Flink 版本:1.10
def main(args: Array[String]) {
// Checking input parameters
val params = ParameterTool.fromArgs(args)
// set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.readTextFile(params.get("input"))
val counts: DataStream[(String, Int)] = text
// split up the lines in pairs (2-tuples) containing: (word,1)
.flatMap(_.toLowerCase.split("\\W+"))
.filter(_.nonEmpty)
.map((_, 1))
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1)
counts.print()
// execute program
env.execute("Streaming WordCount")
最简单的 WC 代码,熟悉 Spark 同学对此一定非常熟悉。
- StreamExecutionEnvironment.getExecutionEnvironment 获取 streaming 执行环境
- Source:读取文本
- Transformation:一连串的算子操作
- Sink:Print
- Exe:env.execute() 生成 DAG 提交 job 开始执行
StreamExecutionEnvironment
StreamExecutionEnvironment 是抽象类,实现类如下:
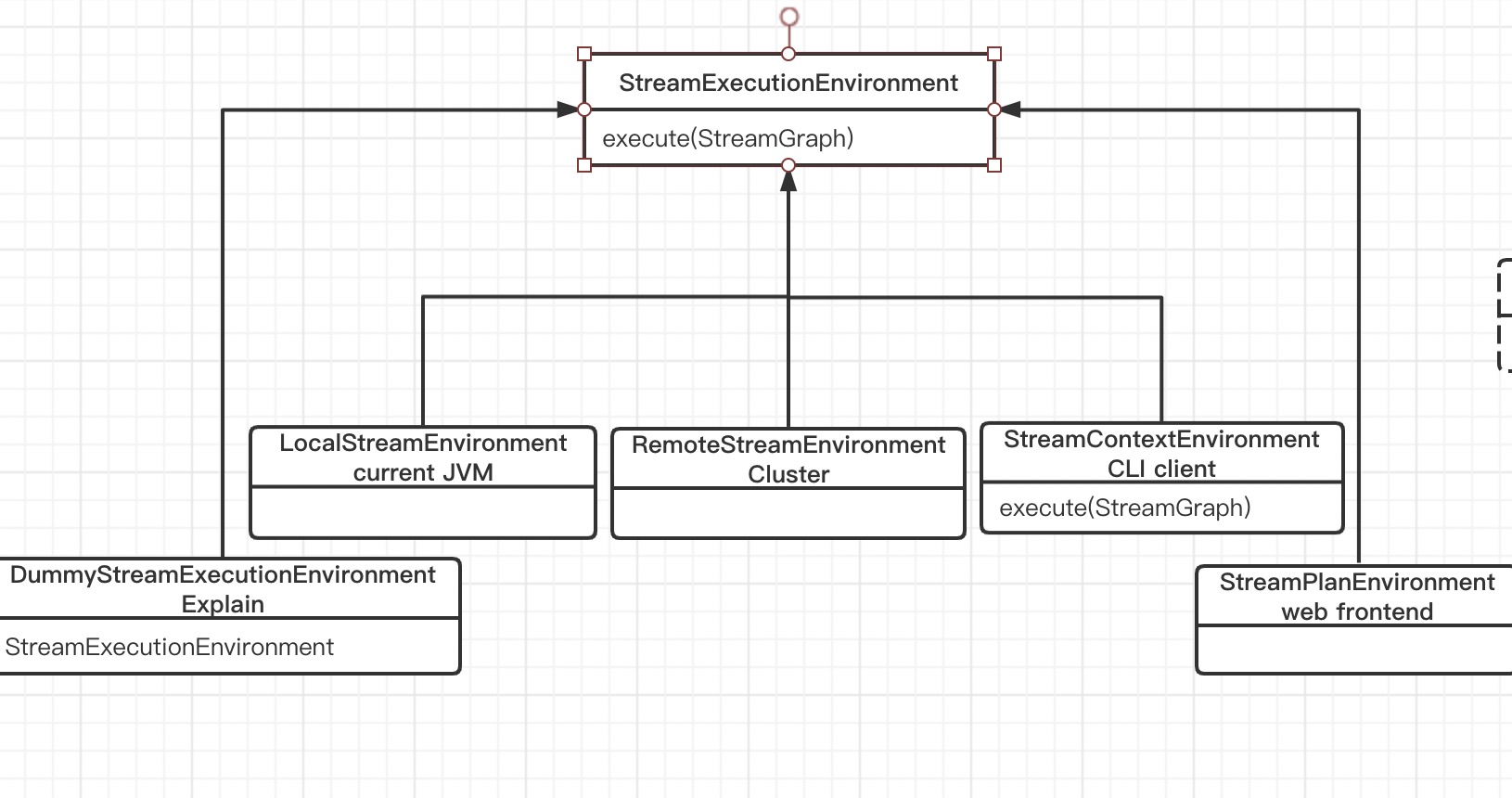
通常只关注以下两个:
- LocalStreamEnvironment:当前
JVM运行,例如 IDEA /Standalone 中 - RemoteStreamEnvironment:远程运行环境
getExecutionEnvironment API 会自动根据当前执行环境选择创建一个实现类:IDEA -> LocalStreamEnvironment;集群运行 -> RemoteStreamEnvironment。
Source
ContinuousFileReaderOperator<OUT> reader =
new ContinuousFileReaderOperator<>(inputFormat);
SingleOutputStreamOperator<OUT> source = addSource(monitoringFunction, sourceName)
.transform("Split Reader: " + sourceName, typeInfo, reader);
return new DataStreamSource<>(source);
在 Streaming 中,都是用 DataStream 来表示且每个 DataStream 都会包含 Operator(算子 => Transformation) ;Source 会表示成 DataStreamSource。
Transformation
在 Streaming 上做一连串的操作,可以理解为 Pipeline。
Sink
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// configure the type if needed
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
getExecutionEnvironment().addOperator(sink.getTransformation());
return sink;
}
与 Source 类似,生成一个 DataStreamSink。
Execute
execute 时,Flink 程序才算是正在执行,与 Spark 一样都是延迟加载(DAG 优化)。
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
// 生成 StreamGraph
return execute(getStreamGraph(jobName));
}
StreamGraphGenerator
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
本文不介绍 StreamGraph 生成过程,后文会详细阐述。
JobGraph
public JobExecutionResult execute(StreamGraph streamGraph) throws Exception {
final JobClient jobClient = executeAsync(streamGraph);
try {
final JobExecutionResult jobExecutionResult;
if (configuration.getBoolean(DeploymentOptions.ATTACHED)) {
jobExecutionResult = jobClient.getJobExecutionResult(userClassloader).get();
} else {
jobExecutionResult = new DetachedJobExecutionResult(jobClient.getJobID());
}
jobListeners.forEach(jobListener -> jobListener.onJobExecuted(jobExecutionResult, null));
return jobExecutionResult;
} catch (Throwable t) {
jobListeners.forEach(jobListener -> {
jobListener.onJobExecuted(null, ExceptionUtils.stripExecutionException(t));
});
ExceptionUtils.rethrowException(t);
// never reached, only make javac happy
return null;
}
}
Executor
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
// 根据 execution.target 生成不同的 PipelineExecutorFactory
// LocalExecutorFactory,RemoteExecutorFactory,YarnSessionClusterExecutorFactory,
// YarnJobClusterExecutorFactory,KubernetesSessionClusterExecutorFactory
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
// new LocalExecutor().execute
// IDEA 中 {execution.attached=true, execution.target=local}
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(streamGraph, configuration);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
return jobClient;
} catch (Throwable t) {
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(null, t));
ExceptionUtils.rethrow(t);
// make javac happy, this code path will not be reached
return null;
}
}
// org.apache.flink.client.deployment.executors.LocalExecutor
public CompletableFuture<JobClient> execute(Pipeline pipeline, Configuration configuration) throws Exception {
checkNotNull(pipeline);
checkNotNull(configuration);
// we only support attached execution with the local executor.
checkState(configuration.getBoolean(DeploymentOptions.ATTACHED));
//
final JobGraph jobGraph = getJobGraph(pipeline, configuration);
final MiniCluster miniCluster = startMiniCluster(jobGraph, configuration);
final MiniClusterClient clusterClient = new MiniClusterClient(configuration, miniCluster);
CompletableFuture<JobID> jobIdFuture = clusterClient.submitJob(jobGraph);
jobIdFuture
.thenCompose(clusterClient::requestJobResult)
.thenAccept((jobResult) -> clusterClient.shutDownCluster());
return jobIdFuture.thenApply(jobID ->
new ClusterClientJobClientAdapter<>(() -> clusterClient, jobID));
}
// org.apache.flink.client.deployment.executors.LocalExecutor
private JobGraph getJobGraph(Pipeline pipeline, Configuration configuration) {
// This is a quirk in how LocalEnvironment used to work. It sets the default parallelism
// to <num taskmanagers> * <num task slots>. Might be questionable but we keep the behaviour
// for now.
if (pipeline instanceof Plan) {
Plan plan = (Plan) pipeline;
final int slotsPerTaskManager = configuration.getInteger(
TaskManagerOptions.NUM_TASK_SLOTS, plan.getMaximumParallelism());
final int numTaskManagers = configuration.getInteger(
ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 1);
plan.setDefaultParallelism(slotsPerTaskManager * numTaskManagers);
}
return FlinkPipelineTranslationUtil.getJobGraph(pipeline, configuration, 1);
}
本文不介绍 JobGraph 生成过程,后文会详细阐述。
MiniCluster
// org.apache.flink.client.deployment.executors.LocalExecutor
private MiniCluster startMiniCluster(final JobGraph jobGraph, final Configuration configuration) throws Exception {
...
int numTaskManagers = configuration.getInteger(
ConfigConstants.LOCAL_NUMBER_TASK_MANAGER,
ConfigConstants.DEFAULT_LOCAL_NUMBER_TASK_MANAGER);
// we have to use the maximum parallelism as a default here, otherwise streaming
// pipelines would not run
int numSlotsPerTaskManager = configuration.getInteger(
TaskManagerOptions.NUM_TASK_SLOTS,
jobGraph.getMaximumParallelism());
// 配置 MiniCluster:NumTaskManagers,NumSlotsPerTaskManager
final MiniClusterConfiguration miniClusterConfiguration =
new MiniClusterConfiguration.Builder()
.setConfiguration(configuration)
.setNumTaskManagers(numTaskManagers)
.setRpcServiceSharing(RpcServiceSharing.SHARED)
.setNumSlotsPerTaskManager(numSlotsPerTaskManager)
.build();
final MiniCluster miniCluster = new MiniCluster(miniClusterConfiguration);
// 启动
miniCluster.start();
configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort());
return miniCluster;
}
// MiniCluster to execute Flink jobs locally
// org.apache.flink.runtime.minicluster.MiniCluster
public void start() throws Exception {
// 准备配置
try {
initializeIOFormatClasses(configuration);
//开启 Metrics Registry
LOG.info("Starting Metrics Registry");
metricRegistry = createMetricRegistry(configuration);
// RPC 服务
// bring up all the RPC services
LOG.info("Starting RPC Service(s)");
AkkaRpcServiceConfiguration akkaRpcServiceConfig = AkkaRpcServiceConfiguration.fromConfiguration(configuration);
final RpcServiceFactory dispatcherResourceManagreComponentRpcServiceFactory;
...
// start a new service per component, possibly with custom bind addresses
final String jobManagerBindAddress = miniClusterConfiguration.getJobManagerBindAddress();
final String taskManagerBindAddress = miniClusterConfiguration.getTaskManagerBindAddress();
// DedicatedRpc
dispatcherResourceManagreComponentRpcServiceFactory = new DedicatedRpcServiceFactory(akkaRpcServiceConfig, jobManagerBindAddress);
// taskManagerRpc
taskManagerRpcServiceFactory = new DedicatedRpcServiceFactory(akkaRpcServiceConfig, taskManagerBindAddress);
}
// MetricsRpc
RpcService metricQueryServiceRpcService = MetricUtils.startMetricsRpcService(
configuration,
commonRpcService.getAddress());
// Starting high-availability services
haServices = createHighAvailabilityServices(configuration, ioExecutor);
// Blob 服务:flink 用来管理二进制大文件的服务
// http://chenyuzhao.me/2017/02/08/jobmanager%E5%9F%BA%E6%9C%AC%E7%BB%84%E4%BB%B6/
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
// 心跳
heartbeatServices = HeartbeatServices.fromConfiguration(configuration);
// 启动 TM
startTaskManagers();
MetricQueryServiceRetriever metricQueryServiceRetriever = new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService());
setupDispatcherResourceManagerComponents(configuration, dispatcherResourceManagreComponentRpcServiceFactory, metricQueryServiceRetriever);
resourceManagerLeaderRetriever = haServices.getResourceManagerLeaderRetriever();
dispatcherLeaderRetriever = haServices.getDispatcherLeaderRetriever();
clusterRestEndpointLeaderRetrievalService = haServices.getClusterRestEndpointLeaderRetriever();
// dispatcher
dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
20,
Time.milliseconds(20L));
// resourceManager
resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
20,
Time.milliseconds(20L));
webMonitorLeaderRetriever = new LeaderRetriever();
resourceManagerLeaderRetriever.start(resourceManagerGatewayRetriever);
dispatcherLeaderRetriever.start(dispatcherGatewayRetriever);
clusterRestEndpointLeaderRetrievalService.start(webMonitorLeaderRetriever);
}
...
}
// create a new termination future
terminationFuture = new CompletableFuture<>();
// now officially mark this as running
running = true;
LOG.info("Flink Mini Cluster started successfully");
}
}
MiniCluster 启动一堆服务
Submit Job
// org.apache.flink.runtime.minicluster.MiniCluster
public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) {
final CompletableFuture<DispatcherGateway> dispatcherGatewayFuture = getDispatcherGatewayFuture();
final CompletableFuture<InetSocketAddress> blobServerAddressFuture = createBlobServerAddress(dispatcherGatewayFuture);
// 上传任务所需文件和 jobGraph
final CompletableFuture<Void> jarUploadFuture = uploadAndSetJobFiles(blobServerAddressFuture, jobGraph);
// job 提交到调度器
final CompletableFuture<Acknowledge> acknowledgeCompletableFuture = jarUploadFuture
.thenCombine(
dispatcherGatewayFuture,
(Void ack, DispatcherGateway dispatcherGateway) ->
// dispatcher 提交任务
dispatcherGateway.submitJob(jobGraph, rpcTimeout))
.thenCompose(Function.identity());
return acknowledgeCompletableFuture.thenApply(
(Acknowledge ignored) -> new JobSubmissionResult(jobGraph.getJobID()));
}
// org.apache.flink.runtime.dispatcher
// 每一步都有任务异常的处理 (throwable != null)
private CompletableFuture<Void> persistAndRunJob(JobGraph jobGraph) throws Exception {
// 记录 jobGraph ,并 run
jobGraphWriter.putJobGraph(jobGraph);
final CompletableFuture<Void> runJobFuture = runJob(jobGraph);
return runJobFuture.whenComplete(BiConsumerWithException.unchecked((Object ignored, Throwable throwable) -> {
if (throwable != null) {
jobGraphWriter.removeJobGraph(jobGraph.getJobID());
}
}));
}
private CompletableFuture<Void> runJob(JobGraph jobGraph) {
Preconditions.checkState(!jobManagerRunnerFutures.containsKey(jobGraph.getJobID()));
// jobManagerRunner
final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph);
jobManagerRunnerFutures.put(jobGraph.getJobID(), jobManagerRunnerFuture);
// 提交
return jobManagerRunnerFuture
.thenApply(FunctionUtils.uncheckedFunction(this::startJobManagerRunner))
.thenApply(FunctionUtils.nullFn())
.whenCompleteAsync(
(ignored, throwable) -> {
if (throwable != null) {
jobManagerRunnerFutures.remove(jobGraph.getJobID());
}
},
getMainThreadExecutor());
}
流程
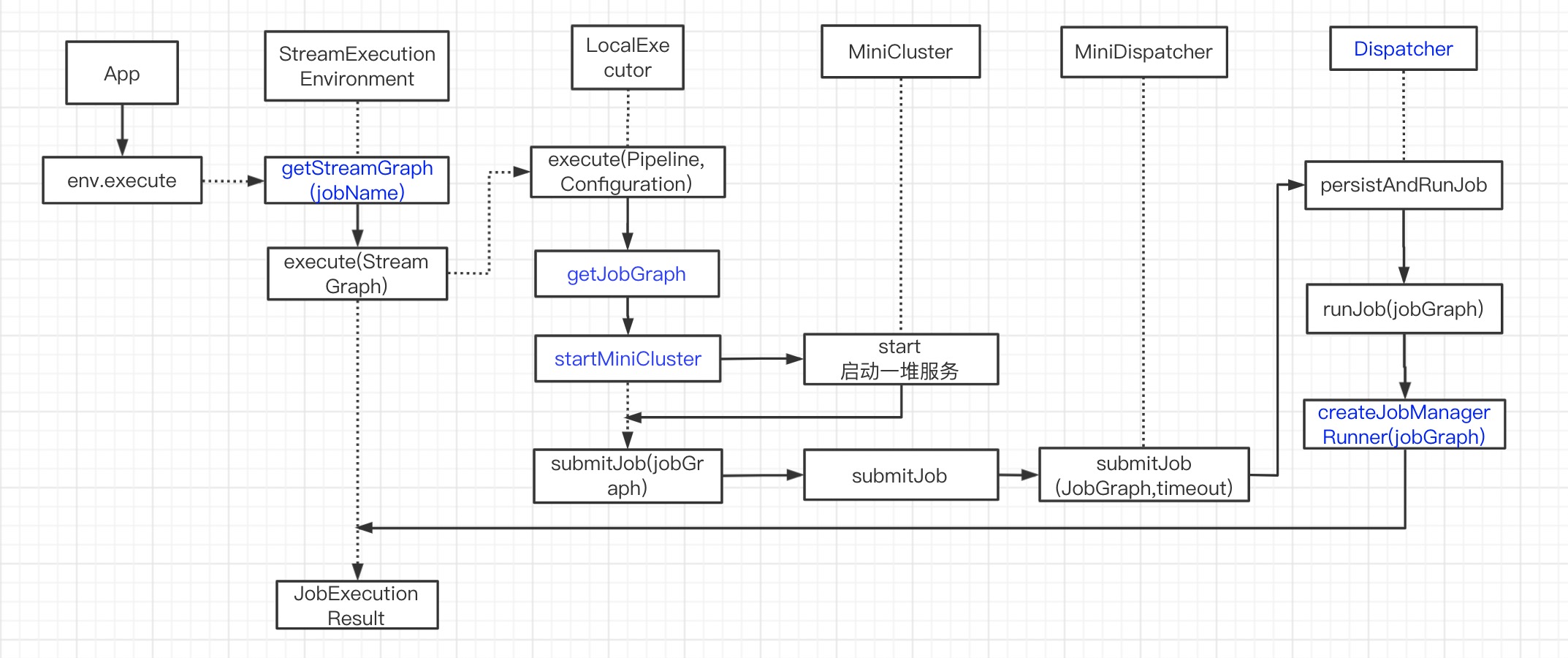
启动日志
org.apache.flink.runtime.minicluster.MiniCluster - Starting Flink Mini Cluster
org.apache.flink.runtime.minicluster.MiniCluster - Starting Metrics Registry
org.apache.flink.runtime.metrics.MetricRegistryImpl - No metrics reporter configured, no metrics will be exposed/reported.
org.apache.flink.runtime.minicluster.MiniCluster - Starting RPC Service(s)
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Trying to start actor system at :0
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
akka.remote.Remoting - Starting remoting
akka.remote.Remoting - Remoting started; listening on addresses :[akka.tcp://flink-metrics@127.0.0.1:64276]
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Actor system started at akka.tcp://flink-metrics@127.0.0.1:64276
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.metrics.dump.MetricQueryService at akka://flink-metrics/user/MetricQueryService .
org.apache.flink.runtime.minicluster.MiniCluster - Starting high-availability services
org.apache.flink.runtime.blob.BlobServer - Created BLOB server storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-7dd1e563-2fa2-4da1-aee2-8b67927bd0d2
org.apache.flink.runtime.blob.BlobServer - Started BLOB server at 0.0.0.0:64292 - max concurrent requests: 50 - max backlog: 1000
org.apache.flink.runtime.blob.PermanentBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-a753f5f4-a6d1-4d7f-a74a-306e3b1f13ea
org.apache.flink.runtime.blob.TransientBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-ec1da097-ca2d-4465-85eb-c2bcfb73e22e
org.apache.flink.runtime.minicluster.MiniCluster - Starting 1 TaskManger(s)
org.apache.flink.runtime.taskexecutor.TaskManagerRunner - Starting TaskManager with ResourceID: fa24c9b8-8108-428b-bd5c-94d169dcdf9c
org.apache.flink.runtime.taskexecutor.TaskManagerServices - Temporary file directory '/var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T': total 233 GB, usable 80 GB (34.33% usable)
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-io-dcafdb6b-a36c-4bfa-9ec6-0e5e4f982631 for spill files.
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-netty-shuffle-0d753714-eb7c-4a29-815e-d8289ccdb1ec for spill files.
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool - Allocated 64 MB for network buffer pool (number of memory segments: 2048, bytes per segment: 32768).
org.apache.flink.runtime.io.network.NettyShuffleEnvironment - Starting the network environment and its components.
org.apache.flink.runtime.taskexecutor.KvStateService - Starting the kvState service and its components.
org.apache.flink.runtime.taskexecutor.TaskManagerConfiguration - Messages have a max timeout of 10000 ms
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.taskexecutor.TaskExecutor at akka://flink/user/taskmanager_0 .
org.apache.flink.runtime.taskexecutor.JobLeaderService - Start job leader service.
org.apache.flink.runtime.filecache.FileCache - User file cache uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-dist-cache-cb29d64c-fc7d-4083-b8a7-f95651ab0dcd
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Starting rest endpoint.
org.apache.flink.runtime.webmonitor.WebMonitorUtils - Log file environment variable 'log.file' is not set.
org.apache.flink.runtime.webmonitor.WebMonitorUtils - JobManager log files are unavailable in the web dashboard. Log file location not found in environment variable 'log.file' or configuration key 'Key: 'web.log.path' , default: null (fallback keys: [{key=jobmanager.web.log.path, isDeprecated=true}])'.
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Failed to load web based job submission extension. Probable reason: flink-runtime-web is not in the classpath.
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Rest endpoint listening at localhost:50064
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender http://localhost:50064
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - http://localhost:50064 was granted leadership with leaderSessionID=230a5f5d-ae28-4b29-9173-b832e3604619
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader http://localhost:50064 , session=230a5f5d-ae28-4b29-9173-b832e3604619
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.resourcemanager.StandaloneResourceManager at akka://flink/user/resourcemanager .
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender LeaderContender: DefaultDispatcherRunner
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender LeaderContender: StandaloneResourceManager
org.apache.flink.runtime.resourcemanager.StandaloneResourceManager - ResourceManager akka://flink/user/resourcemanager was granted leadership with fencing token b3ae8d20f361fef5ef89578541eb4363
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Start SessionDispatcherLeaderProcess.
org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl - Starting the SlotManager.
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Recover all persisted job graphs.
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Successfully recovered 0 persisted job graphs.
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader akka://flink/user/resourcemanager , session=ef895785-41eb-4363-b3ae-8d20f361fef5
org.apache.flink.runtime.taskexecutor.TaskExecutor - Connecting to ResourceManager akka://flink/user/resourcemanager(b3ae8d20f361fef5ef89578541eb4363).
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.dispatcher.StandaloneDispatcher at akka://flink/user/dispatcher .
org.apache.flink.runtime.taskexecutor.TaskExecutor - Resolved ResourceManager address, beginning registration
org.apache.flink.runtime.taskexecutor.TaskExecutor - Registration at ResourceManager attempt 1 (timeout=100ms)
org.apache.flink.runtime.resourcemanager.StandaloneResourceManager - Registering TaskManager with ResourceID 6babbfff-6da0-4d9f-96cc-2f00a8656ed7 (akka://flink/user/taskmanager_0) at ResourceManager
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader akka://flink/user/dispatcher , session=1665e1f7-0cb0-40f1-8c1b-451b6b8d9de6
org.apache.flink.runtime.taskexecutor.TaskExecutor - Successful registration at resource manager akka://flinkorg.apache.flink.runtime.minicluster.MiniCluster - Starting Flink Mini Cluster
org.apache.flink.runtime.minicluster.MiniCluster - Starting Metrics Registry
org.apache.flink.runtime.metrics.MetricRegistryImpl - No metrics reporter configured, no metrics will be exposed/reported.
org.apache.flink.runtime.minicluster.MiniCluster - Starting RPC Service(s)
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Trying to start actor system at :0
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
akka.remote.Remoting - Starting remoting
akka.remote.Remoting - Remoting started; listening on addresses :[akka.tcp://flink-metrics@127.0.0.1:64276]
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Actor system started at akka.tcp://flink-metrics@127.0.0.1:64276
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.metrics.dump.MetricQueryService at akka://flink-metrics/user/MetricQueryService .
org.apache.flink.runtime.minicluster.MiniCluster - Starting high-availability services
org.apache.flink.runtime.blob.BlobServer - Created BLOB server storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-7dd1e563-2fa2-4da1-aee2-8b67927bd0d2
org.apache.flink.runtime.blob.BlobServer - Started BLOB server at 0.0.0.0:64292 - max concurrent requests: 50 - max backlog: 1000
org.apache.flink.runtime.blob.PermanentBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-a753f5f4-a6d1-4d7f-a74a-306e3b1f13ea
org.apache.flink.runtime.blob.TransientBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-ec1da097-ca2d-4465-85eb-c2bcfb73e22e
org.apache.flink.runtime.minicluster.MiniCluster - Starting 1 TaskManger(s)
org.apache.flink.runtime.taskexecutor.TaskManagerRunner - Starting TaskManager with ResourceID: fa24c9b8-8108-428b-bd5c-94d169dcdf9c
org.apache.flink.runtime.taskexecutor.TaskManagerServices - Temporary file directory '/var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T': total 233 GB, usable 80 GB (34.33% usable)
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-io-dcafdb6b-a36c-4bfa-9ec6-0e5e4f982631 for spill files.
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-netty-shuffle-0d753714-eb7c-4a29-815e-d8289ccdb1ec for spill files.
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool - Allocated 64 MB for network buffer pool (number of memory segments: 2048, bytes per segment: 32768).
org.apache.flink.runtime.io.network.NettyShuffleEnvironment - Starting the network environment and its components.
org.apache.flink.runtime.taskexecutor.KvStateService - Starting the kvState service and its components.
org.apache.flink.runtime.taskexecutor.TaskManagerConfiguration - Messages have a max timeout of 10000 ms
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.taskexecutor.TaskExecutor at akka://flink/user/taskmanager_0 .
org.apache.flink.runtime.taskexecutor.JobLeaderService - Start job leader service.