Flink 1.11
Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。sql 在解析过程必然与 Catalog 交互,才能生成逻辑计划。
Catalog 是接口类,与外部数据源交互需要实现对应的 Catalog 。
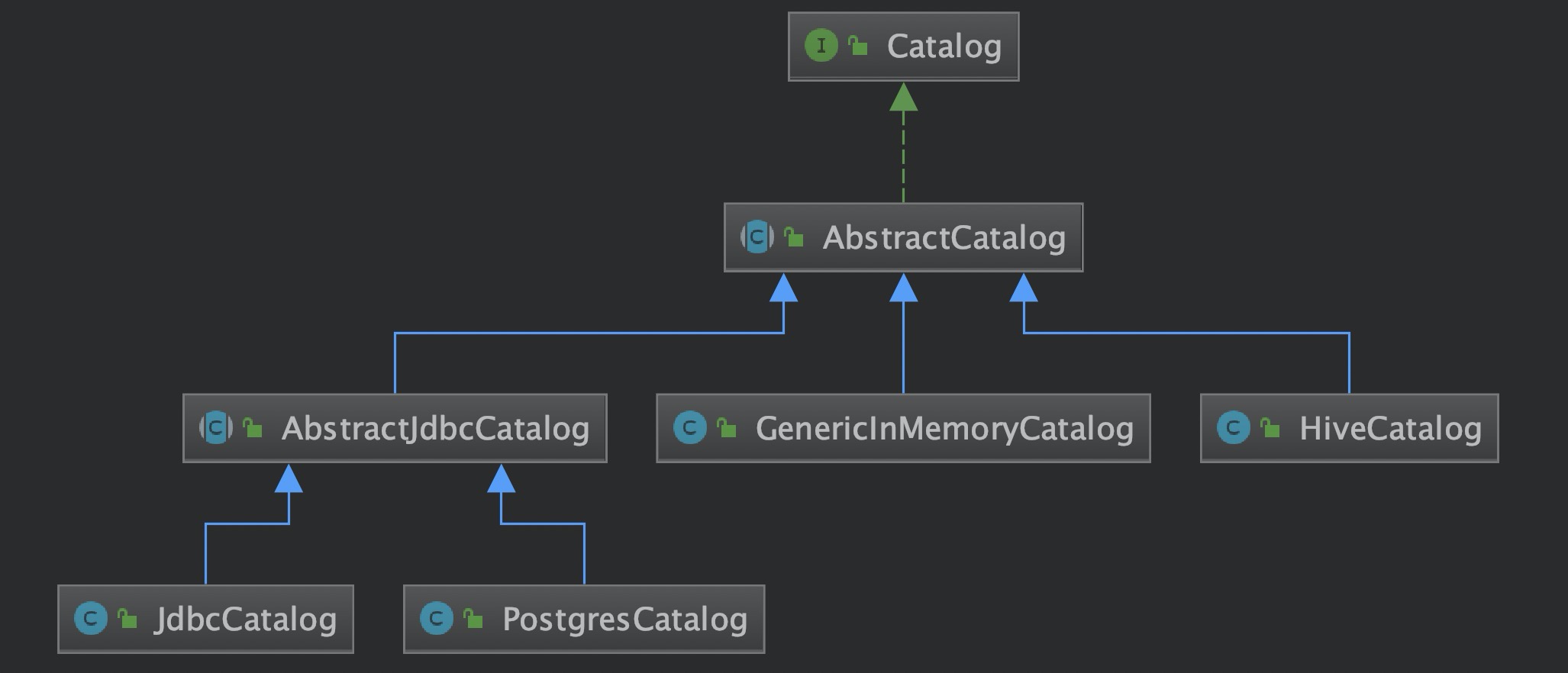
常用的数据源 Flink 都已实现 Catalog,可以在 Flink 直接与之交互(其实 JDBCCatalog 只有接口还没真正的实现)。 CatalogManager 可以同时在一个会话中挂载多个 Catalog,从而访问到多个不同的外部系统。下面介绍 Catalog 的管理和具体的实现方式。
CatalogManager
// org.apache.flink.table.catalog.CatalogManager
// 用于处理 catalog(例如表,视图,函数和类型)的管理器。它封装了所有可用的 catalog 并存储临时对象
public final class CatalogManager {
// 存储多个 catalog
private Map<String, Catalog> catalogs;
// 临时表,这些表会覆盖外部数据源相同名称的表
private Map<ObjectIdentifier, CatalogBaseTable> temporaryTables;
private String currentCatalogName;
private String currentDatabaseName;
// 注册 catalog
public void registerCatalog(String catalogName, Catalog catalog) {
if (catalogs.containsKey(catalogName)) {
throw new CatalogException(format("Catalog %s already exists.", catalogName));
}
catalogs.put(catalogName, catalog);
// hive 直接获取 client;jdbc 是测试连接是否正常
catalog.open();
}
// 注销 catalog
public void unregisterCatalog(String catalogName, boolean ignoreIfNotExists) {
if (catalogs.containsKey(catalogName)) {
Catalog catalog = catalogs.remove(catalogName);
// hive 释放 client;jdbc 只打印
catalog.close();
}
}
// 根据名称获取 catalog
public Optional<Catalog> getCatalog(String catalogName) {
return Optional.ofNullable(catalogs.get(catalogName));
}
// 当前 catatlog
public String getCurrentCatalog() {
return currentCatalogName;
}
public void setCurrentCatalog(String catalogName) throws CatalogNotExistException {
Catalog potentialCurrentCatalog = catalogs.get(catalogName);
...
// 切换 currentCatalogName
if (!currentCatalogName.equals(catalogName)) {
currentCatalogName = catalogName;
// 获取 catalog 默认的 database
currentDatabaseName = potentialCurrentCatalog.getDefaultDatabase();
...
}
}
// 获取分区
public Optional<CatalogPartition> getPartition(ObjectIdentifier tableIdentifier, CatalogPartitionSpec partitionSpec) {
Catalog catalog = catalogs.get(tableIdentifier.getCatalogName());
if (catalog != null) {
try {
return Optional.of(catalog.getPartition(tableIdentifier.toObjectPath(), partitionSpec));
} catch (PartitionNotExistException ignored) {
}
}
return Optional.empty();
}
...
}
CatalogManager 管理并封装 catalog,对 catalog 的访问必须经过 CatalogManager。
Catalog
catalog 定义了很多方法与外部数据源交互:
- Database 相关操作,方法名带 database
- Table 相关操作,方法名带 table
- View 相关操作,特殊的 table,自带特有方法 listView
- Partition 相关操作, 方法名带 partition
- udf 相关操作,方法名带 function
以 HiveCatalog 为例,介绍Flink 如何与 Hive 交互。
// org.apache.flink.table.catalog.hive.HiveCatalog
// hive metastore client,后续操作都由此 client 完成
private HiveMetastoreClientWrapper client;
// 创建数据库
public void createDatabase(String databaseName, CatalogDatabase database, boolean ignoreIfExists)
throws DatabaseAlreadyExistException, CatalogException {
...
Database hiveDatabase = HiveDatabaseUtil.instantiateHiveDatabase(databaseName, database);
try {
// 核心代码就一句,调用 hive metastore 创建数据库
client.createDatabase(hiveDatabase);
}
...
}
public CatalogBaseTable getTable(ObjectPath tablePath) throws TableNotExistException, CatalogException {
...
Table hiveTable = getHiveTable(tablePath);
return instantiateCatalogTable(hiveTable, hiveConf);
}
// 创建表
// org.apache.flink.table.catalog.CatalogManager
public void createTable(CatalogBaseTable table, ObjectIdentifier objectIdentifier, boolean ignoreIfExists) {
execute(
(catalog, path) -> catalog.createTable(path, table, ignoreIfExists),
objectIdentifier,
false,
"CreateTable");
}
// org.apache.flink.table.catalog.hive.HiveCatalog
public void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists)
throws TableAlreadyExistException, DatabaseNotExistException, CatalogException {
// 表已存在 异常
if (!databaseExists(tablePath.getDatabaseName())) {
throw new DatabaseNotExistException(getName(), tablePath.getDatabaseName());
}
// 实例化 hive metastore 中定义的 table
Table hiveTable = HiveTableUtil.instantiateHiveTable(tablePath, table, hiveConf);
...
// metastore 创建表
client.createTable(hiveTable);
}
public void createFunction(ObjectPath functionPath, CatalogFunction function, boolean ignoreIfExists)
throws FunctionAlreadyExistException, DatabaseNotExistException, CatalogException {
...
Function hiveFunction;
if (function instanceof CatalogFunctionImpl) {
// 实例化 hive metastore 中定义的 function
hiveFunction = instantiateHiveFunction(functionPath, function);
}
...
// metastore 创建 function
client.createFunction(hiveFunction);
...
}
HiveCatalog 就是对 hive metastore 的封装,使 Flink 程序可以使用 Hive 元数据。了解 HiveCatalog 实现原理之后,接下来以 sql 为例看看 Flink 中如何使用 catalog。
Table
在 Catalog 中,每一张表或视图都对应一个 CatalogBaseTable。
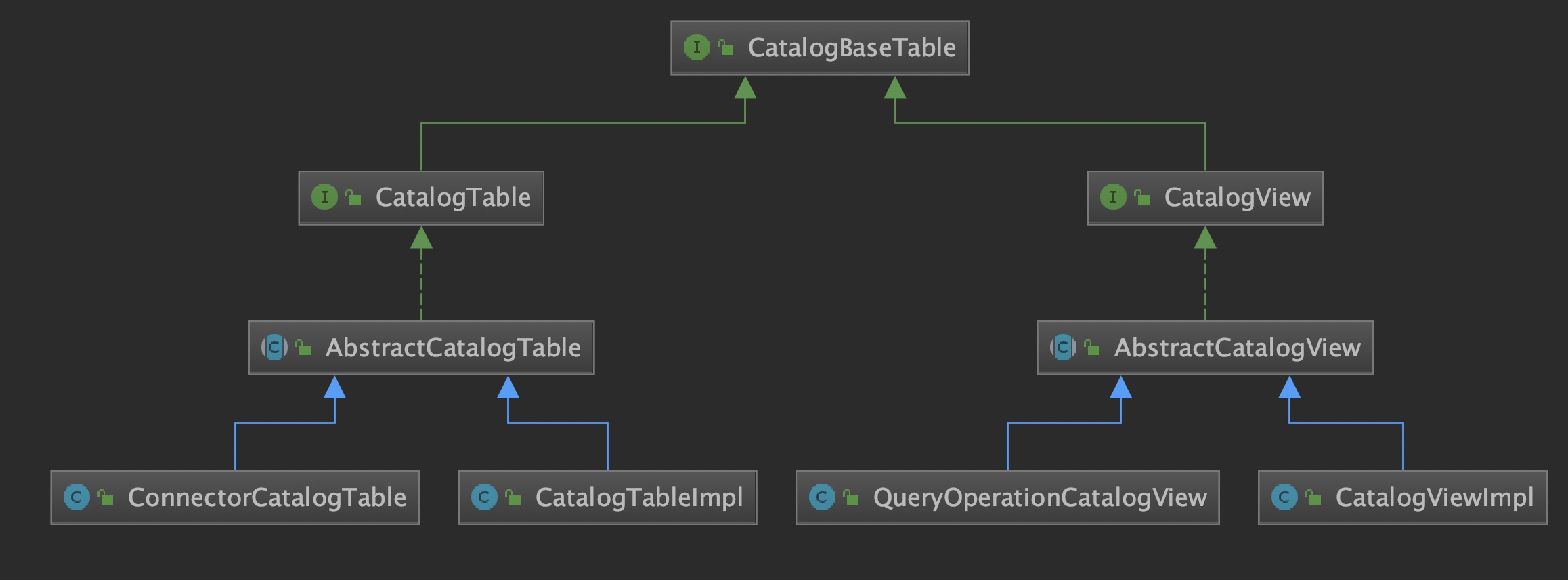
CatalogTableImpl/CatalogViewImpl:真实存在外部数据源的表
// org.apache.flink.table.catalog.hive.HiveCatalog
public CatalogBaseTable getTable(ObjectPath tablePath) throws TableNotExistException, CatalogException {
checkNotNull(tablePath, "tablePath cannot be null");
Table hiveTable = getHiveTable(tablePath);
// instantiateCatalogTable 返回 CatalogTableImpl/CatalogViewImpl
return instantiateCatalogTable(hiveTable, hiveConf);
}
ConnectorCatalogTable:向Catalog中注册的表,调用TableEnvironment.registerTableSource/registerTableSink(1.11 中一般使用 TemporaryTable 代替)QueryOperationCatalogView:sql query/Stream生成的QueryOperation,注册到 catalog
public QueryOperationCatalogView(QueryOperation queryOperation, String comment) {
super(
queryOperation.asSummaryString(),
queryOperation.asSummaryString(),
queryOperation.getTableSchema(),
new HashMap<>(),
comment);
this.queryOperation = queryOperation;
}
udf
向 catalog 注册 自定义函数
- registerFunction:临时函数,只在当前运行时生效,存储在
tempSystemFunctions - createFunction:注册到 catalog ,会直接在 hive 创建
udf