Join
Join 操作大多数情况会进行 shffle 操作,而 shffle 很耗时。
Core
- 两个父 RDD 的分区器,子 RDD 都不知道的情况下,拉取两个父 RDD 都会产生 Shuffle,网络开销很大
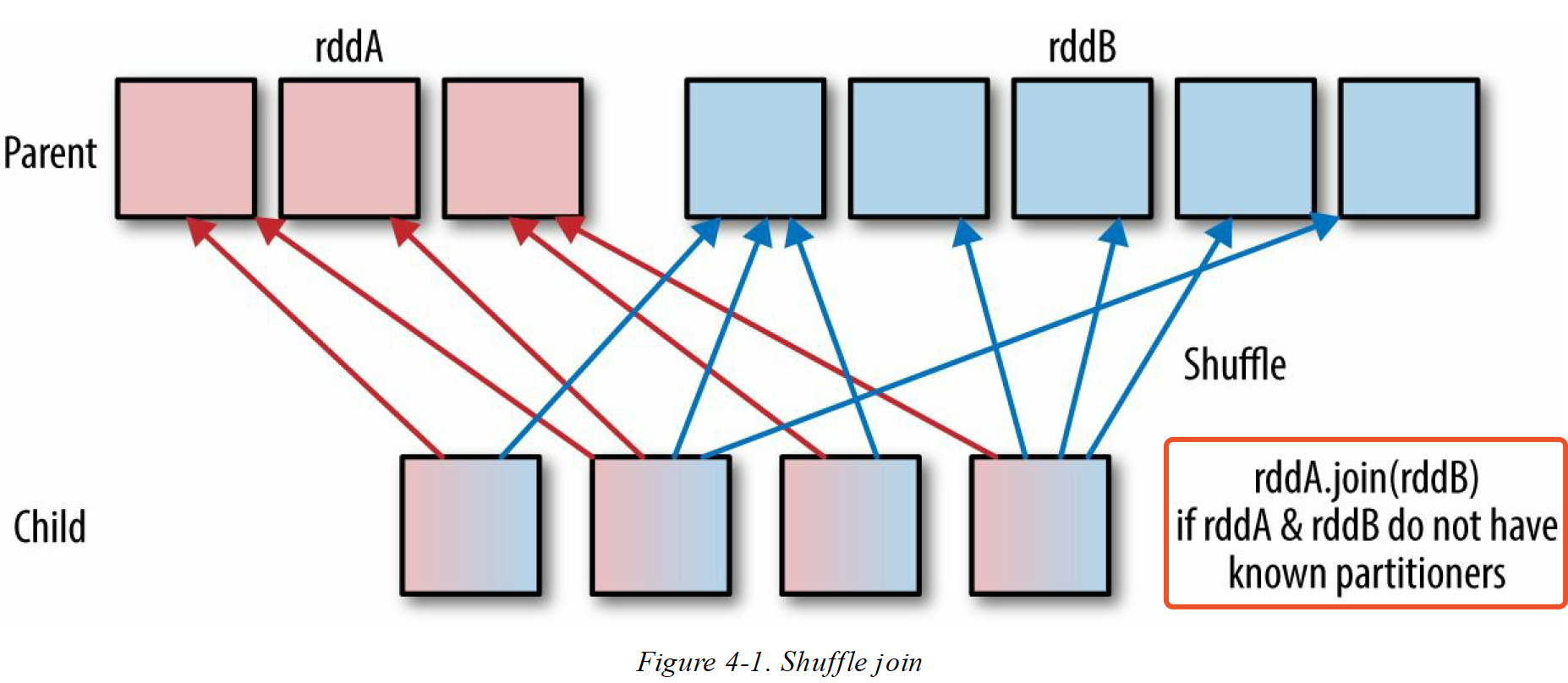
RDD[key,value] Map 操作,会丢失父 RDD 的分区器 (map 操作有可能改变 key 值,spark 定义不再继承 父RDD 分区器)
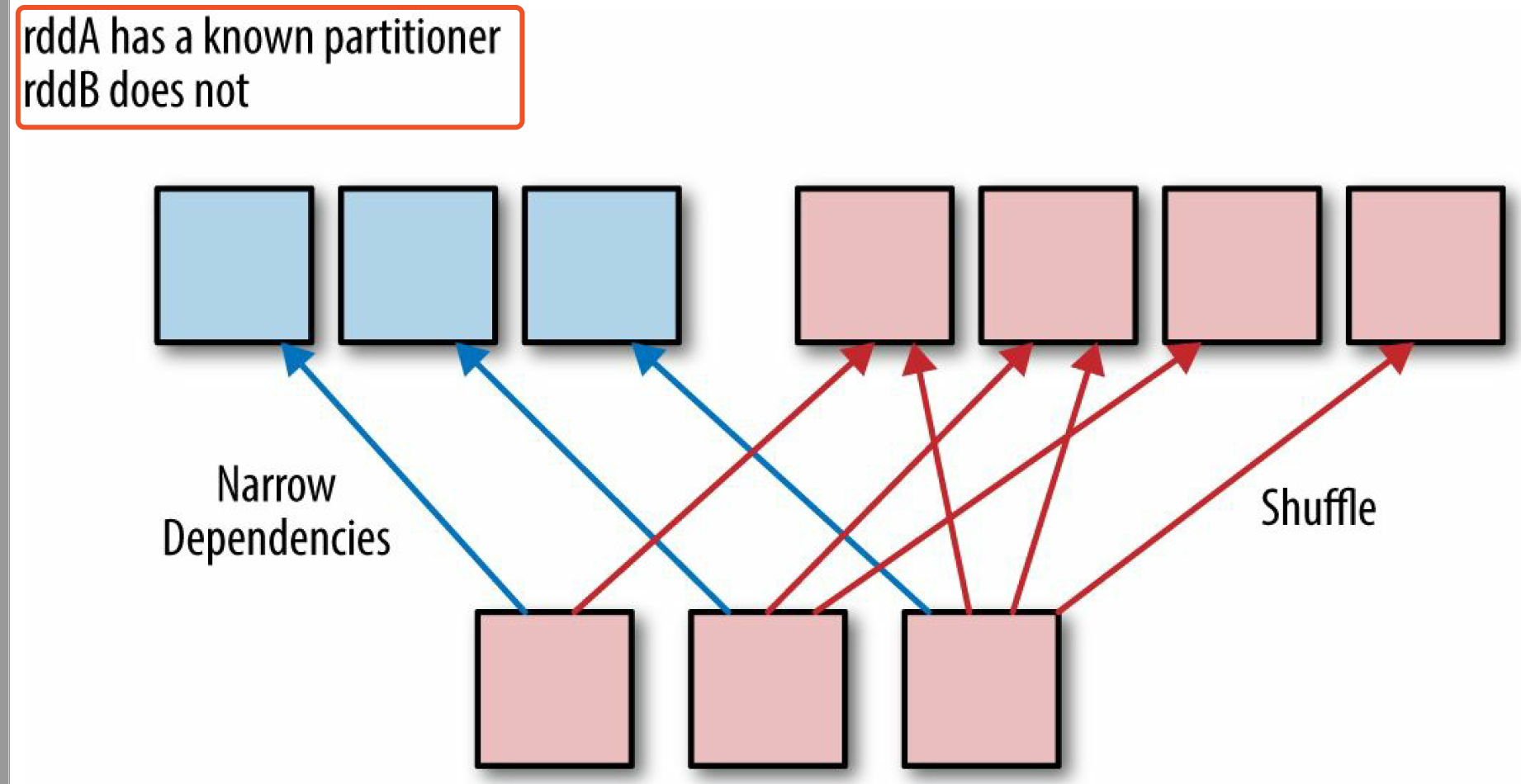
- 若子 RDD 知道 父RDD 的分区器,只会产生窄依赖,不知道分区器的才 Shuffle
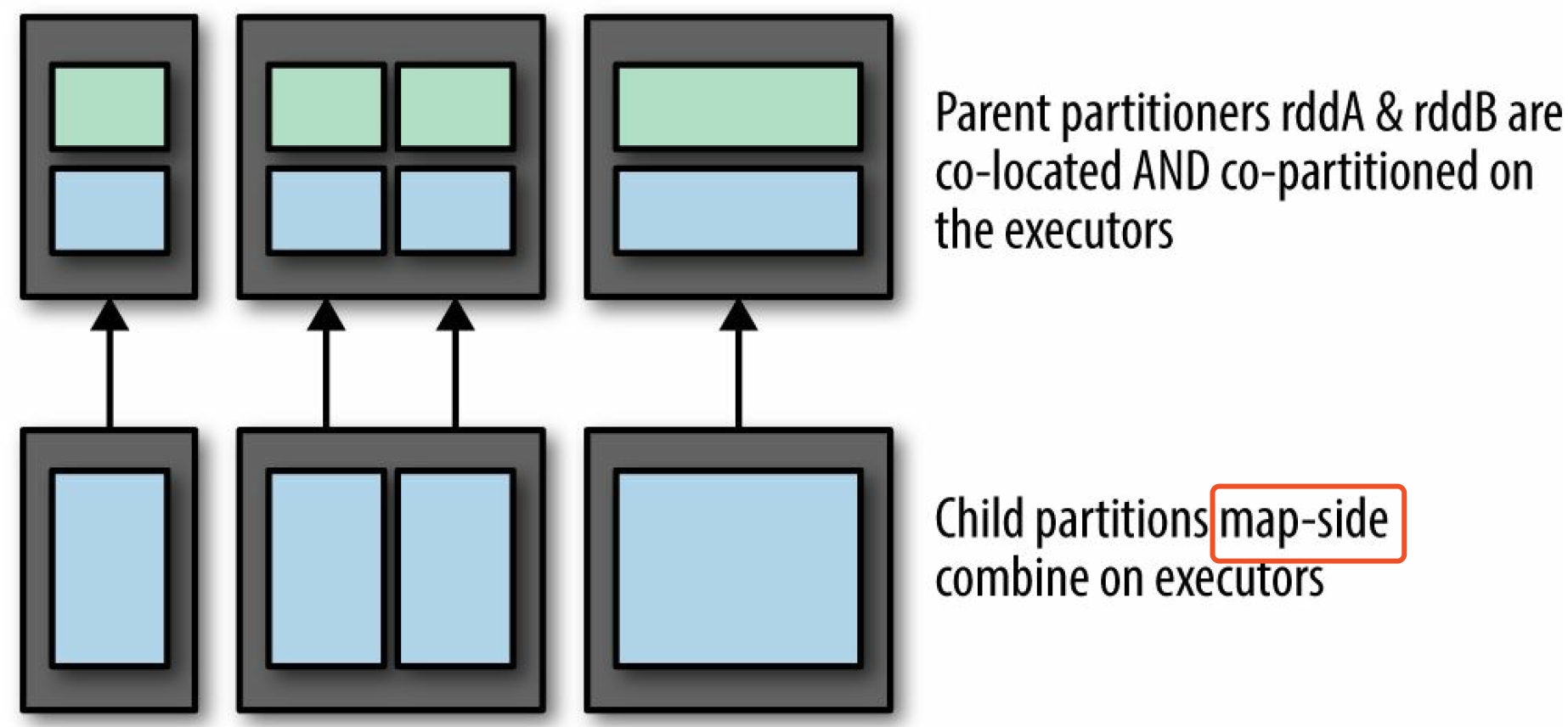
- 若两个 父RDD 的分区器相同,则不会有网络开销
Join Type
- 两个 RDD 各自都包含重复的
key,这个时候就会产生笛卡尔积。你要注意,这是不是你想要要,还是在 join 之前先 distinct - 如果有些 key 只存在某个 RDD 中,
join算子就会少数据。最好是先用outer join,然后用filter算子过滤不符合要求的数据 - 如果某个 RDD 中 key 包含子集,在
join应该先过滤掉子集。子集:以(id,score) 数据格式为例,RDD 中 id 有很多score (key 重复),但最终是想取得最大的 score,那么应该在 join 前就过滤 RDD 。
def joinScoresWithAddress2(scoreRDD : RDD[(Long, Double)],
addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]= {
val bestScoreData = scoreRDD.reduceByKey((x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}
执行计划
join 算子需要把相同 key 数据拉到同个节点,很难避免 Shuffle。Spark 中 join 时默认使用 hash 来保证相同 key 在同个节点。但 hash shuffle 时,子RDD 也是要从父RDD 中拉取数据。有两种方式可以加快拉取数据过程:
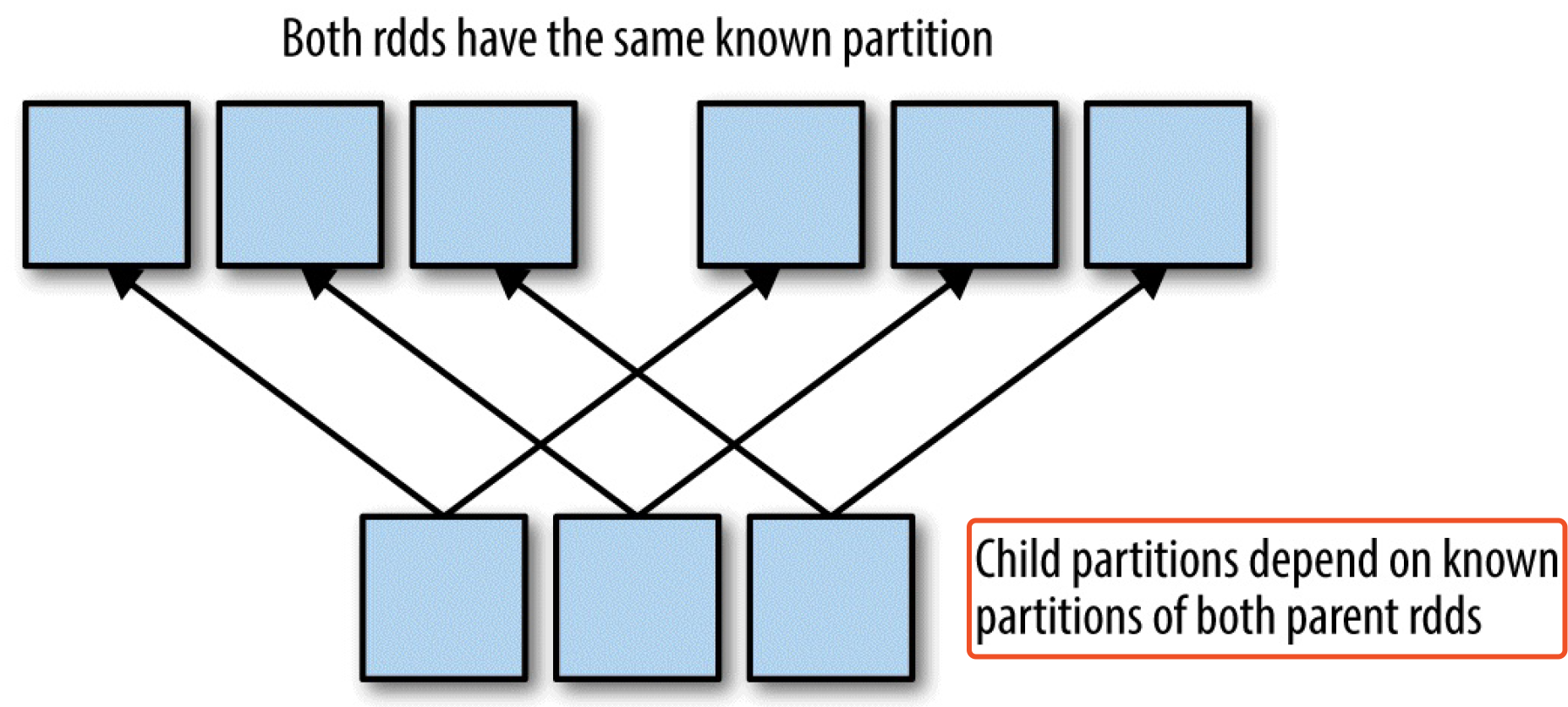
- 父RDD 的分区器已知,拉取数据时有序
- 其中一个 父RDD 很小,直接用广播变量,相当于是直接把某个父RDD存在内存。
分区器可知
def joinScoresWithAddress3(scoreRDD: RDD[(Long, Double)],
addressRDD: RDD[(Long, String)]) : RDD[(Long, (Double, String))]= {
// If addressRDD has a known partitioner we should use that,
// otherwise it has a default hash parttioner, which we can reconstruct by
// getting the number of partitions.
val addressDataPartitioner = addressRDD.partitioner match {
case (Some(p)) => p
case (None) => new HashPartitioner(addressRDD.partitions.length)
}
val bestScoreData = scoreRDD.reduceByKey(addressDataPartitioner,
(x, y) => if(x > y) x else y)
bestScoreData.join(addressRDD)
}
join 前确保有分区器,拉取数据速度可以提升(相对于宽依赖)
广播
把RDD 直接载入内存,把 join 算子直接替换成 MapSide Combine。在 Spark SQL 中有参数可以设置
- spark.sql.autoBroadcastJoinThreshold:允许载入内存的 RDD ,最大 size
- spark.sql.broadcastTimeout
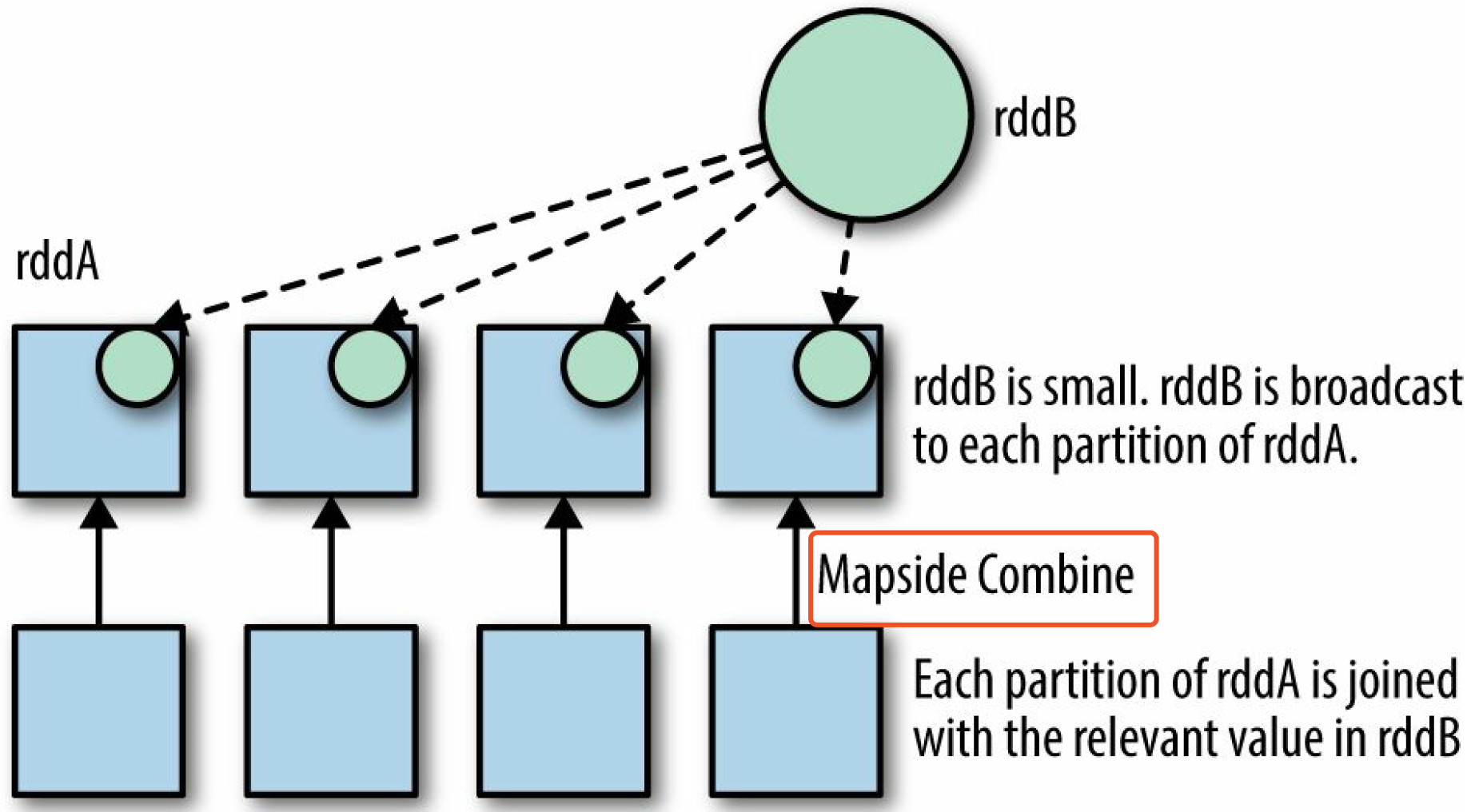
在 Spark Core 是没有以上这些操作的,但我们可以自己实现一个
def manualBroadCastHashJoin[K : Ordering : ClassTag, V1 : ClassTag,
V2 : ClassTag](bigRDD : RDD[(K, V1)],smallRDD : RDD[(K, V2)])= {
val smallRDDLocal: Map[K, V2] = smallRDD.collectAsMap()
bigRDD.sparkContext.broadcast(smallRDDLocal)
// smallRDD map side
bigRDD.mapPartitions(iter => {
iter.flatMap{
case (k,v1 ) =>
smallRDDLocal.get(k) match {
case None => Seq.empty[(K, (V1, V2))]
case Some(v2) => Seq((k, (v1, v2)))
}
}
}, preservesPartitioning = true)
//end:coreBroadCast[]
}