Flink 1.11
Flink 任务在运行之前会经历以下几个阶段:
Program -> StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行计划
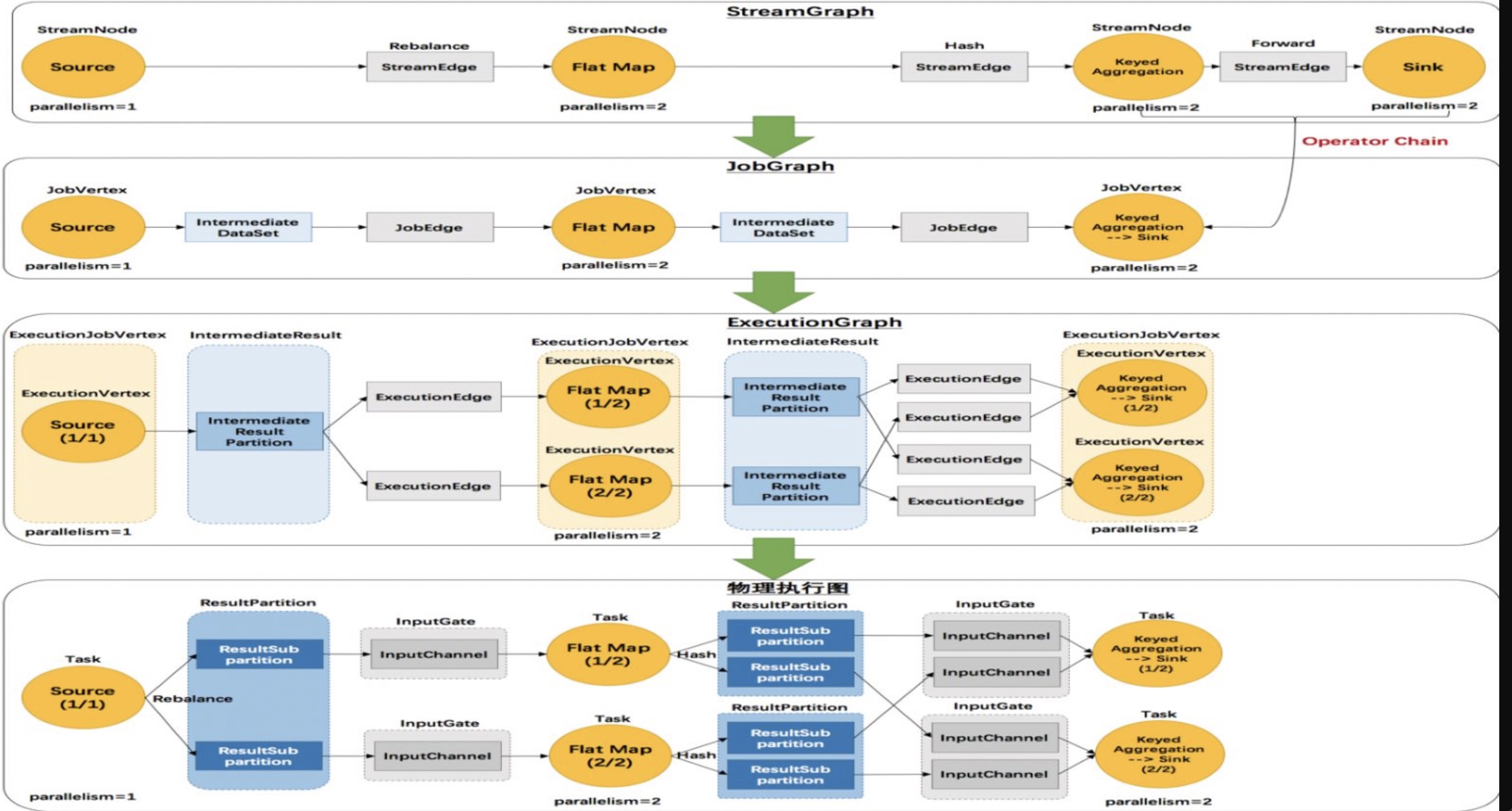
在深入剖析 Flink Straming WC流程 中没有介绍StreamGraph,本文将详细剖析 StreamGraph 的生成过程。
StreamGraph 从 Source 节点开始,每一次 transform 生成一个 StreamNode,两个 StreamNode 通过 StreamEdge 连接在一起,形成 StreamNode 和 StreamEdge 构成的DAG。
StreamNode 是用来描述 operator 的逻辑节点;StreamEdge 是⽤来描述流拓扑中的⼀个边界,其有一个的源 StreamNode (sourceVertex) 和目标 StreamNode(targetVertex),以及数据在源到目标直接转发时,进行的分区与 select 等操作的逻辑。
本文以参考资料一的代码为例剖析
def main(args: Array[String]): Unit = {
val parameterTool = ParameterTool.fromArgs(args)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.readTextFile(parameterTool.get("input")).setParallelism(1)
env.getConfig.setGlobalJobParameters(parameterTool)
val windowSize = parameterTool.getInt("window", 10)
val slideSize = parameterTool.getInt("slide", 5)
val counts = text.flatMap(_.split(",")).map((_, 1)).setParallelism(4)
.slotSharingGroup("flatmap_sg")
.keyBy(0)
.countWindow(windowSize, slideSize)
.sum(1).setParallelism(3).slotSharingGroup("sum_sg")
counts.print().setParallelism(3)
env.execute("test")
}
StreamGraph 生成入口
// org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.java
/**
* Triggers the program execution. The environment will execute all parts of
* the program that have resulted in a "sink" operation. Sink operations are
* for example printing results or forwarding them to a message queue.
*
* <p>The program execution will be logged and displayed with the provided name
*
* @param jobName
* Desired name of the job
* @return The result of the job execution, containing elapsed time and accumulators.
* @throws Exception which occurs during job execution.
*/
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
// 生成 StreamGraph
return execute(getStreamGraph(jobName));
}
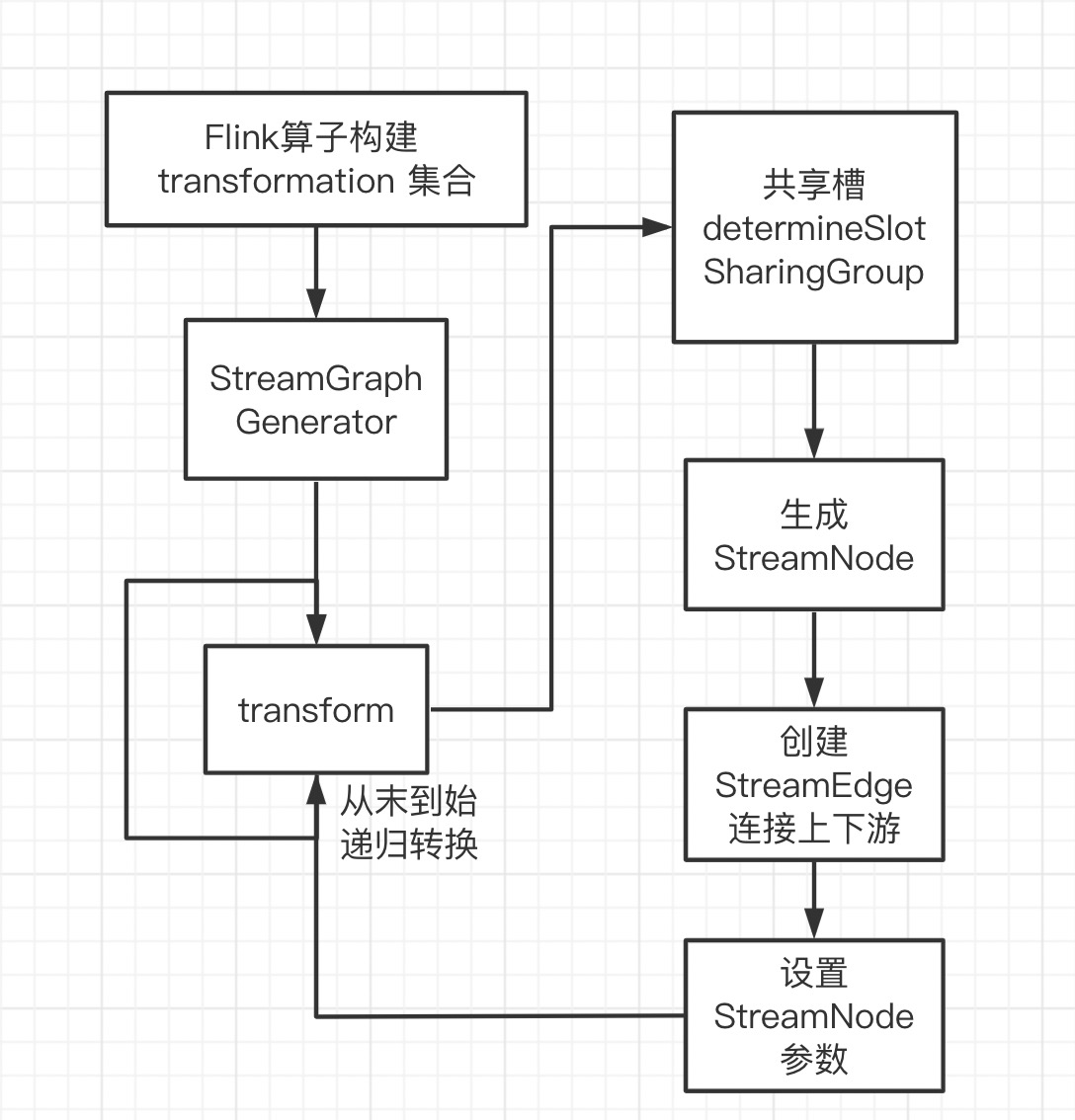
Program 转换成 StreamGraph 具体分为三步:
- 将 transform 添加到 StreamExecutionEnvironment 的
transformations - 调用 StreamGraphGenerator 的 generate 方法,遍历 transformations 构建 StreamNode 及 StreamEage
- 通过 StreamEdge 连接 StreamNode
transformations
每个算子都是一个 transformations,第一步就是添加所有的 transformations;以 Flatmap 为例
// org.apache.flink.streaming.api.datastream.DataStream.java
public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper, TypeInformation<R> outputType) {
return transform("Flat Map", outputType, new StreamFlatMap<>(clean(flatMapper)));
}
public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// 以上一个 this.transformation 为输入,生成当前 transformation --> resultTransform
// OneInputTransformation
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
// 返回携带 resultTransform 的stream
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 添加 resultTransform
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
上述过程可以用下图来总结
![]()
将用户自定义的函数
MapFunction包装到StreamMap这个 Operator 中,再将StreamMap包装到OneInputTransformation,最后该 transformation 存到 env 中,当调用env.execute时,遍历其中的transformation 集合构造出 StreamGraph 。
Generator
// org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.java
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
private StreamGraphGenerator getStreamGraphGenerator() {
if (transformations.size() <= 0) {
throw new IllegalStateException("No operators defined in streaming topology. Cannot execute.");
}
return new StreamGraphGenerator(transformations, config, checkpointCfg)
.setStateBackend(defaultStateBackend)
.setChaining(isChainingEnabled)
.setUserArtifacts(cacheFile)
.setTimeCharacteristic(timeCharacteristic)
.setDefaultBufferTimeout(bufferTimeout);
}
// org.apache.flink.streaming.api.graph.StreamGraphGenerator.java
private Map<Integer, StreamNode> streamNodes;
public StreamGraph generate() {
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
streamGraph.setStateBackend(stateBackend);
streamGraph.setChaining(chaining);
streamGraph.setScheduleMode(scheduleMode);
streamGraph.setUserArtifacts(userArtifacts);
streamGraph.setTimeCharacteristic(timeCharacteristic);
streamGraph.setJobName(jobName);
streamGraph.setBlockingConnectionsBetweenChains(blockingConnectionsBetweenChains);
alreadyTransformed = new HashMap<>();
for (Transformation<?> transformation: transformations) {
transform(transformation);
}
final StreamGraph builtStreamGraph = streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
}
private Collection<Integer> transform(Transformation<?> transform) {
// 跳过已经转换过的transformation
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// 设置最大并行数
int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// 为了触发 MissingTypeInfo 的异常
transform.getOutputType();
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
// Map<vertexID, StreamNode> streamNodes,以下设置 StreamNode 属性
// StreamNode 在上面 transform 期间生成并添加到 streamGraph
if (transform.getBufferTimeout() >= 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
} else {
streamGraph.setBufferTimeout(transform.getId(), defaultBufferTimeout);
}
// 算子 uid
if (transform.getUid() != null) {
streamGraph.setTransformationUID(transform.getId(), transform.getUid());
}
if (transform.getUserProvidedNodeHash() != null) {
streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());
}
if (!streamGraph.getExecutionConfig().hasAutoGeneratedUIDsEnabled()) {
if (transform instanceof PhysicalTransformation &&
transform.getUserProvidedNodeHash() == null &&
transform.getUid() == null) {
throw new IllegalStateException("Auto generated UIDs have been disabled " +
"but no UID or hash has been assigned to operator " + transform.getName());
}
}
if (transform.getMinResources() != null && transform.getPreferredResources() != null) {
streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());
}
streamGraph.setManagedMemoryWeight(transform.getId(), transform.getManagedMemoryWeight());
return transformedIds;
}
- 携带 transformations 信息生成 StreamGraphGenerator 对象
- 调用 generate 函数
- 初始化 StreamGraph
- 遍历 transformations
- alreadyTransformed 判断是否已添加
- 不同类型的 transformation ,调用对应的解析,解析成 StreamNode 添加到
StreamGraph- 对该 transform 的上游 transform 进行递归转换,确保上游的都已经完成了转化
- 通过 transform 构造出 StreamNode
- 与上游的 transform 进行连接,构造出 StreamEdge
- 为 StreamNode 设置 bufferTimeout 、uid、ResourceSpec
StreamNode
// org.apache.flink.streaming.api.graph.StreamGraphGenerator.java
// SourceTransformation
private <T> Collection<Integer> transformSource(SourceTransformation<T> source) {
// 对于数据流的源来说, 如果用户没有指定 slotSharingGroup, 这里返回的就是 "default"
String slotSharingGroup = determineSlotSharingGroup(source.getSlotSharingGroup(), Collections.emptyList());
// getId 从 1 开始 全局自增:根据算子添加到 env 顺序
streamGraph.addSource(source.getId(),
slotSharingGroup,
source.getCoLocationGroupKey(),
source.getOperatorFactory(),
null,
source.getOutputType(),
"Source: " + source.getName());
int parallelism = source.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT ?
source.getParallelism() : executionConfig.getParallelism();
streamGraph.setParallelism(source.getId(), parallelism);
streamGraph.setMaxParallelism(source.getId(), source.getMaxParallelism());
return Collections.singleton(source.getId());
}
// transformOneInputTransform
private <IN, OUT> Collection<Integer> transformOneInputTransform(OneInputTransformation<IN, OUT> transform) {
// 递归对该 transform 的直接上游 transform 进行转换,获得直接上游id集合
Collection<Integer> inputIds = transform(transform.getInput());
// 已经 transform 不再处理
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
// 添加 StreamNode,getId 自增,本例 source 为1,flatmap 为2
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getCoLocationGroupKey(),
transform.getOperatorFactory(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
if (transform.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = transform.getStateKeyType().createSerializer(executionConfig);
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
int parallelism = transform.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT ?
transform.getParallelism() : executionConfig.getParallelism();
streamGraph.setParallelism(transform.getId(), parallelism);
streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism());
// 添加 StreamEdge
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
return Collections.singleton(transform.getId());
}
// SinkTransformation
private <T> Collection<Integer> transformSink(SinkTransformation<T> sink) {
Collection<Integer> inputIds = transform(sink.getInput());
String slotSharingGroup = determineSlotSharingGroup(sink.getSlotSharingGroup(), inputIds);
streamGraph.addSink(sink.getId(),
slotSharingGroup,
sink.getCoLocationGroupKey(),
sink.getOperatorFactory(),
sink.getInput().getOutputType(),
null,
"Sink: " + sink.getName());
StreamOperatorFactory operatorFactory = sink.getOperatorFactory();
if (operatorFactory instanceof OutputFormatOperatorFactory) {
streamGraph.setOutputFormat(sink.getId(), ((OutputFormatOperatorFactory) operatorFactory).getOutputFormat());
}
int parallelism = sink.getParallelism() != ExecutionConfig.PARALLELISM_DEFAULT ?
sink.getParallelism() : executionConfig.getParallelism();
streamGraph.setParallelism(sink.getId(), parallelism);
streamGraph.setMaxParallelism(sink.getId(), sink.getMaxParallelism());
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId,
sink.getId(),
0
);
}
if (sink.getStateKeySelector() != null) {
TypeSerializer<?> keySerializer = sink.getStateKeyType().createSerializer(executionConfig);
streamGraph.setOneInputStateKey(sink.getId(), sink.getStateKeySelector(), keySerializer);
}
return Collections.emptyList();
}
// 确定共享槽
private String determineSlotSharingGroup(String specifiedGroup, Collection<Integer> inputIds) {
if (specifiedGroup != null) {
return specifiedGroup;
} else {
String inputGroup = null;
// source 无 inputIds
for (int id: inputIds) {
String inputGroupCandidate = streamGraph.getSlotSharingGroup(id);
if (inputGroup == null) {
inputGroup = inputGroupCandidate;
} else if (!inputGroup.equals(inputGroupCandidate)) {
return DEFAULT_SLOT_SHARING_GROUP;
}
}
return inputGroup == null ? DEFAULT_SLOT_SHARING_GROUP : inputGroup;
}
}
以 source -> flatmap -> sink 为例,分析 StreamNode 生成过程
- Source
- 确定共享槽,determineSlotSharingGroup 可知,分为三种情况
- 算子有指定,直接返回 specifiedGroup
- 算子无指定,若 inputs 的 SlotSharingGroup 都相同,那么返回这个相同的 SlotSharingGroup
- 算子无指定,若 inputs 的 SlotSharingGroup 不都相同,则返回 “default”
- 添加
source节点(看下面 StreamGraph 代码)- 创建 StreamNode ,加入到 streamNodes
- StreamNode 设置输入,输出序列化类型
- 设置并行度
- 返回 id
- flatMap
- 递归上游 transform 进行转换,返回上游 id
- 确定共享槽
- 添加 StreamNode (步骤相似)
- 设置并行度等参数
- 添加 StreamEdge
- 如果是虚拟节点,找到上游物理节点后再调用 addEdge 函数
- 物理节点,先确定上下游分区规则
- 若 partitioner 都为null,上下游并行度相同,分区规则
ForwardPartitioner - 若 partitioner 都为null,上下游并行度不同,分区规则
RebalancePartitioner - 若 partitioner 不为null,直接使用 partitioner
- 若 partitioner 都为null,上下游并行度相同,分区规则
- 创建 Edge
- 上游添加 OutEdge,下游添加 InEdge
- 返回 id
- Sink
- 递归上游 transform 进行转换,返回上游 id
- 确定共享槽
- 添加 StreamNode (步骤相似)
- 添加 StreamEdge
// org.apache.flink.streaming.api.graph.StreamGraph
public <IN, OUT> void addSource(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
SourceOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
// source 节点运行时的实际任务类型 SourceOperatorStreamTask
addOperator(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
inTypeInfo,
outTypeInfo,
operatorName,
SourceOperatorStreamTask.class);
// 记录 source
sources.add(vertexID);
}
private <IN, OUT> void addOperator(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName,
Class<? extends AbstractInvokable> invokableClass) {
// 添加 streamNode
addNode(vertexID, slotSharingGroup, coLocationGroup, invokableClass, operatorFactory, operatorName);
// 设置输入、输出的序列化
setSerializers(vertexID, createSerializer(inTypeInfo), null, createSerializer(outTypeInfo));
if (operatorFactory.isOutputTypeConfigurable() && outTypeInfo != null) {
// sets the output type which must be know at StreamGraph creation time
operatorFactory.setOutputType(outTypeInfo, executionConfig);
}
// 根据操作符类型, 进行输⼊数据类型判断
if (operatorFactory.isInputTypeConfigurable()) {
operatorFactory.setInputType(inTypeInfo, executionConfig);
}
if (LOG.isDebugEnabled()) {
LOG.debug("Vertex: {}", vertexID);
}
}
// 创建 StreamNode,并添加到 StreamGraph
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends AbstractInvokable> vertexClass,
StreamOperatorFactory<?> operatorFactory,
String operatorName) {
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex = new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
new ArrayList<OutputSelector<?>>(),
vertexClass);
// (id,StreamNode)
streamNodes.put(vertexID, vertex);
return vertex;
}
// 添加 Edge
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(upStreamVertexID,
downStreamVertexID,
typeNumber,
null,
new ArrayList<String>(),
null,
null);
}
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner<?> partitioner,
List<String> outputNames,
OutputTag outputTag,
ShuffleMode shuffleMode) {
//先判断是不是虚拟节点上的边,如果是,则找到虚拟节点上游对应的物理节点
//在两个物理节点之间添加边,并把对应的 StreamPartitioner,或者 OutputTag 等补充信息添加到StreamEdge中
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
// 当上游是 SideOutput 时,递归调用,并传入 SideOutput 信息
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag, shuffleMode);
} else if (virtualSelectNodes.containsKey(upStreamVertexID)) {
// 当上游是select时,递归调用,并传入select信息
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSelectNodes.get(virtualId).f0;
if (outputNames.isEmpty()) {
// selections that happen downstream override earlier selections
outputNames = virtualSelectNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
// 当上游是partition时,递归调用,并传入partitioner信息
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
shuffleMode = virtualPartitionNodes.get(virtualId).f2;
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag, shuffleMode);
} else {
// 物理节点
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
// 分区规则
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner<Object>();
} else if (partitioner == null) {
partitioner = new RebalancePartitioner<Object>();
}
if (partitioner instanceof ForwardPartitioner) {
if (upstreamNode.getParallelism() != downstreamNode.getParallelism()) {
throw new UnsupportedOperationException("Forward partitioning does not allow " +
"change of parallelism. Upstream operation: " + upstreamNode + " parallelism: " + upstreamNode.getParallelism() +
", downstream operation: " + downstreamNode + " parallelism: " + downstreamNode.getParallelism() +
" You must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
if (shuffleMode == null) {
shuffleMode = ShuffleMode.UNDEFINED;
}
StreamEdge edge = new StreamEdge(upstreamNode, downstreamNode, typeNumber, outputNames, partitioner, outputTag, shuffleMode);
getStreamNode(edge.getSourceId()).addOutEdge(edge);
getStreamNode(edge.getTargetId()).addInEdge(edge);
}
}
流程图
本文代码生成的 transformations
![]()
添加代码System.out.println(env.getExecutionPlan) ,输出 ExecutionPlan
{
"nodes": [{
"id": 1,
"type": "Source: Custom File Source",
"pact": "Data Source",
"contents": "Source: Custom File Source",
"parallelism": 1
}, {
"id": 2,
"type": "Split Reader: Custom File Source",
"pact": "Operator",
"contents": "Split Reader: Custom File Source",
"parallelism": 1,
"predecessors": [{
"id": 1,
"ship_strategy": "FORWARD",
"side": "second"
}]
}, {
"id": 3,
"type": "Flat Map",
"pact": "Operator",
"contents": "Flat Map",
"parallelism": 4,
"predecessors": [{
"id": 2,
"ship_strategy": "REBALANCE",
"side": "second"
}]
}, {
"id": 4,
"type": "Map",
"pact": "Operator",
"contents": "Map",
"parallelism": 4,
"predecessors": [{
"id": 3,
"ship_strategy": "FORWARD",
"side": "second"
}]
}, {
"id": 6,
"type": "Window(GlobalWindows(), CountTrigger, CountEvictor, SumAggregator, PassThroughWindowFunction)",
"pact": "Operator",
"contents": "Window(GlobalWindows(), CountTrigger, CountEvictor, SumAggregator, PassThroughWindowFunction)",
"parallelism": 3,
"predecessors": [{
"id": 4,
"ship_strategy": "HASH",
"side": "second"
}]
}, {
"id": 7,
"type": "Sink: Print to Std. Out",
"pact": "Data Sink",
"contents": "Sink: Print to Std. Out",
"parallelism": 3,
"predecessors": [{
"id": 6,
"ship_strategy": "FORWARD",
"side": "second"
}]
}]
}
json 数据通过 可视化

参考资料
Apache Flink 进阶教程(六):Flink 作业执行深度解析