Flink 1.12.1
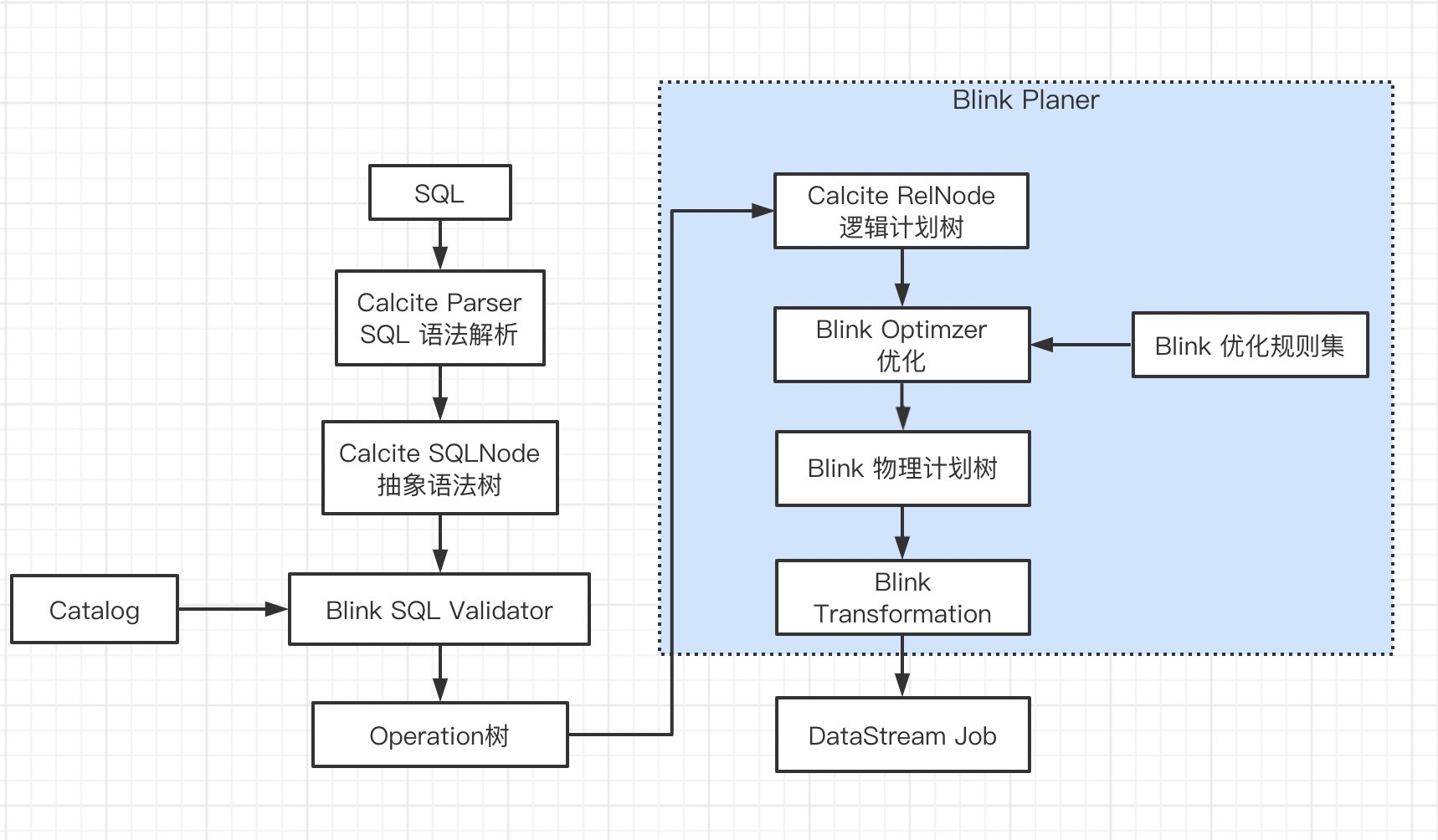
Flink SQL 解析和执行流程如下,本节剖析 SQL -> Operation 树的具体流程。
val env = StreamExecutionEnvironment.getExecutionEnvironment
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tEnv = StreamTableEnvironment.create(env,settings)
tEnv.createTemporaryFunction("split", classOf[SplitFunction])
tEnv.executeSql(
s"""
|CREATE TABLE kafka_table(
|words string
|)
|with(
|'connector' = 'kafka',
|'topic' = 'header_test',
|'properties.bootstrap.servers' = '$bootstrapServers',
|'properties.group.id' = 'bigdata_test_group',
|'format' = 'json',
|'scan.startup.mode' = 'latest-offset' -- 'scan.startup.mode' = 'timestamp'
|)
""".stripMargin)
tEnv.executeSql(
s"""
|CREATE TABLE print_table (
| word string,
| cnt INT
|) WITH (
| 'connector' = 'print'
|)
""".stripMargin)
tEnv.executeSql(
s"""
|insert into print_table
|select
|word,
|sum(cnt)
|from(
| select word,1 as cnt
| from kafka_table,LATERAL TABLE(split(words))
|) t
|group by word
""".stripMargin)
SQL 逻辑就是一个简单的 wordCount。
// org.apache.flink.table.api.internal.TableEnvironmentImpl#executeSql
public TableResult executeSql(String statement) {
// parser = ParserImpl
List<Operation> operations = parser.parse(statement);
if (operations.size() != 1) {
throw new TableException(UNSUPPORTED_QUERY_IN_EXECUTE_SQL_MSG);
}
return executeOperation(operations.get(0));
}
executeOperation 执行过程下节再讲,先看 parser 。
BlinkPlanner
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
val tEnv = StreamTableEnvironment.create(env,settings)
上述代码指定 StreamTableEnvironment 的 Planner 为 BlinkPlanner。
// org.apache.flink.table.api.EnvironmentSettings
public Builder useBlinkPlanner() {
this.plannerClass = BLINK_PLANNER_FACTORY; // org.apache.flink.table.planner.delegation.BlinkPlannerFactory
this.executorClass = BLINK_EXECUTOR_FACTORY; // org.apache.flink.table.planner.delegation.BlinkExecutorFactory
return this;
}
public Builder inStreamingMode() {
this.isStreamingMode = true;
return this;
}
// org.apache.flink.table.planner.delegation.BlinkPlannerFactory
public Planner create(
Map<String, String> properties,
Executor executor,
TableConfig tableConfig,
FunctionCatalog functionCatalog,
CatalogManager catalogManager) {
if (Boolean.valueOf(properties.getOrDefault(EnvironmentSettings.STREAMING_MODE, "true"))) {
return new StreamPlanner(executor, tableConfig, functionCatalog, catalogManager);
} else {
return new BatchPlanner(executor, tableConfig, functionCatalog, catalogManager);
}
}
Blink Planner 相比于原生的 Flink Planner,增加很多功能:
- Blink Planner 对代码生成机制做了改进、对部分算子进行了优化,提供了丰富实用的新功能,如维表 join、Top N、MiniBatch、流式去重、聚合场景的数据倾斜优化等新功能。
- Blink Planner 的优化策略是基于公共子图的优化算法,包含了基于成本的优化(CBO)和基于规则的优化(CRO)两种策略,优化更为全面。同时,Blink Planner 支持从 catalog 中获取数据源的统计信息,这对 CBO 优化非常重要。
- Blink Planner 提供了更多的内置函数,更标准的 SQL 支持。
ParserImpl
确定 Planner 后获取对应的 Parser 。
// org.apache.flink.table.planner.delegation.PlannerBase
private val parser: Parser = new ParserImpl(
// 元数据管理
catalogManager,
new JSupplier[FlinkPlannerImpl] {
override def get(): FlinkPlannerImpl = createFlinkPlanner
},
new JSupplier[CalciteParser] {
override def get(): CalciteParser = plannerContext.createCalciteParser()
},
new JFunction[TableSchema, SqlExprToRexConverter] {
override def apply(t: TableSchema): SqlExprToRexConverter = {
sqlExprToRexConverterFactory.create(plannerContext.getTypeFactory.buildRelNodeRowType(t))
}
}
)
// org.apache.flink.table.planner.delegation.ParserImpl
public ParserImpl(
CatalogManager catalogManager,
Supplier<FlinkPlannerImpl> validatorSupplier,
Supplier<CalciteParser> calciteParserSupplier,
Function<TableSchema, SqlExprToRexConverter> sqlExprToRexConverterCreator) {
this.catalogManager = catalogManager;
this.validatorSupplier = validatorSupplier;
this.calciteParserSupplier = calciteParserSupplier;
this.sqlExprToRexConverterCreator = sqlExprToRexConverterCreator;
}
ParserImpl 包含重要组件
CatalogManager:元数据管理FlinkPlannerImpl:Flink 和 Calcite 联系的桥梁,执行 parse(sql),validate(sqlNode),rel(sqlNode) 操作CalciteParser:SQL 解析成SqlNode
FlinkSqlParserImpl
一:SQL -> SqlNode
// org.apache.flink.table.planner.delegation.ParserImpl
public List<Operation> parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
// parse the sql query => FlinkSqlParserImpl.parse
SqlNode parsed = parser.parse(statement);
Operation operation =
SqlToOperationConverter.convert(planner, catalogManager, parsed)
.orElseThrow(() -> new TableException("Unsupported query: " + statement));
return Collections.singletonList(operation);
}
// org.apache.flink.table.planner.calcite.CalciteParser#parse
public SqlNode parse(String sql) {
try {
// config = FlinkSqlParserFactories
SqlParser parser = SqlParser.create(sql, config);
// SqlParser.parseStmt => parseQuery => FlinkSqlParser.parseSqlStmtEof
return parser.parseStmt();
} catch (SqlParseException e) {
throw new SqlParserException("SQL parse failed. " + e.getMessage(), e);
}
}
// org.apache.calcite.sql.parser.SqlParser
public static SqlParser create(String sql, Config config) {
return create(new SourceStringReader(sql), config);
}
public static SqlParser create(Reader reader, Config config) {
// FlinkSqlParserFactories.create = FlinkSqlParserImpl/FlinkHiveSqlParserImpl
SqlAbstractParserImpl parser =
config.parserFactory().getParser(reader);
return new SqlParser(parser, config);
}
FlinkSqlParserImpl 解析 SQL 语句调用链:
- SqlParser.parseStmt
- SqlParser.parseQuery
- FlinkSqlParser.parseSqlStmtEof
- FlinkSqlParser.SqlStmtEof
- FlinkSqlParser.SqlStmt:FlinkSqlParserImplConstants 语法匹配(insert/select等)
- FlinkSqlParser.SqlStmtEof
- FlinkSqlParser.parseSqlStmtEof
- SqlParser.parseQuery
FlinkSqlParserImpl 是原生 Calcite SqlParser 的子类,Flink 实现自己独有的 SQL 语法(FlinkHiveSqlParserImpl 可以解析 Hive 语法)。
Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 SqlNode。
Flink 除了Calcite 中 Parser.jj 文件中的语法,还有定制的 Freemarker 模板。JavaCC 编译后生成
FlinkSqlParserImpl及其附属的类。
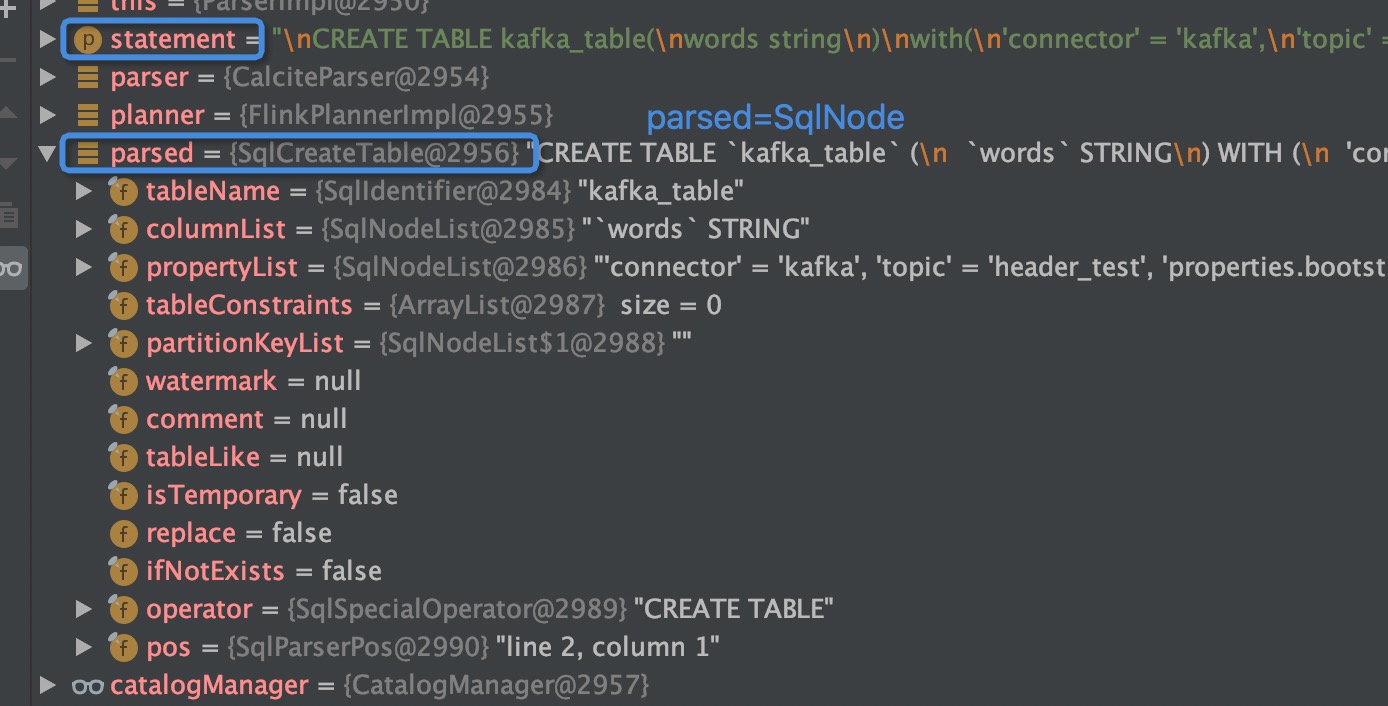
DDL 的 SqlNode 打印如下:
FlinkPlannerImpl
二:sql 校验
Parser 将 SQL 语句解析成 SqlNode,接下来就是校验 SqlNode以及将 SqlNode 转换成 Operation。
// org.apache.flink.table.api.internal.TableEnvironmentImpl#TableEnvironmentImpl
this.catalogManager.setCatalogTableSchemaResolver(
new CatalogTableSchemaResolver(planner.getParser(), isStreamingMode));
// org.apache.flink.table.planner.operations.SqlToOperationConverter#convert
public static Optional<Operation> convert(
FlinkPlannerImpl flinkPlanner, CatalogManager catalogManager, SqlNode sqlNode) {
// 一:SQL 语义校验
final SqlNode validated = flinkPlanner.validate(sqlNode);
// 二:SqlNode -> Operation
SqlToOperationConverter converter =
new SqlToOperationConverter(flinkPlanner, catalogManager);
if (validated instanceof SqlCreateCatalog) {
return Optional.of(converter.convertCreateCatalog((SqlCreateCatalog) validated));
......
// RichSqlInsert 类型
else if (validated instanceof RichSqlInsert) {
SqlNodeList targetColumnList = ((RichSqlInsert) validated).getTargetColumnList();
if (targetColumnList != null && targetColumnList.size() != 0) {
throw new ValidationException("Partial inserts are not supported");
}
return Optional.of(converter.convertSqlInsert((RichSqlInsert) validated));
// org.apache.flink.table.planner.calcite.FlinkPlannerImpl
def validate(sqlNode: SqlNode): SqlNode = {
val validator = getOrCreateSqlValidator()
validate(sqlNode, validator)
}
def getOrCreateSqlValidator(): FlinkCalciteSqlValidator = {
if (validator == null) {
val catalogReader = catalogReaderSupplier.apply(false)
validator = createSqlValidator(catalogReader)
}
validator
}
private def validate(sqlNode: SqlNode, validator: FlinkCalciteSqlValidator): SqlNode = {
try {
sqlNode.accept(new PreValidateReWriter(
validator, typeFactory))
// do extended validation.
sqlNode match {
case node: ExtendedSqlNode =>
node.validate()
case _ =>
}
// DDL,insert,show sql语句不用参与 SQL 校验
if (sqlNode.getKind.belongsTo(SqlKind.DDL)
|| sqlNode.getKind == SqlKind.INSERT
|| sqlNode.getKind == SqlKind.CREATE_FUNCTION
|| sqlNode.getKind == SqlKind.DROP_FUNCTION
|| sqlNode.getKind == SqlKind.OTHER_DDL
|| sqlNode.isInstanceOf[SqlShowCatalogs]
|| sqlNode.isInstanceOf[SqlShowCurrentCatalog]
|| sqlNode.isInstanceOf[SqlShowDatabases]
|| sqlNode.isInstanceOf[SqlShowCurrentDatabase]
|| sqlNode.isInstanceOf[SqlShowTables]
|| sqlNode.isInstanceOf[SqlShowFunctions]
|| sqlNode.isInstanceOf[SqlShowViews]
|| sqlNode.isInstanceOf[SqlShowPartitions]
|| sqlNode.isInstanceOf[SqlRichDescribeTable]) {
return sqlNode
}
sqlNode match {
case explain: SqlExplain =>
// sql 查看执行计划
val validated = validator.validate(explain.getExplicandum)
explain.setOperand(0, validated)
explain
case _ =>
// 通常是 select 语句需要校验
validator.validate(sqlNode)
}
}
catch {
case e: RuntimeException =>
throw new ValidationException(s"SQL validation failed. ${e.getMessage}", e)
}
}
以SqlNode = RichSqlInsert 为例, insert 类型不用参与校验。RichSqlInsert 中必然是包含其他 SqlNode(不然要插入的数据哪里来)。
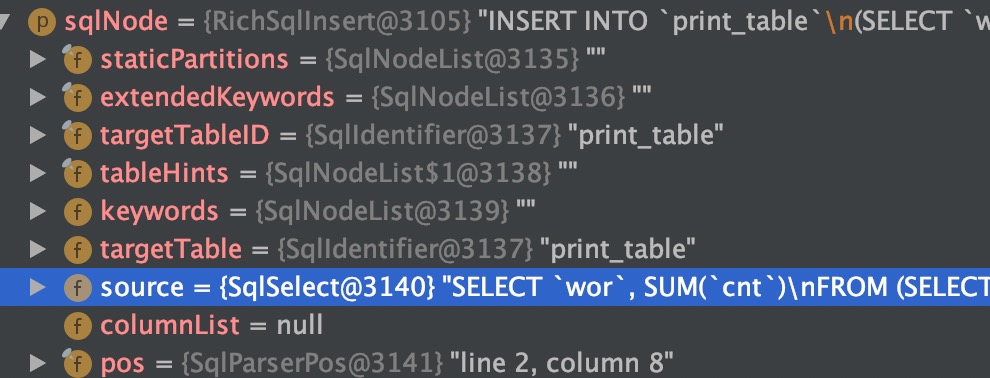
虽然 RichSqlInsert 不用参与校验,但其内部的 SqlSelect 还是要校验。
//org.apache.flink.table.sqlexec.SqlToOperationConverter#convertSqlInsert
private Operation convertSqlInsert(RichSqlInsert insert) {
// get name of sink table
List<String> targetTablePath = ((SqlIdentifier) insert.getTargetTable()).names;
UnresolvedIdentifier unresolvedIdentifier = UnresolvedIdentifier.of(targetTablePath);
ObjectIdentifier identifier = catalogManager.qualifyIdentifier(unresolvedIdentifier);
// insert.getSource() 是 SqlSelect Node,需要校验
PlannerQueryOperation query =
(PlannerQueryOperation)
SqlToOperationConverter.convert(
flinkPlanner, catalogManager, insert.getSource())
.orElseThrow(
() ->
new TableException(
"Unsupported node type "
+ insert.getSource()
.getClass()
.getSimpleName()));
// identifier 是 insertTable
// query 是 select operationn
return new CatalogSinkModifyOperation(
identifier,
query,
insert.getStaticPartitionKVs(),
insert.isOverwrite(),
Collections.emptyMap());
}
CatalogSinkModifyOperation
- identifier:要插入数据表的路径,catalog.database.table
- query:数据的来源 PlannerQueryOperation,内部包含逻辑计划树
FlinkCalciteSqlValidator
SQL 校验类,继承 SqlValidatorImpl。
// org.apache.calcite.sql.validate.SqlValidatorImpl#validate
public SqlNode validate(SqlNode topNode) {
SqlValidatorScope scope = new EmptyScope(this);
scope = new CatalogScope(scope, ImmutableList.of("CATALOG"));
final SqlNode topNode2 = validateScopedExpression(topNode, scope);
final RelDataType type = getValidatedNodeType(topNode2);
Util.discard(type);
return topNode2;
}
private SqlNode validateScopedExpression(
SqlNode topNode,
SqlValidatorScope scope) {
SqlNode outermostNode = performUnconditionalRewrites(topNode, false);
cursorSet.add(outermostNode);
top = outermostNode;
TRACER.trace("After unconditional rewrite: {}", outermostNode);
if (outermostNode.isA(SqlKind.TOP_LEVEL)) {
registerQuery(scope, null, outermostNode, outermostNode, null, false);
}
// SqlNode.validate
outermostNode.validate(this, scope);
if (!outermostNode.isA(SqlKind.TOP_LEVEL)) {
// force type derivation so that we can provide it to the
// caller later without needing the scope
deriveType(scope, outermostNode);
}
TRACER.trace("After validation: {}", outermostNode);
return outermostNode;
}
最终是会调用 SqlValidatorImpl.validateNamespace。
SqlToOperationConverter
三:SqlNode -> Operation
到这里,说明 SQL 通过语法和语义校验,SQL 是没有问题的。接下来需要将 SqlNode 转化为 Operation 树。
SqlCreateTable
创建表为例,通过 SQL 校验后 converter.createTableConverter.convertCreateTable((SqlCreateTable) validated)。
// org.apache.flink.table.planner.operations.SqlCreateTableConverter#convertCreateTable
Operation convertCreateTable(SqlCreateTable sqlCreateTable) {
sqlCreateTable.getTableConstraints().forEach(validateTableConstraint);
// 解析 SqlCreateTable 为 Flink 内部表结构 CatalogTable
CatalogTable catalogTable = createCatalogTable(sqlCreateTable);
UnresolvedIdentifier unresolvedIdentifier =
UnresolvedIdentifier.of(sqlCreateTable.fullTableName());
ObjectIdentifier identifier = catalogManager.qualifyIdentifier(unresolvedIdentifier);
return new CreateTableOperation(
identifier,
catalogTable,
sqlCreateTable.isIfNotExists(),
sqlCreateTable.isTemporary());
}
CreateTableOperation
- identifier:表全路径 => catalog.database.table
- catalogTable:表结构
PlannerQueryOperation
query 会转化为 PlannerQueryOperation,PlannerQueryOperation 包含 RelNode 树(逻辑计划树)。
converter.convertSqlQuery(validated)
// org.apache.flink.table.planner.operations.SqlToOperationConverter#convertSqlQuery
private Operation convertSqlQuery(SqlNode node) {
return toQueryOperation(flinkPlanner, node);
}
private PlannerQueryOperation toQueryOperation(FlinkPlannerImpl planner, SqlNode validated) {
// 转化为关系树
RelRoot relational = planner.rel(validated); // sqlToRelConverter.convertQuery
return new PlannerQueryOperation(relational.project()); // LogicalProject.create
}
ExecuteOperation
四:执行
Operation 对应着 DQL、DML、DDL,对于 DDL 来说它只是增加元数据信息,没有实质的操作直接执行即可;而其他两者都是查询 Operation,包含着逻辑计划树需要后续优化再执行。
DDL
// org.apache.flink.table.api.internal.TableEnvironmentImpl#executeOperation
private TableResult executeOperation(Operation operation) {
if (operation instanceof ModifyOperation) {
// insert 操作,还需要优化
return executeInternal(Collections.singletonList((ModifyOperation) operation));
} else if (operation instanceof CreateTableOperation) {
// DDL,将 opeartion 中的 catalogTable 添加到 对应的 catalog 中
CreateTableOperation createTableOperation = (CreateTableOperation) operation;
if (createTableOperation.isTemporary()) {
catalogManager.createTemporaryTable(
createTableOperation.getCatalogTable(),
createTableOperation.getTableIdentifier(),
createTableOperation.isIgnoreIfExists());
} else {
catalogManager.createTable(
createTableOperation.getCatalogTable(),
createTableOperation.getTableIdentifier(),
createTableOperation.isIgnoreIfExists());
}
return TableResultImpl.TABLE_RESULT_OK;
...
看到这里,一条 Creat Table 语句已执行完毕,它被解析成 CatalogTable 添加到 Catalog 中。
参考资料
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程
Flink 源码阅读笔记(15)- Flink SQL 整体执行框架