Flink 1.10
StandaloneSessionClusterEntrypoint:Entry point for the standalone session cluster
// org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
public class StandaloneSessionClusterEntrypoint extends SessionClusterEntrypoint {
public StandaloneSessionClusterEntrypoint(Configuration configuration) {
super(configuration);
}
@Override
protected DefaultDispatcherResourceManagerComponentFactory createDispatcherResourceManagerComponentFactory(Configuration configuration) {
return DefaultDispatcherResourceManagerComponentFactory.createSessionComponentFactory(StandaloneResourceManagerFactory.INSTANCE);
}
// main 函数
public static void main(String[] args) {
// startup checks and logging
EnvironmentInformation.logEnvironmentInfo(LOG, StandaloneSessionClusterEntrypoint.class.getSimpleName(), args);
SignalHandler.register(LOG);
JvmShutdownSafeguard.installAsShutdownHook(LOG);
EntrypointClusterConfiguration entrypointClusterConfiguration = null;
final CommandLineParser<EntrypointClusterConfiguration> commandLineParser = new CommandLineParser<>(new EntrypointClusterConfigurationParserFactory());
try {
// 解析参数
entrypointClusterConfiguration = commandLineParser.parse(args);
} catch (FlinkParseException e) {
LOG.error("Could not parse command line arguments {}.", args, e);
commandLineParser.printHelp(StandaloneSessionClusterEntrypoint.class.getSimpleName());
System.exit(1);
}
// 封装成 Flink Config
Configuration configuration = loadConfiguration(entrypointClusterConfiguration);
StandaloneSessionClusterEntrypoint entrypoint = new StandaloneSessionClusterEntrypoint(configuration);
// 启动 StandaloneSession
ClusterEntrypoint.runClusterEntrypoint(entrypoint);
}
}
- 解析参数
// org.apache.flink.runtime.entrypoint.parser.CommandLineParser
public T parse(@Nonnull String[] args) throws FlinkParseException {
final DefaultParser parser = new DefaultParser();
final Options options = parserResultFactory.getOptions();
final CommandLine commandLine;
try {
commandLine = parser.parse(options, args, true);
} catch (ParseException e) {
throw new FlinkParseException("Failed to parse the command line arguments.", e);
}
return parserResultFactory.createResult(commandLine);
}
// org.apache.flink.runtime.entrypoint.EntrypointClusterConfigurationParserFactory
public EntrypointClusterConfiguration createResult(@Nonnull CommandLine commandLine) {
// 指定的 flink-conf.yml 路径
final String configDir = commandLine.getOptionValue(CONFIG_DIR_OPTION.getOpt());
// -D 设置的 property,例如 -Dlog.file
final Properties dynamicProperties = commandLine.getOptionProperties(DYNAMIC_PROPERTY_OPTION.getOpt());
// WEB-UI 端口
final String restPortStr = commandLine.getOptionValue(REST_PORT_OPTION.getOpt(), "-1");
final int restPort = Integer.parseInt(restPortStr);
// WEB-UI host
final String hostname = commandLine.getOptionValue(HOST_OPTION.getOpt());
return new EntrypointClusterConfiguration(
configDir,
dynamicProperties,
commandLine.getArgs(),
hostname,
restPort);
}
- 封装 Flink Config
// org.apache.flink.runtime.entrypoint.ClusterEntrypoint
protected static Configuration loadConfiguration(EntrypointClusterConfiguration entrypointClusterConfiguration) {
// -D 的参数
final Configuration dynamicProperties = ConfigurationUtils.createConfiguration(entrypointClusterConfiguration.getDynamicProperties());
final Configuration configuration = GlobalConfiguration.loadConfiguration(entrypointClusterConfiguration.getConfigDir(), dynamicProperties);
// 设置 WEB-UI host:port
......
return configuration;
}
// org.apache.flink.configuration.GlobalConfiguration
public static Configuration loadConfiguration(final String configDir, @Nullable final Configuration dynamicProperties) {
......
// get Flink yaml configuration file
final File yamlConfigFile = new File(confDirFile, FLINK_CONF_FILENAME);
if (!yamlConfigFile.exists()) {
throw new IllegalConfigurationException(
"The Flink config file '" + yamlConfigFile +
"' (" + confDirFile.getAbsolutePath() + ") does not exist.");
}
// 重点:获取 flink-conf.yml 中的参数形成键值对
Configuration configuration = loadYAMLResource(yamlConfigFile);
if (dynamicProperties != null) {
configuration.addAll(dynamicProperties);
}
return configuration;
}
- Run
// org.apache.flink.runtime.entrypoint.ClusterEntrypoint
/**
* Base class for the Flink cluster entry points.
* Specialization of this class can be used for the session mode and the per-job mode
*/
public static void runClusterEntrypoint(ClusterEntrypoint clusterEntrypoint) {
final String clusterEntrypointName = clusterEntrypoint.getClass().getSimpleName();
try {
// start StandaloneSessionClusterEntrypoint
clusterEntrypoint.startCluster();
} catch (ClusterEntrypointException e) {
......
}
到这里我们暂停一下,看看都做了些什么:
- 解析参数并读取
flink-conf.yml,生成 Config - 利用 Config 构造 StandaloneSessionClusterEntrypoint ,ClusterEntrypoint 是 Flink 集群入口点
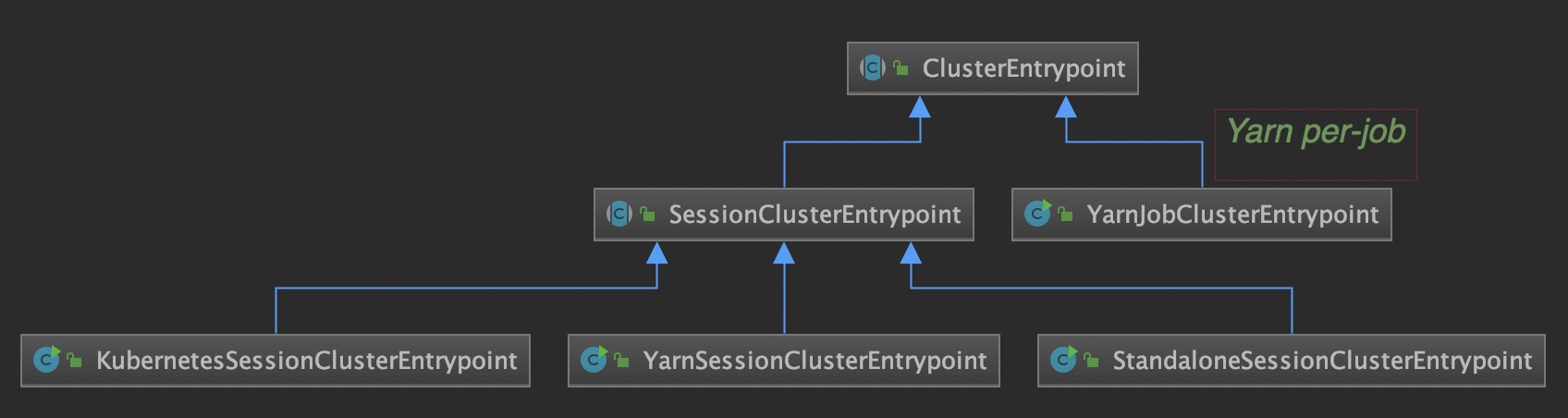
在不同的集群下,得到的入口点不同:
- Standalone 集群 :
start-cluster.sh启动的就是 StandaloneSession,如果执行standalone-job.sh那么就是 StandaloneJobClusterEntryPoint - Yarn 集群:
yarn-session.sh启动就是 YarnSessionClusterEntrypoint;如果只执行flink run,那么就是 YarnJobClusterEntrypoint - k8s 集群:
kubernetes-session.sh启动
清楚不同集群下的 Cluster 入口点后,接下来看看 ClusterEntrypoint 都做了什么。
public void startCluster() throws ClusterEntrypointException {
LOG.info("Starting {}.", getClass().getSimpleName());
try {
configureFileSystems(configuration);
SecurityContext securityContext = installSecurityContext(configuration);
securityContext.runSecured((Callable<Void>) () -> {
runCluster(configuration);
return null;
});
...
}
configureFileSystems
private void configureFileSystems(Configuration configuration) {
LOG.info("Install default filesystem.");
/**
* 初始化配置⽂文件中的共享⽂文件设置
* The given configuration is passed to each file system factory to initialize the respective
* file systems. Because the configuration of file systems may be different subsequent to
* the call of this method, this method clears the file system instance cache
**/
FileSystem.initialize(configuration, PluginUtils.createPluginManagerFromRootFolder(configuration));
}
installSecurityContext
// org.apache.flink.runtime.entrypoint.ClusterEntrypoint
protected SecurityContext installSecurityContext(Configuration configuration) throws Exception {
LOG.info("Install security context.");
SecurityUtils.install(new SecurityConfiguration(configuration));
return SecurityUtils.getInstalledContext();
}
// org.apache.flink.runtime.security.SecurityConfiguration
public SecurityConfiguration(Configuration flinkConf,
List<SecurityModuleFactory> securityModuleFactories) {
this.isZkSaslDisable = flinkConf.getBoolean("zookeeper.sasl.disable");
this.keytab = flinkConf.getString("security.kerberos.login.keytab");
this.principal = flinkConf.getString("security.kerberos.login.principal");
this.useTicketCache = flinkConf.getBoolean("security.kerberos.login.use-ticket-cache");
this.loginContextNames = parseList(flinkConf.getString("security.kerberos.login.contexts"));
this.zkServiceName = flinkConf.getString("zookeeper.sasl.service-name");
this.zkLoginContextName = flinkConf.getString("zookeeper.sasl.login-context-name");
this.securityModuleFactories = Collections.unmodifiableList(securityModuleFactories);
this.flinkConfig = checkNotNull(flinkConf);
validate();
}
/**
* org.apache.flink.runtime.security.SecurityUtils
* Utils for configuring security. The following security subsystems are supported:
* 1. Java Authentication and Authorization Service (JAAS)
* 2. Hadoop's User Group Information (UGI)
* 3. ZooKeeper's process-wide security settings.
*/
public static void install(SecurityConfiguration config) throws Exception {
try {
Class.forName(
"org.apache.hadoop.security.UserGroupInformation",
false,
SecurityUtils.class.getClassLoader());
// install a security context
// use the Hadoop login user as the subject of the installed security context
...
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
installedContext = new HadoopSecurityContext(loginUser);
}
获取 Hadoop security context
- 获取 zk、kerberos 安全认证
- 创建 HadoopSecurityContext
runCluster
private void runCluster(Configuration configuration) throws Exception {
synchronized (lock) {
// 启动基础组件,在 ResourceManager、JobMaster 中都会使用
initializeServices(configuration);
// write host information into configuration
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
// 创建工厂类
final DispatcherResourceManagerComponentFactory dispatcherResourceManagerComponentFactory = createDispatcherResourceManagerComponentFactory(configuration);
// 工厂类去启动服务
clusterComponent = dispatcherResourceManagerComponentFactory.create(
configuration,
ioExecutor,
commonRpcService,
haServices,
blobServer,
heartbeatServices,
metricRegistry,
archivedExecutionGraphStore,
new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService()),
this);
}
基础组件初始化
protected void initializeServices(Configuration configuration) throws Exception {
LOG.info("Initializing cluster services.");
synchronized (lock) {
final String bindAddress = configuration.getString(JobManagerOptions.ADDRESS);
final String portRange = getRPCPortRange(configuration);
// RPC 服务(akka)
commonRpcService = createRpcService(configuration, bindAddress, portRange);
// update the configuration used to create the high availability services
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
// 线程池,线程数 = CPU 核数
ioExecutor = Executors.newFixedThreadPool(
Hardware.getNumberCPUCores(),
new ExecutorThreadFactory("cluster-io"));
// HA 组件,生产一般为 Zookeeper 实现,
// 容器化的环境中不需要,Yarn/k8s 自动会重启失败的进程
haServices = createHaServices(configuration, ioExecutor);
// 负责文件:app jar、依赖jar、配置文件
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
// 心跳服务:ResourceManager、JobMaster、TaskManager 俩俩之间互发心跳
heartbeatServices = createHeartbeatServices(configuration);
// metric 服务
metricRegistry = createMetricRegistry(configuration);
final RpcService metricQueryServiceRpcService = MetricUtils.startMetricsRpcService(configuration, bindAddress);
metricRegistry.startQueryService(metricQueryServiceRpcService, null);
final String hostname = RpcUtils.getHostname(commonRpcService);
processMetricGroup = MetricUtils.instantiateProcessMetricGroup(
metricRegistry,
hostname,
ConfigurationUtils.getSystemResourceMetricsProbingInterval(configuration));
// 初始化一个用来存储 ExecutionGraph 的 Store, 实现是:FileArchivedExecutionGraphStore
archivedExecutionGraphStore = createSerializableExecutionGraphStore(configuration, commonRpcService.getScheduledExecutor());
}
}
基础组件包含:
- 线程池:ioExecutor
- HA 组件:haServices,生产上一般基于
Zookeeper实现 - 负责文件:BlobServer,app jar、依赖jar、配置文件等
- 心跳服务:HeartbeatServices,ResourceManager、JobMaster、TaskManager 俩俩之间会互发心跳
- metric 服务
启动服务
基础组件启动后,开始启动 JobManager 进程中三个重要的服务:ResourceManager、DispatcherRunner、JobMaster、WebMonitorEndpoint
WebMonitorEndpoint:Rest API 调用,Flink Job 对外的 Http 接口ResourceManager:Job 的资源管理,向 Yarn 申请资源,响应 JobMaster 分配DispatcherRunner:负责接收用户提交的 JobGragh, 然后启动一个 JobMasterJobMaster:任务调度和管理
在启动时先各自的创建工厂,然后使用工厂类启动各自的服务。
ResourceManager:StandaloneResourceManagerFactoryWebMonitorEndpoint:JobRestEndpointFactoryDispatcherRunner:DefaultDispatcherRunnerFactory
启动的服务如下:
ResourceManager:StandaloneResourceManagerWebMonitorEndpoint:DispatcherRestEndpointDispatcherRunner:DefaultDispatcherRunner
DispatcherResourceManagerComponentFactory 是抽象类,不同集群运行执行不同的方法。本例是 ` StandaloneSession ,注意观察传进去的 ResourceManagerFactory`
// org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint
public class StandaloneSessionClusterEntrypoint extends SessionClusterEntrypoint {
@Override
protected DefaultDispatcherResourceManagerComponentFactory createDispatcherResourceManagerComponentFactory(Configuration configuration) {
return DefaultDispatcherResourceManagerComponentFactory.createSessionComponentFactory(StandaloneResourceManagerFactory.INSTANCE);
}
//org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactor
public static DefaultDispatcherResourceManagerComponentFactory createSessionComponentFactory(
ResourceManagerFactory<?> resourceManagerFactory) {
return new DefaultDispatcherResourceManagerComponentFactory(
DefaultDispatcherRunnerFactory.createSessionRunner(SessionDispatcherFactory.INSTANCE),
resourceManagerFactory,
SessionRestEndpointFactory.INSTANCE);
}
DefaultDispatcherResourceManagerComponentFactory(
@Nonnull DispatcherRunnerFactory dispatcherRunnerFactory,
@Nonnull ResourceManagerFactory<?> resourceManagerFactory,
@Nonnull RestEndpointFactory<?> restEndpointFactory) {
this.dispatcherRunnerFactory = dispatcherRunnerFactory;
this.resourceManagerFactory = resourceManagerFactory;
this.restEndpointFactory = restEndpointFactory;
}
到这里,Flink Master 非常重要的组件进程出现:ResourceManager 和 Dispatcher
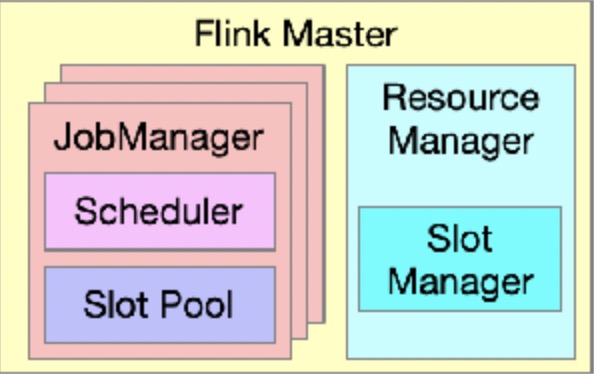
一个 Flink Master 中有一个 Resource Manager 和多个 Job Manager ,Flink Master 中每一个 Job Manager 单独管理一个具体的 Job ,Job Manager 中的 Scheduler 组件负责调度执行该 Job 的 DAG 中所有 Task ,发出资源请求,即整个资源调度的起点;JobManager 中的 Slot Pool 组件持有分配到该 Job 的所有资源。另外,Flink Master 中唯一的 Resource Manager 负责整个 Flink Cluster 的资源调度以及与外部调度系统对接,这里的外部调度系统指的是 Kubernetes、Mesos、Yarn 等资源管理系统。
@Override
public DispatcherResourceManagerComponent create(
Configuration configuration,
Executor ioExecutor,
RpcService rpcService,
HighAvailabilityServices highAvailabilityServices,
BlobServer blobServer,
HeartbeatServices heartbeatServices,
MetricRegistry metricRegistry,
ArchivedExecutionGraphStore archivedExecutionGraphStore,
MetricQueryServiceRetriever metricQueryServiceRetriever,
FatalErrorHandler fatalErrorHandler) throws Exception {
LeaderRetrievalService dispatcherLeaderRetrievalService = null;
LeaderRetrievalService resourceManagerRetrievalService = null;
WebMonitorEndpoint<?> webMonitorEndpoint = null;
ResourceManager<?> resourceManager = null;
ResourceManagerMetricGroup resourceManagerMetricGroup = null;
DispatcherRunner dispatcherRunner = null;
try {
// 调度程序网关
final LeaderGatewayRetriever<DispatcherGateway> dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
rpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
10,
Time.milliseconds(50L));
// 资源管理网关
final LeaderGatewayRetriever<ResourceManagerGateway> resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
rpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
10,
Time.milliseconds(50L));
final ExecutorService executor = WebMonitorEndpoint.createExecutorService(
configuration.getInteger(RestOptions.SERVER_NUM_THREADS),
configuration.getInteger(RestOptions.SERVER_THREAD_PRIORITY),
"DispatcherRestEndpoint");
final long updateInterval = configuration.getLong(MetricOptions.METRIC_FETCHER_UPDATE_INTERVAL);
final MetricFetcher metricFetcher = updateInterval == 0
? VoidMetricFetcher.INSTANCE
: MetricFetcherImpl.fromConfiguration(
configuration,
metricQueryServiceRetriever,
dispatcherGatewayRetriever,
executor);
webMonitorEndpoint = restEndpointFactory.createRestEndpoint(
configuration,
dispatcherGatewayRetriever,
resourceManagerGatewayRetriever,
blobServer,
executor,
metricFetcher,
highAvailabilityServices.getClusterRestEndpointLeaderElectionService(),
fatalErrorHandler);
// webMonitorEndpoint 启动
log.debug("Starting Dispatcher REST endpoint.");
webMonitorEndpoint.start();
final String hostname = RpcUtils.getHostname(rpcService);
// 资源管理器
resourceManagerMetricGroup = ResourceManagerMetricGroup.create(metricRegistry, hostname);
resourceManager = resourceManagerFactory.createResourceManager(
configuration,
ResourceID.generate(),
rpcService,
highAvailabilityServices,
heartbeatServices,
fatalErrorHandler,
new ClusterInformation(hostname, blobServer.getPort()),
webMonitorEndpoint.getRestBaseUrl(),
resourceManagerMetricGroup);
final HistoryServerArchivist historyServerArchivist = HistoryServerArchivist.createHistoryServerArchivist(configuration, webMonitorEndpoint);
final PartialDispatcherServices partialDispatcherServices = new PartialDispatcherServices(
configuration,
highAvailabilityServices,
resourceManagerGatewayRetriever,
blobServer,
heartbeatServices,
() -> MetricUtils.instantiateJobManagerMetricGroup(metricRegistry, hostname),
archivedExecutionGraphStore,
fatalErrorHandler,
historyServerArchivist,
metricRegistry.getMetricQueryServiceGatewayRpcAddress());
log.debug("Starting Dispatcher.");
// DispatcherRunner 加载 jobGraph,createDispatcherRunner 内部中启动
dispatcherRunner = dispatcherRunnerFactory.createDispatcherRunner(
highAvailabilityServices.getDispatcherLeaderElectionService(),
fatalErrorHandler,
new HaServicesJobGraphStoreFactory(highAvailabilityServices),
ioExecutor,
rpcService,
partialDispatcherServices);
// ResourceManager 启动
log.debug("Starting ResourceManager.");
resourceManager.start();
...
}
WebMonitorEndpoint
- 初始化一大堆 Handler:initializeHandlers
- 启动一个 Netty 的服务端,注册这些 Handler
- HA
ResourceManager
- 定时服务:
- Slot 申请超时服务:startStartupPeriod ,默认5分钟执行一次
- TaskManager 超时检查服务:
- 心跳服务:默认10s一次,超时判断 50s
- 与JobMaster 之间心跳
- 与 TaskManager 之间的心跳
// 成为 leader 后
grantLeadership -> tryAcceptLeadership -> startServicesOnLeadership
protected void startServicesOnLeadership() {
startHeartbeatServices();
slotManager.start(getFencingToken(), getMainThreadExecutor(), new ResourceActionsImpl());
}
// 心跳服务
private void startHeartbeatServices() {
taskManagerHeartbeatManager = heartbeatServices.createHeartbeatManagerSender(
resourceId,
new TaskManagerHeartbeatListener(),
getMainThreadExecutor(),
log);
jobManagerHeartbeatManager = heartbeatServices.createHeartbeatManagerSender(
resourceId,
new JobManagerHeartbeatListener(),
getMainThreadExecutor(),
log);
}
DispatcherRunner
- 启动 JobGraphStore:SessionDispatcherLeaderProcess
- 从 JobGraphStore 恢复 Job(Zookeeper),并启动 JobMaster
// org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess
private void handleAddedJobGraph(JobID jobId) {
log.debug(
"Job {} has been added to the {} by another process.",
jobId,
jobGraphStore.getClass().getSimpleName());
// serialize all ongoing recovery operations
onGoingRecoveryOperation = onGoingRecoveryOperation
.thenApplyAsync(
ignored -> recoverJobIfRunning(jobId),
ioExecutor)
.thenCompose(optionalJobGraph -> optionalJobGraph
.flatMap(this::submitAddedJobIfRunning)
.orElse(FutureUtils.completedVoidFuture()))
.handle(this::onErrorIfRunning);
}
总结
本文虽然以 StandaloneSessionClusterEntrypoint 为例去分析 JobManager 的启动流程
- 加载配置,并获取 Hadoop Context
- 启动集群就是去启动服务(RM,Schedule,REST)
但不同集群上的流程大同小异。当然我们实际生产中大多数还是 On YARN,那么去看 YarnJobClusterEntrypoint 和YarnSessionClusterEntrypoint 即可。