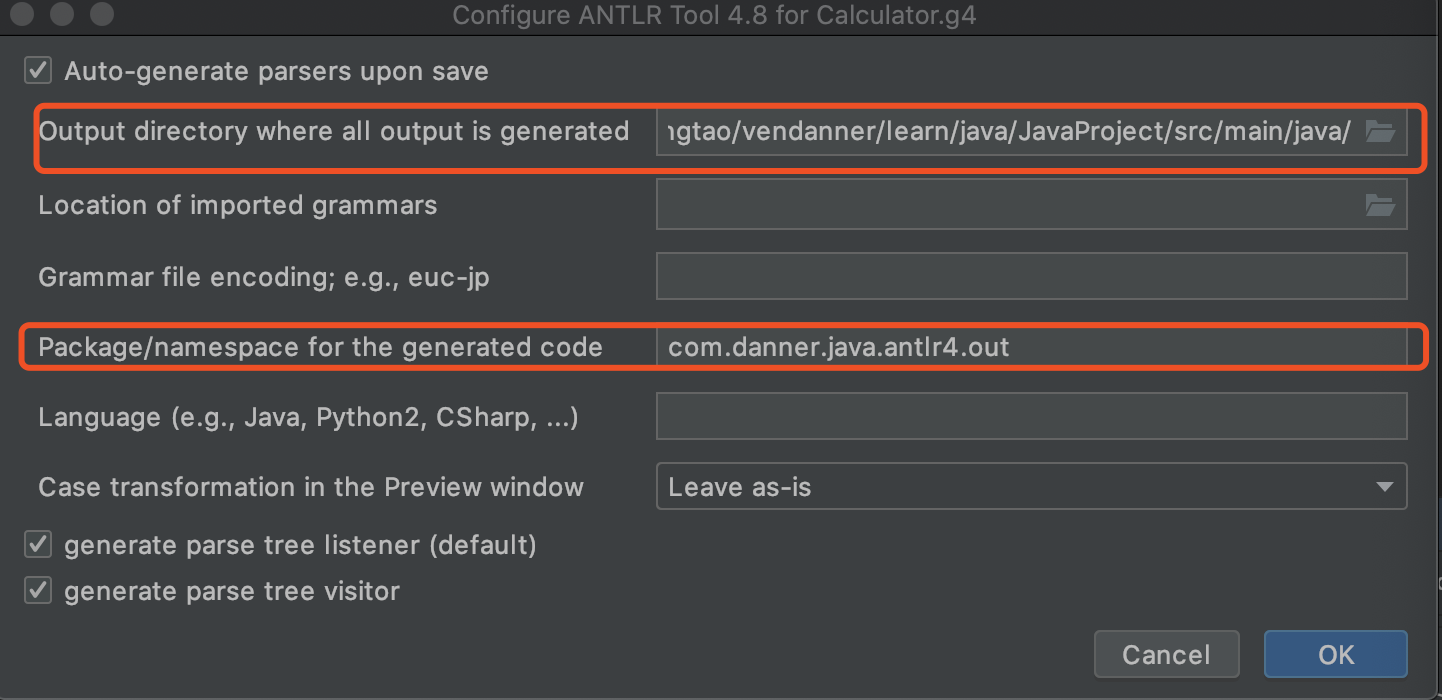
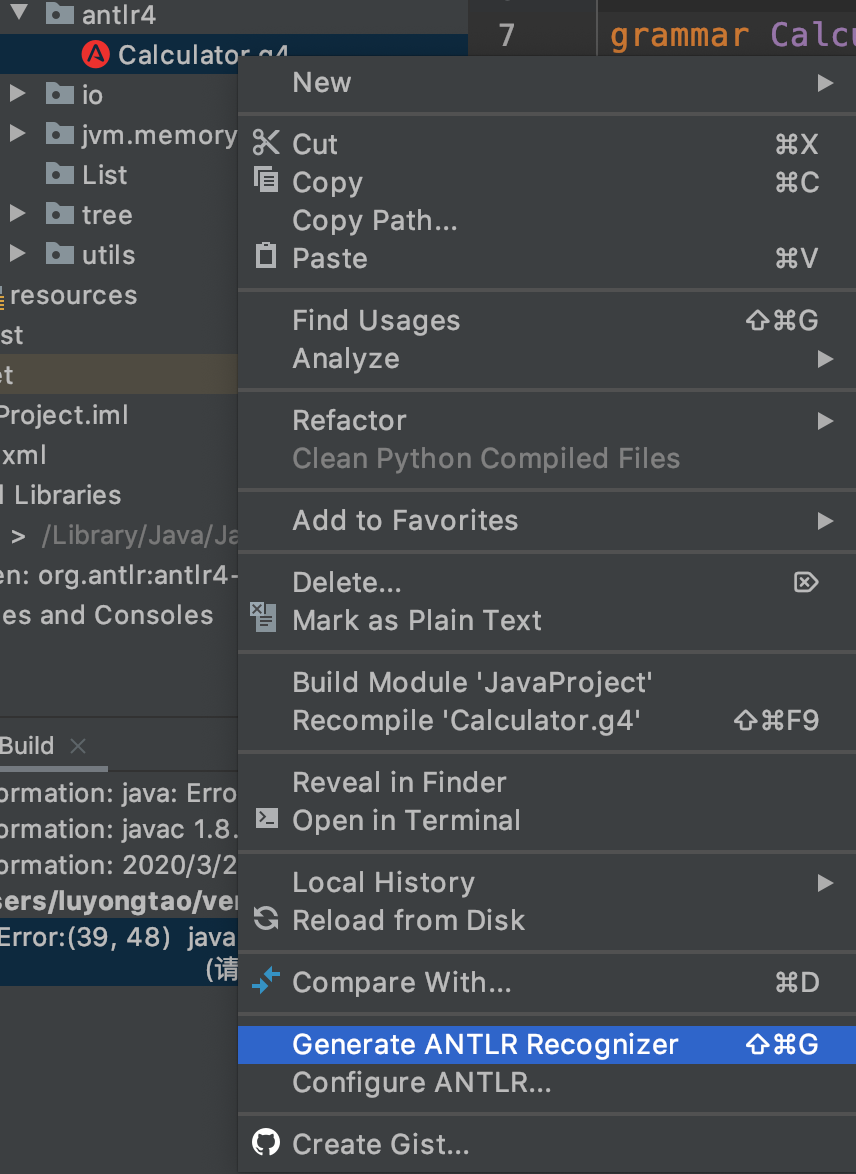
在 out package 下产生文件
- Calculator.tokens 和 CalculatorLexer.tokens 是内部的 token 定义
- CalculatorLexer 是生成的词法分析器
- CalculatorParser 是生成的语法分析器
- CalculatorListener 和 CalculatorBaseListener 对应监听器模式
- CalculatorVisitor 和 CalculatorBaseVisitor 对应访问者模式
基于生成的代码,开发人员只要实现语法树遍历过程中的核心逻辑即可,可以在监听器模式和访问者模式任意选者。Spark SQL 使用 Visitor 方式,本例实现相同模式
public class MyCalculatorVisitor extends CalculatorBaseVisitor<Object> {
@Override
public Float visitAddOrSub(CalculatorParser.AddOrSubContext ctx) {
Object obj0 = visit(ctx.expr(0));
Object obj1 = visit(ctx.expr(1));
if (CalculatorParser.ADD == ctx.op.getType()) {
return (Float)obj0 + (Float)obj1;
} else {
return (Float)obj0 - (Float)obj1;
}
}
@Override
public Float visitMultOrDiv(CalculatorParser.MultOrDivContext ctx) {
Object obj0 = visit(ctx.expr(0));
Object obj1 = visit(ctx.expr(1));
if (CalculatorParser.MUL == ctx.op.getType()) {
return (Float)obj0 * (Float)obj1;
} else {
return (Float)obj0 / (Float)obj1;
}
}
@Override
public Object visitParenExpr(CalculatorParser.ParenExprContext ctx) {
return visit(ctx.expr());
}
@Override
public Object visitFloat(CalculatorParser.FloatContext ctx) {
return Float.parseFloat(ctx.getText());
}
}
看到上面的函数是不是有熟悉的感觉,其实就是产生式标签名,而 CalculatorParser 常量就是最后四行定义的字符。MyCalculatorVisitor 内函数就是实现了对应的加减乘除的逻辑,没有特殊处理。有访问者的实现类之后,继续写 main 方法来 run。
public class CalculatorDemo {
public static void main(String[] args) {
String query = "3.2*(6.3-4.51)";
CalculatorLexer lexer = new CalculatorLexer(new ANTLRInputStream(query));
CalculatorParser parser = new CalculatorParser(new CommonTokenStream(lexer));
MyCalculatorVisitor visitor = new MyCalculatorVisitor();
CalculatorParser.ExprContext expr = parser.expr();
System.out.println(visitor.visit(expr));
}
}
run 之后,控制台输出运算结果 “5.728”,至此整个 demo 运行成功。梳理整个过程
- 写语法文件,定义规则
- 配置目录,基于语法文件生成代码
- 实现相应的语法树遍历过程的逻辑
- 应用程序调用树遍历器解析运行
Spark SQL 中的 sqlBase.g4 就是Antlr4 语法,后续文章会围绕此展开。
参考资料
Spark SQL 内核剖析