视频地址:https://developer.aliyun.com/topic/ffa2020/live#live
pdf地址:https://developer.aliyun.com/article/780107?spm=a2c6h.12873581.0.dArticle780107.57232634r5B3mH&groupCode=sc
12.13 上午
Flink 统一引擎
- Unaligned Checkpoint:不对齐 checkpoint
- 解决反压情况也能做 Checkpoint
- 将 Chanel 中的未处理数据也当作是 State ,存储到后端
- 后期优化:正常时
Aligned Checkpoint,反压时Unaligned Checkpoint
- Approximate Failover:更加灵活的容错方式
- 发生错误时单点重启而不是全图重启
- 单点重启 能减少任务重启的时间,提高系统可用性但会丢失数据
- Nexmark:Streaming Benchmark
- 流处理 SQL 测试工具
- https://github.com/nexmark/nexmark
- AI on Flink
- https://github.com/alibaba/flink-ai-extended
- AI 服务架构
Flink 助力美团数仓增量生产
- ODS 数据准备:ods 层数据实时接入,不必为准备数据(抽取/合并)耗费1-2小时
- ETL 增量生产:类似 hudi 增量(未实现)
12.13 下午
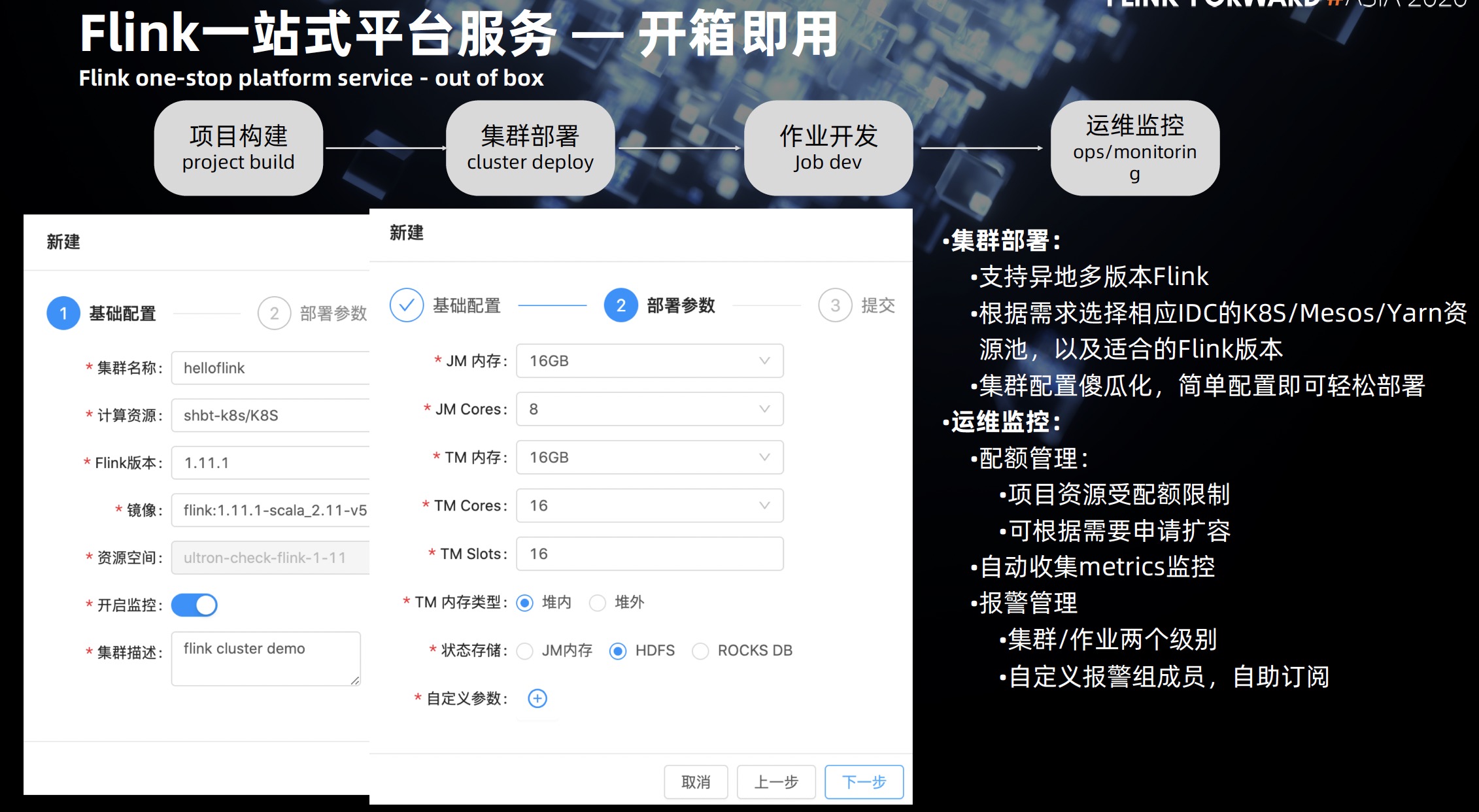
快手基于Apache Flink的持续优化实践
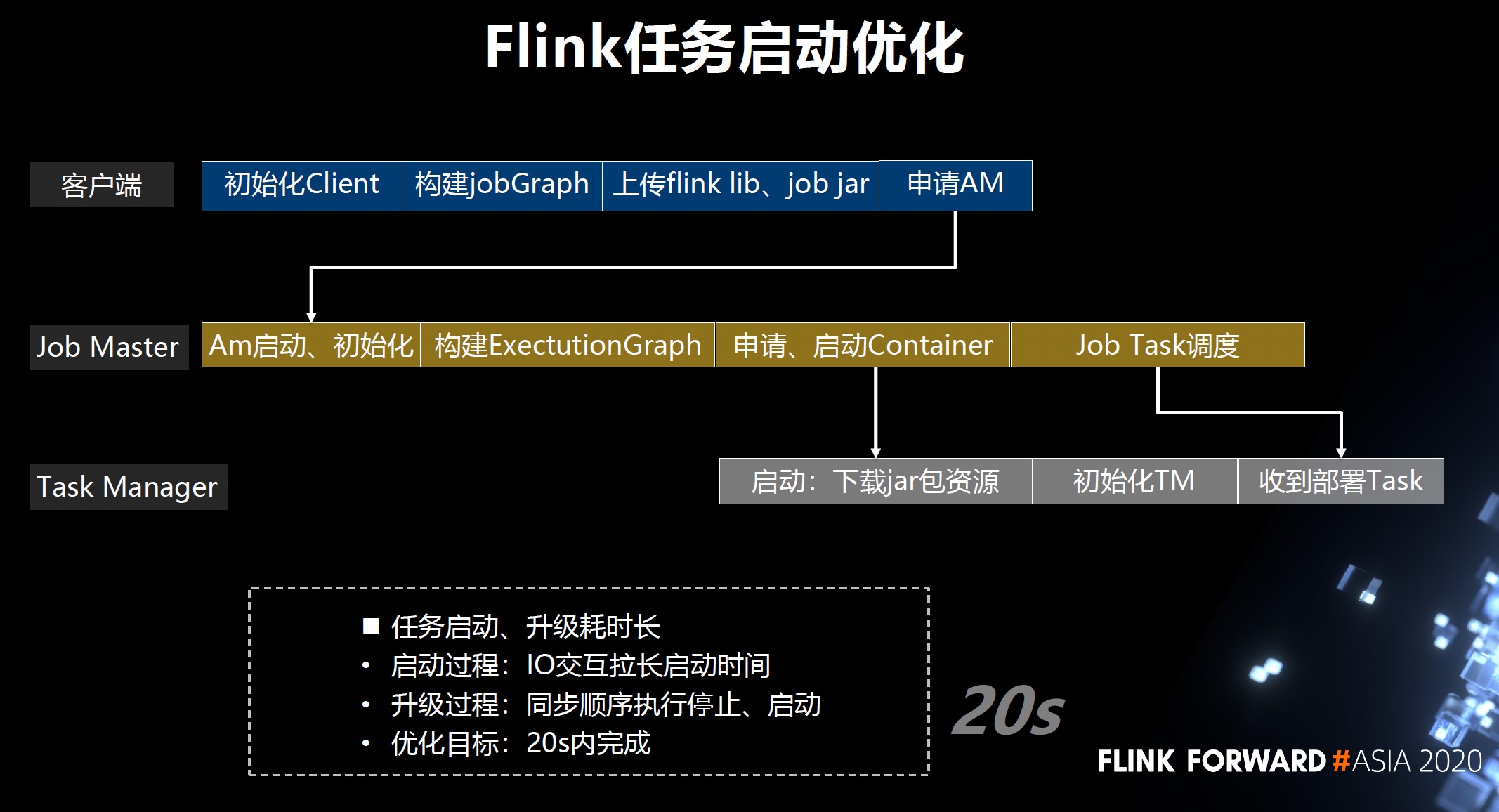
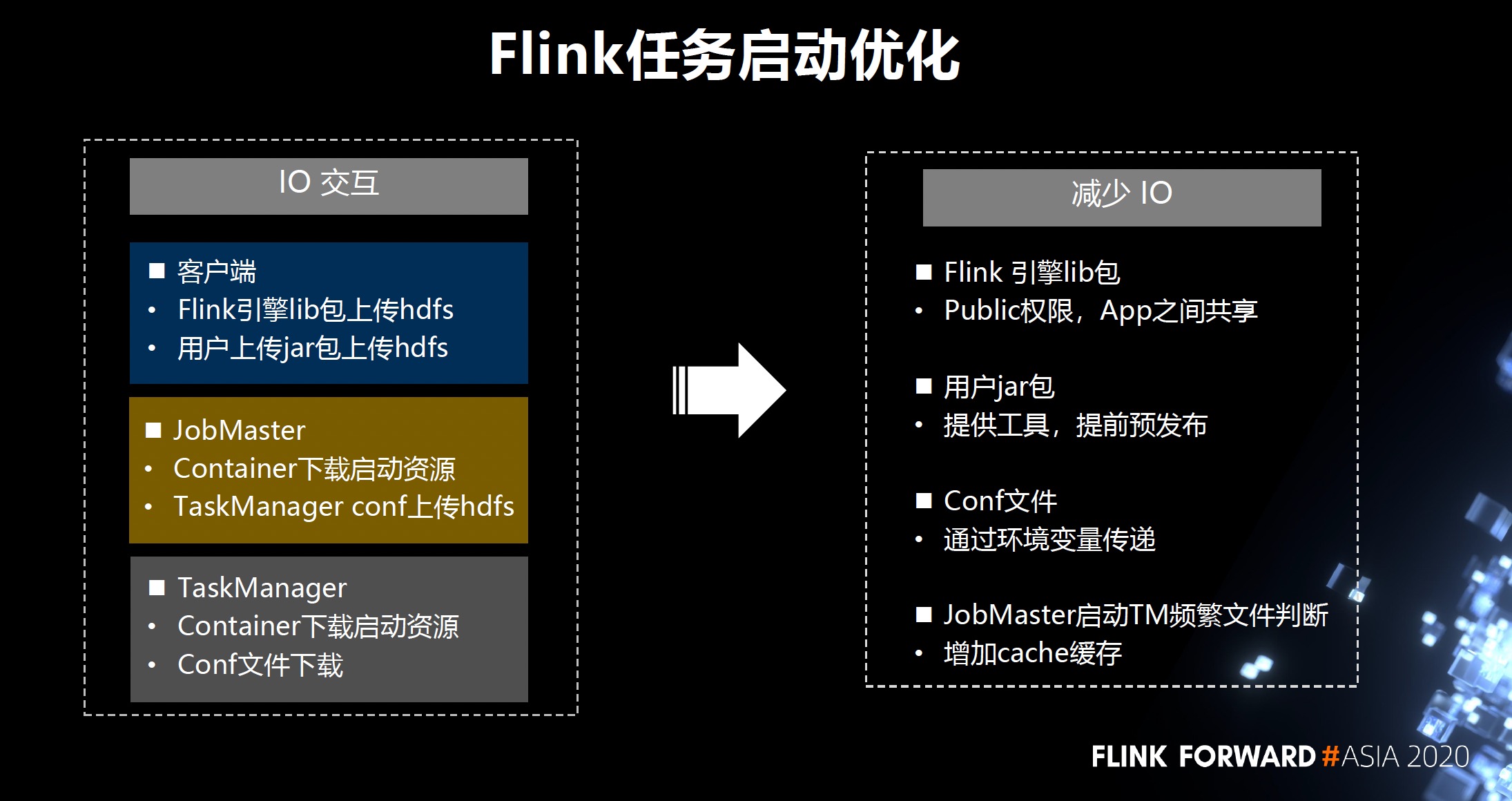
- 任务启动:启动优化
- Client:初始化 Client -> 构建 JobGraph -> 上传 job和lib jar 至 HDFS -> 申请 AM
- JM:AM 启动和初始化 -> 构建 ExectutionGraph -> 申请和启动 Container -> Job Task 调度
- TM:启动:下载 jar -> 初始化 TM -> 部署 Task
-
Flink SQL UDF 复用:
- udf 结果 Cache ,相同参数传入时直接返回 Cache 结果

Bigo实时计算平台建设实践

- 元数据打通:
- kafka:无需定义 DDL,直接使用 kafka table
- 日志收集到 ES:快速排错
- JM 和 TM 日志
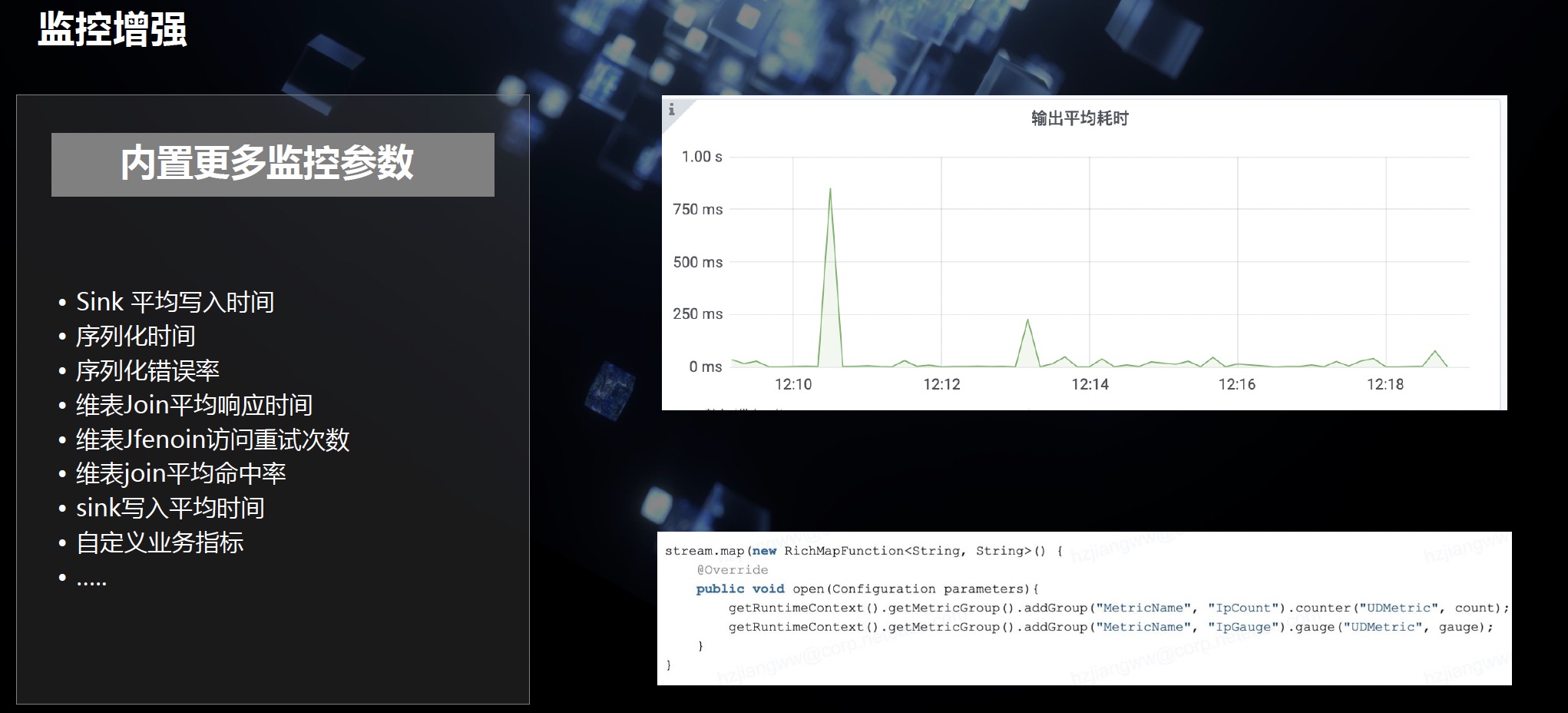
Flink SQL在云音乐的产品化实践
- Table Source 优化插件:在 source 和 sql 逻辑计算之间,利用 AOP 插入 Operator,扩大并行度加快序列化
- 血缘信息
- 监控增强
Apache Flink在京东的实践与优化
Flink on k8s
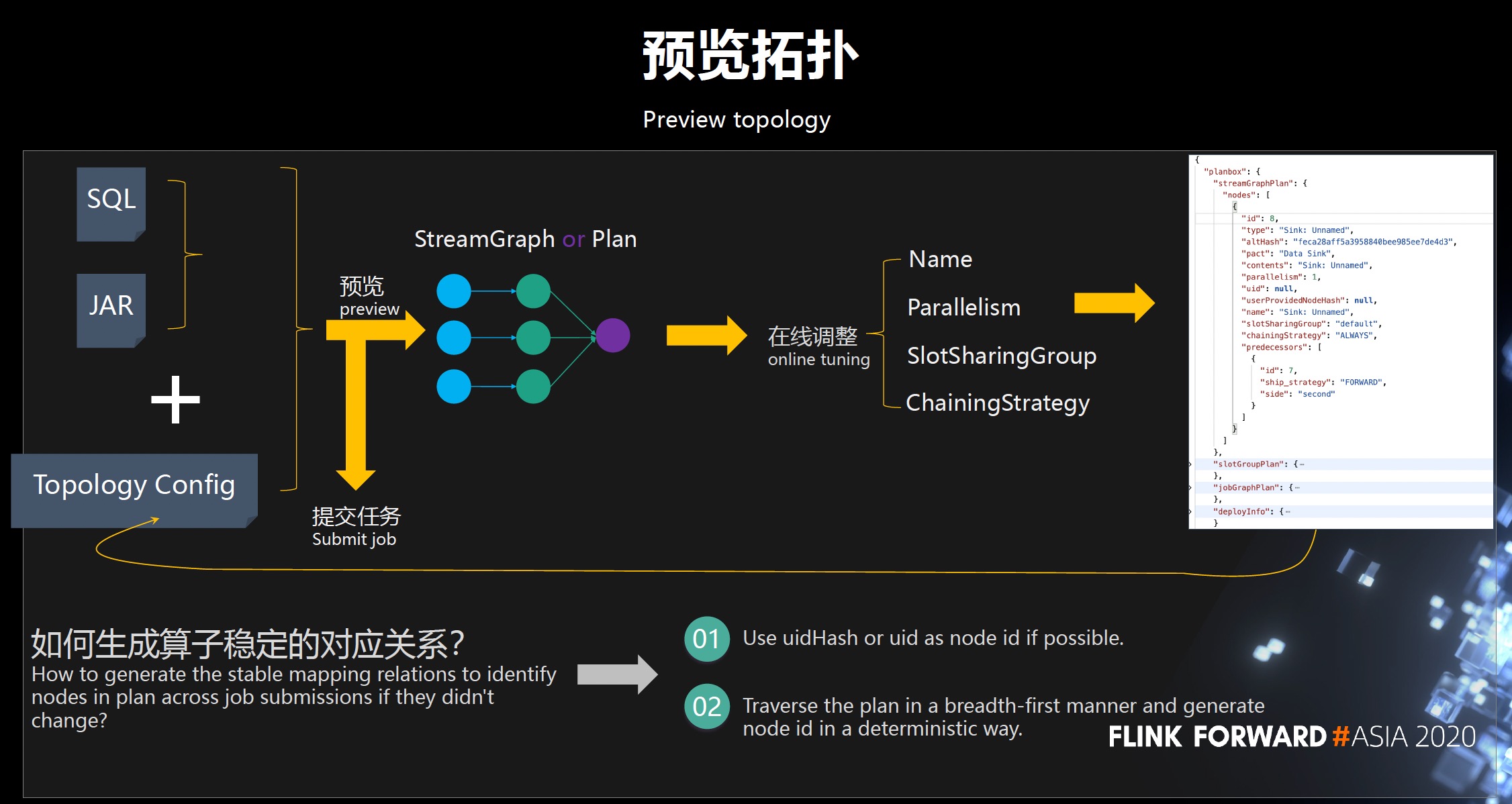
- 预览拓扑图:JobGraph -> 设定uid,并行度
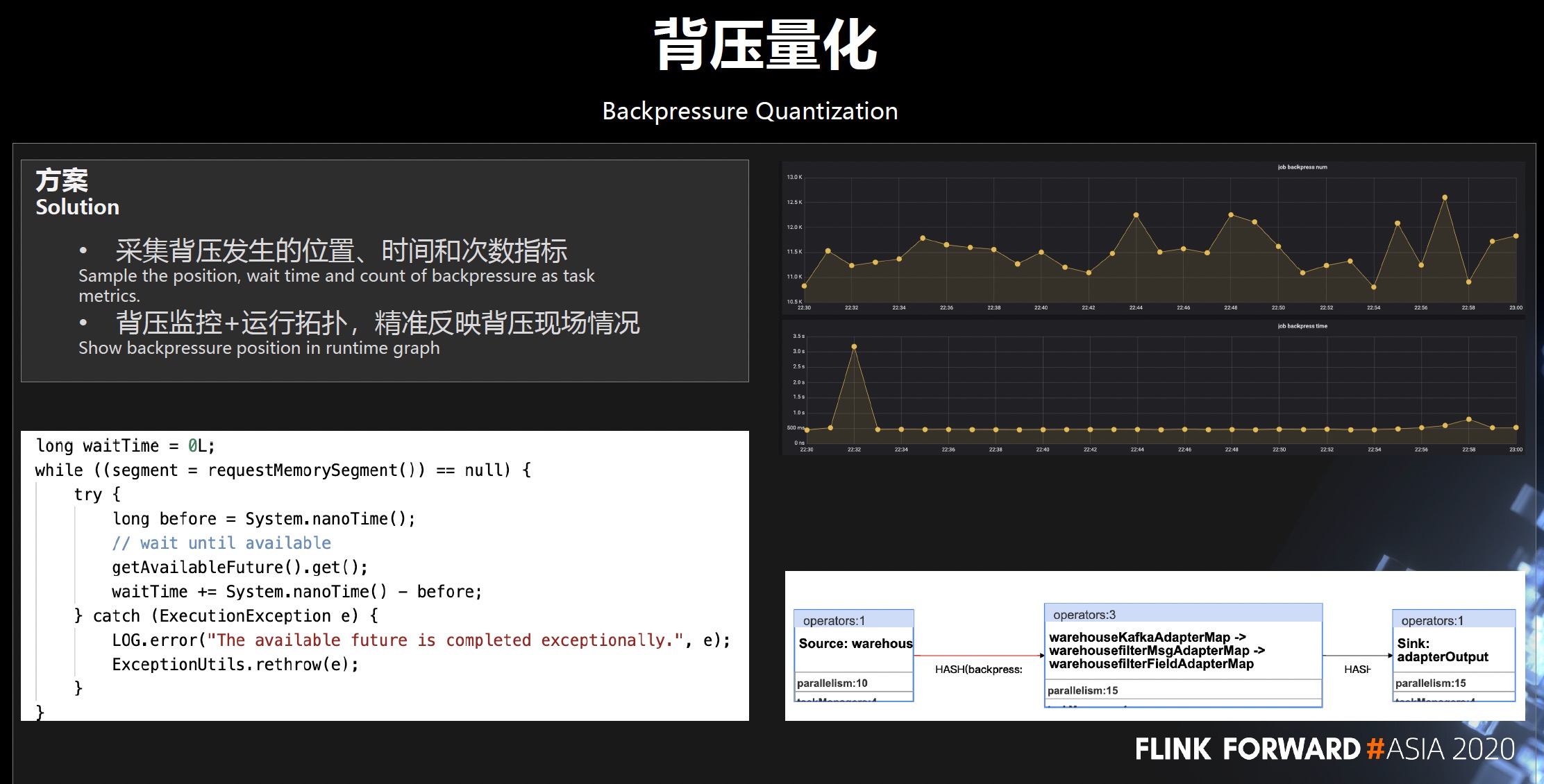
- 背压量化
- 文件系统支持多配置
Flink 在有赞的实践和应用
Flink on k8s
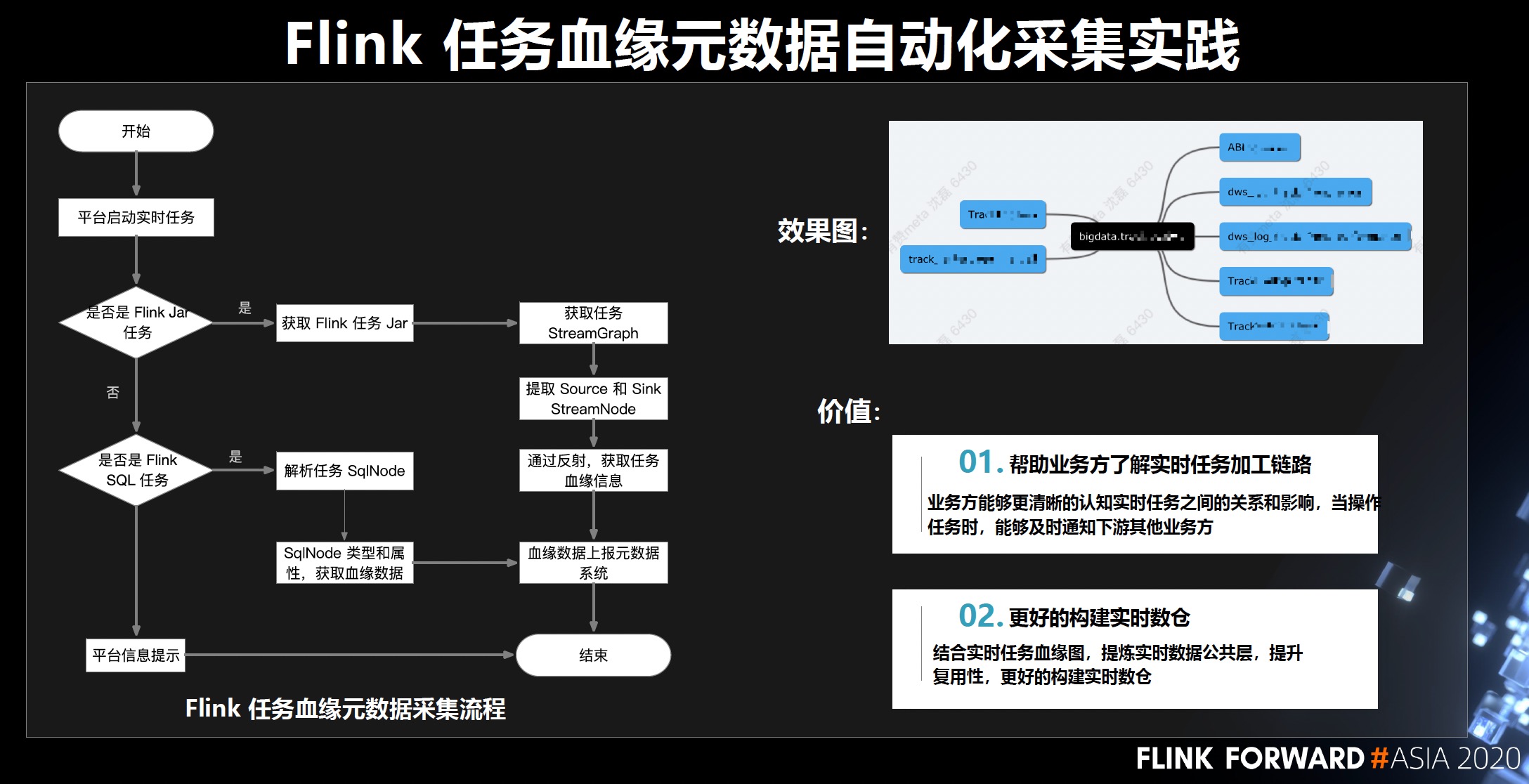
- 血缘元数据自动化采集
Flink在58同城应用与实践
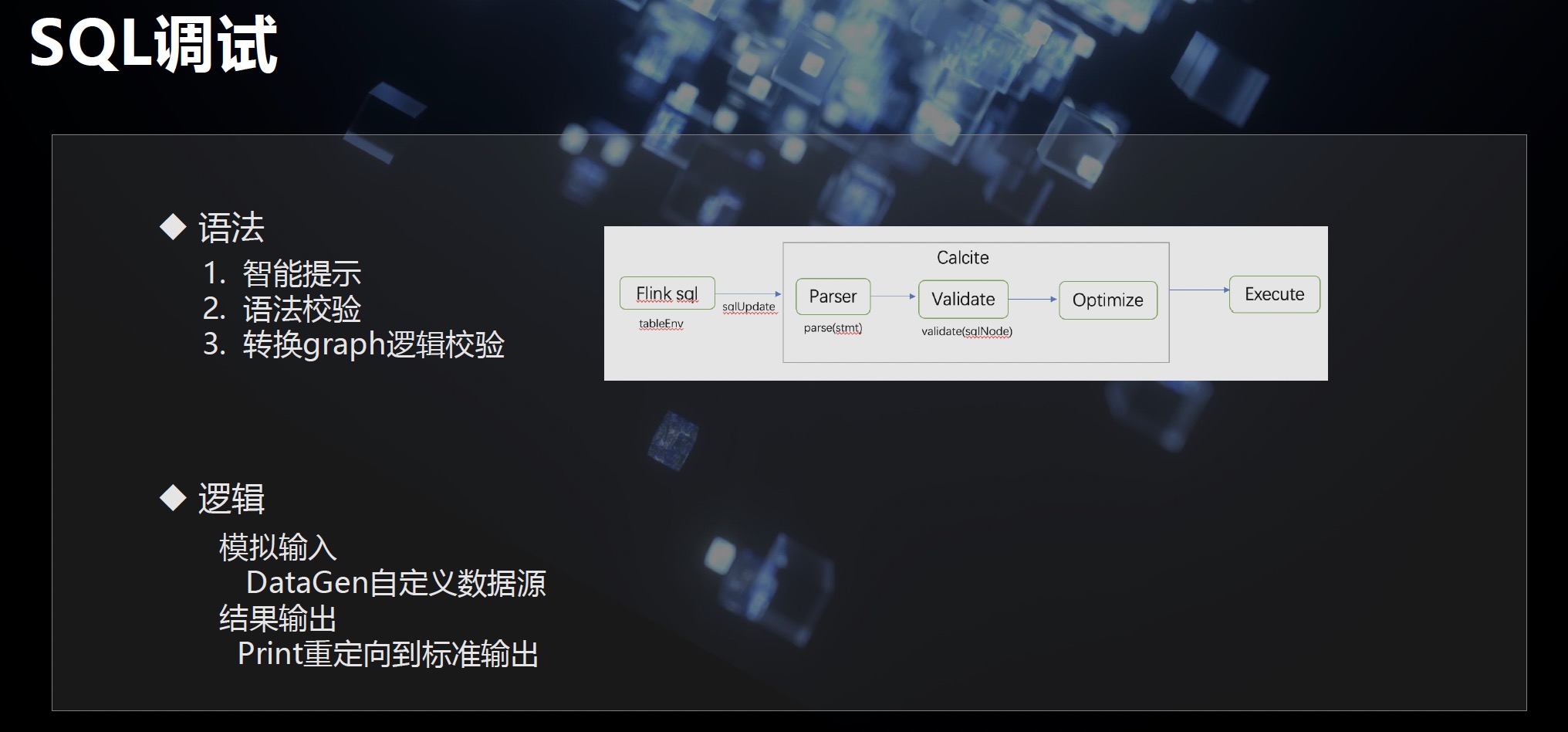
- sql 语法语法校验:Calcite parser
12.14 上午
好未来-批流融合实时平台在教育行业的实践
- SQL 开发流程
- 部署
流批一体技术在天猫双11的应用
- 流批统一:分钟/小时累计指标
Flink在小米的平台化实践
- Auto DDL:拉取数据,自动生成 create table 语句
- UDF 管理
- 在线调试:
- 语法检测
- source 数据
- 立即 run
- 实时写入 Doris:
- 消费积压:最后回答
- Flink on Yarn 启动优化
- 作业智能诊断:处理 flink log ,匹配规则,输出事件
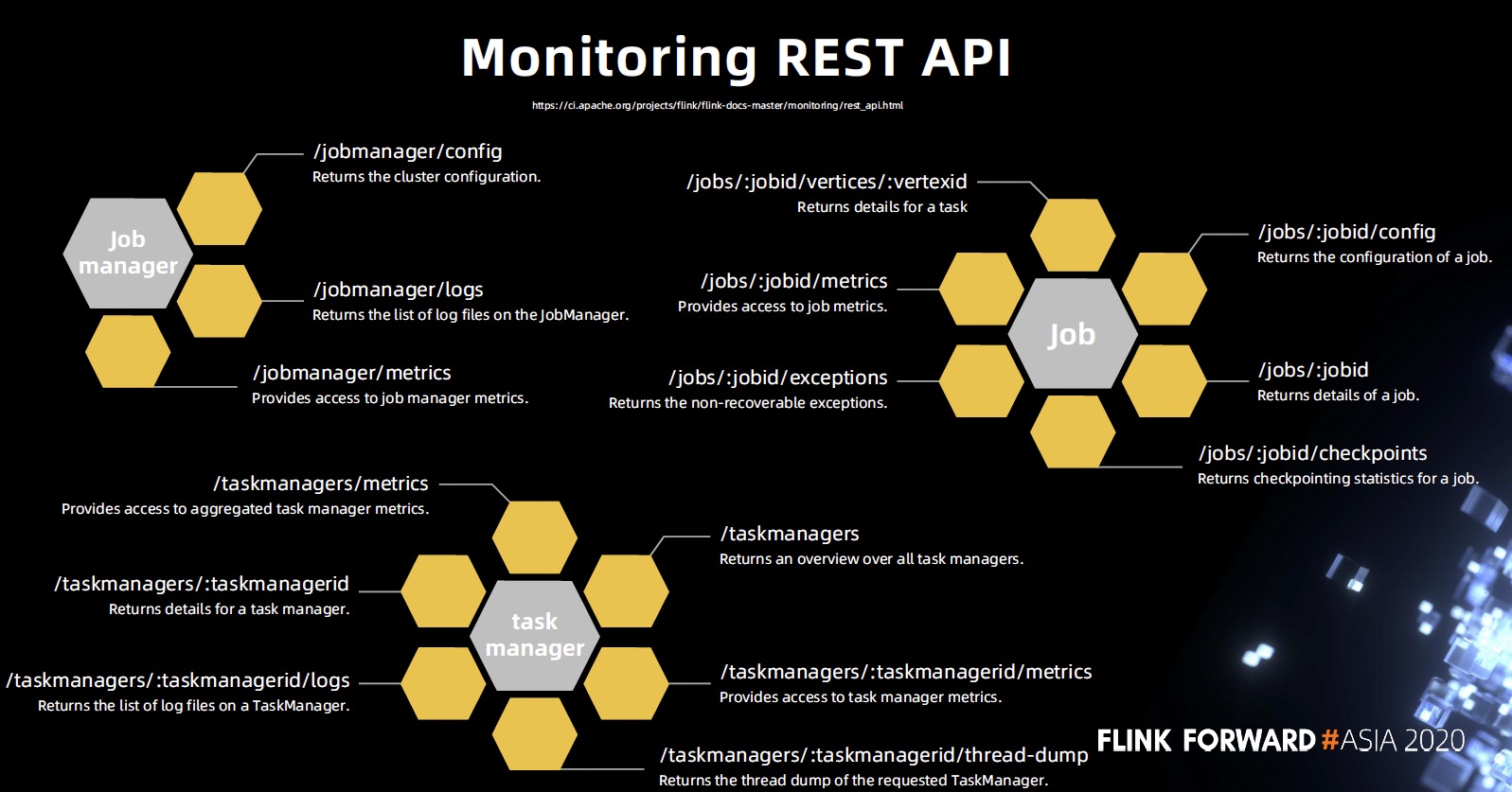
基于 Monitoring REST API 的 Flink 轻量级作业诊断
重点
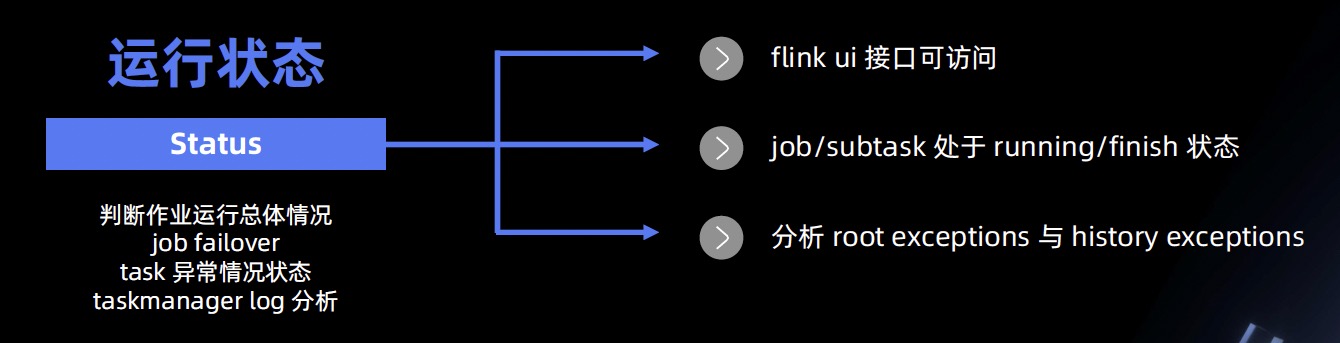
- 运行状态
- UI 接口是否可访问
- job/subTask
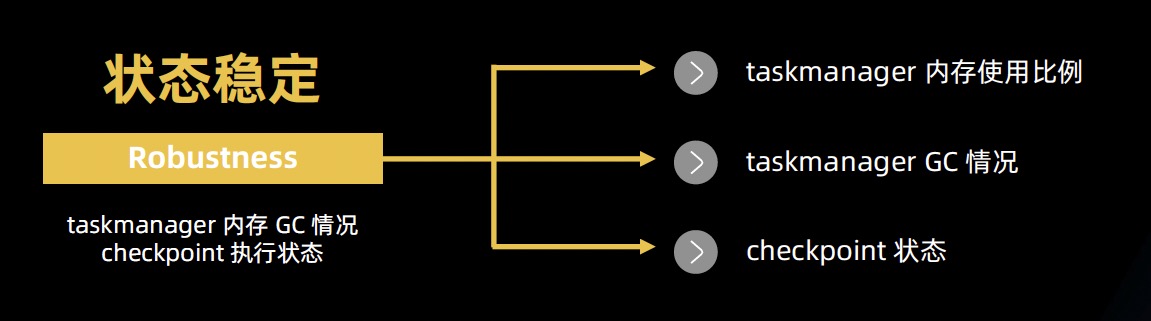
- 状态稳定
- TM 内存使用比例
- TM GC
- Checkpoint 状态
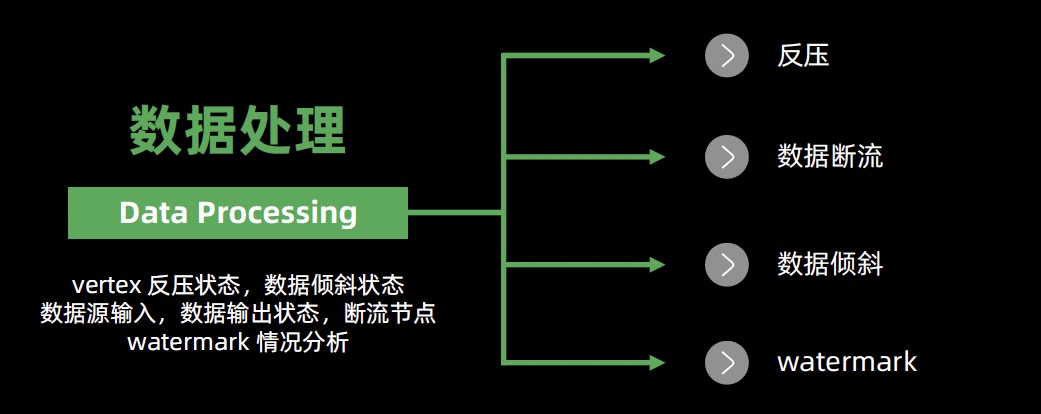
- 数据处理
- 反压
- 数据断流
- 数据倾斜
- watermark
Flink on Zeppelin:现在和未来
重要
暂时不支持 Yarn per job 模式
12.14 下午
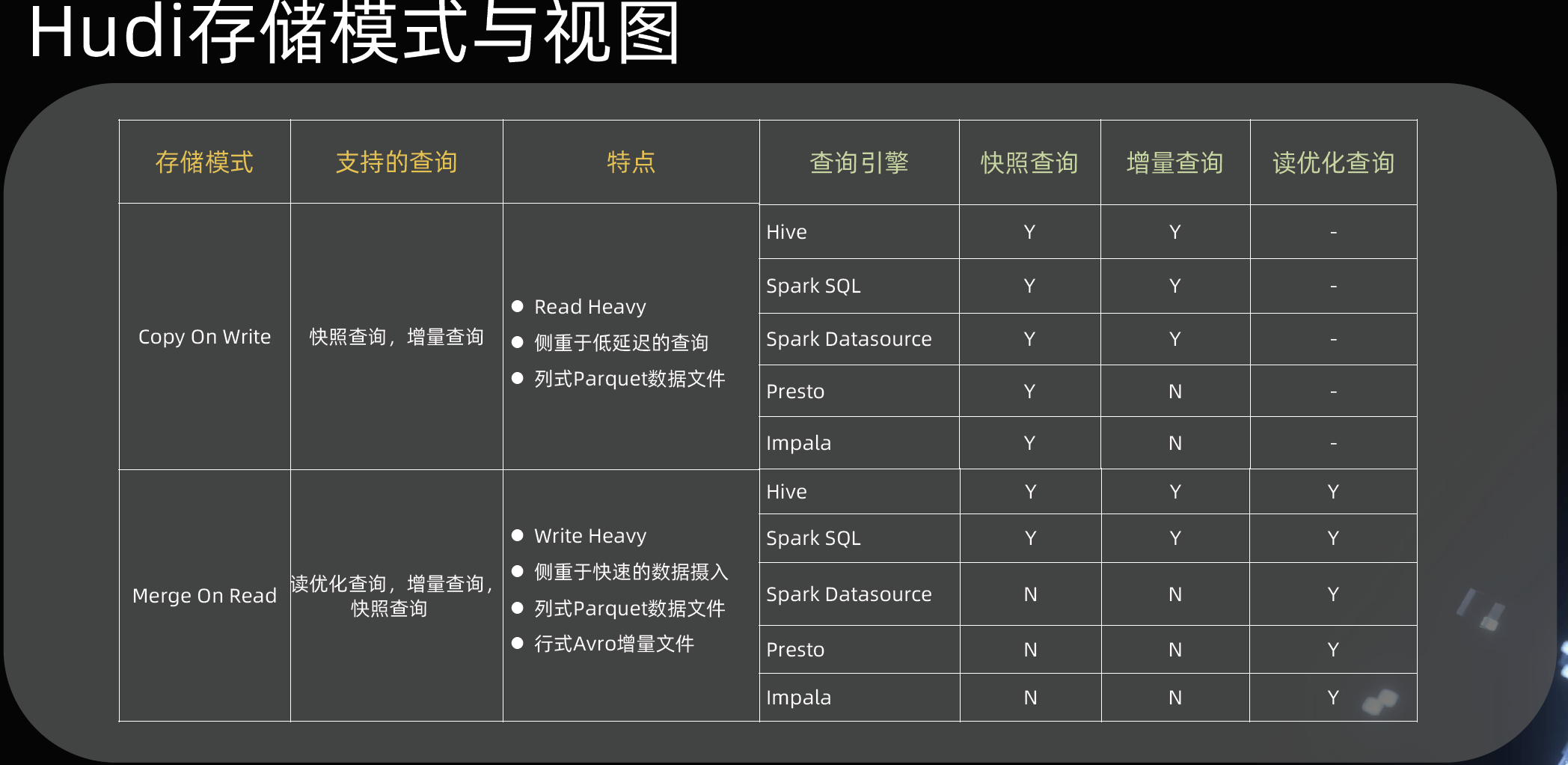
融合趋势下基于Flink Kylin Hudi湖仓一体的大数据生态体系
Flink on Kubernetes生产实践
Flink Connector 的架构解析及最佳开发实践
FLIP-27、FLIP-143
Flink 和 Pulsar 的批流融合
爱奇艺实时大数据生态体系的演进
- 维度退化:维表 join 后再提高给业务,而不是每个业务各自去 join 维表(浪费资源)
- 图形化生成任务而不是写 SQL
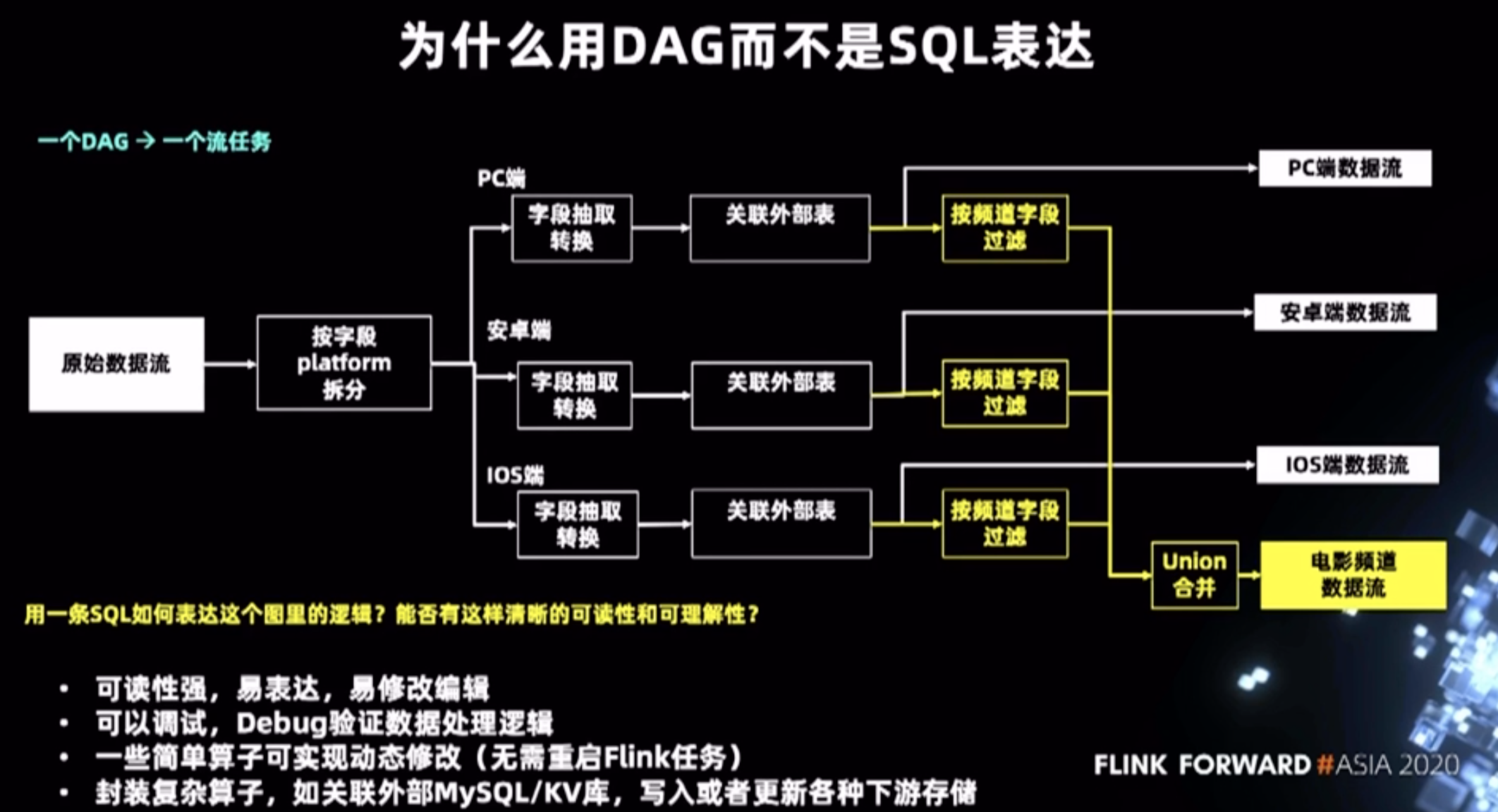
- 数仓就是做预计算
Flink 实时计算在小红书几个场景的应用
- 推荐算法基础数据
借助Flink与Pulsar,BIGO 打造实时消息处理系统
12.15 上午
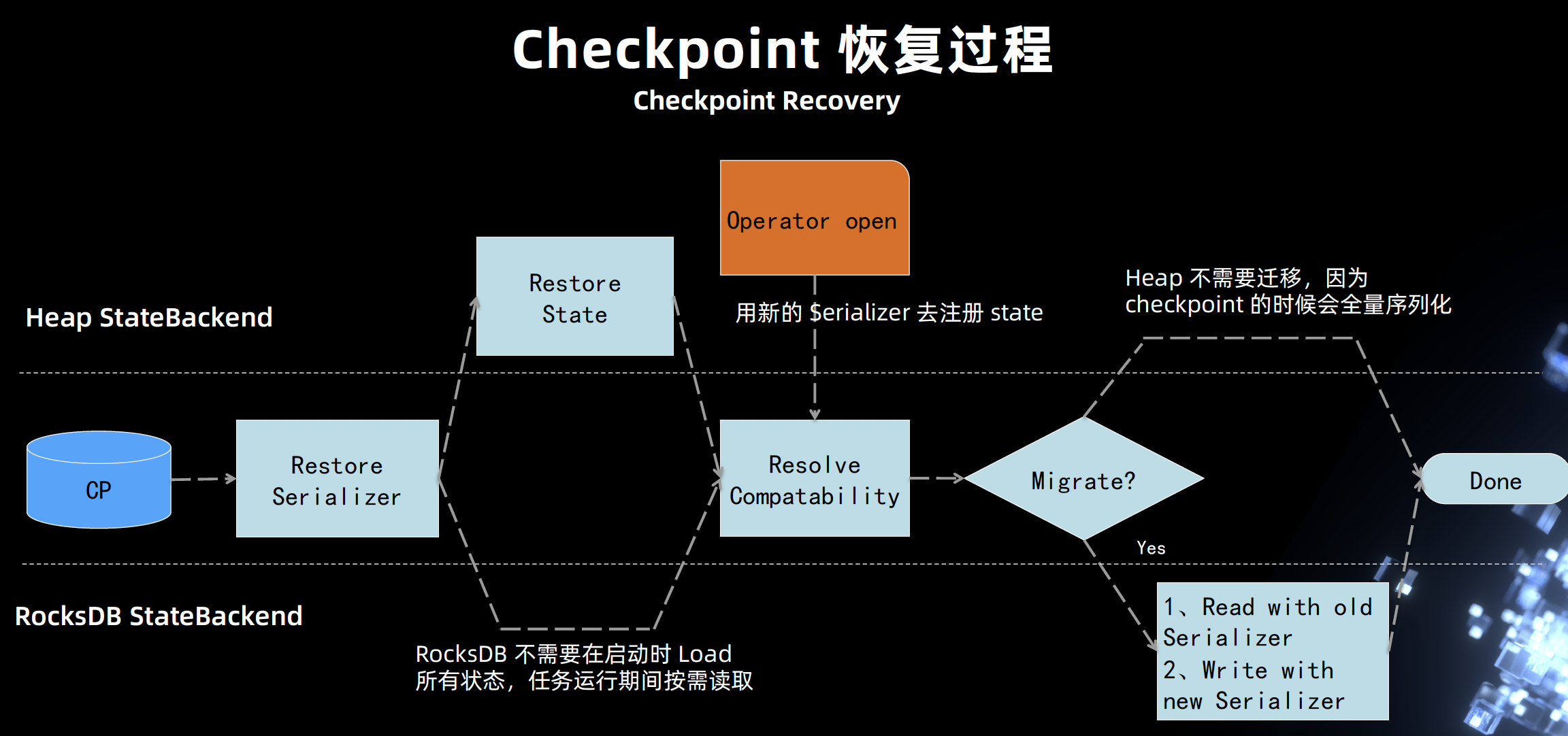
Flink State Backend Improvements and Evolution in the Recent Year
- SpillableState
- RockDB
- block cache
- FLIP-19238
- profilling 排查
- JVM Overhead:增大内存比例,防止 native memory 溢出,被 kill
- Tuning CheckPoint (flink doc)
超大规模 Flink 调度优化
- 启动时间优化
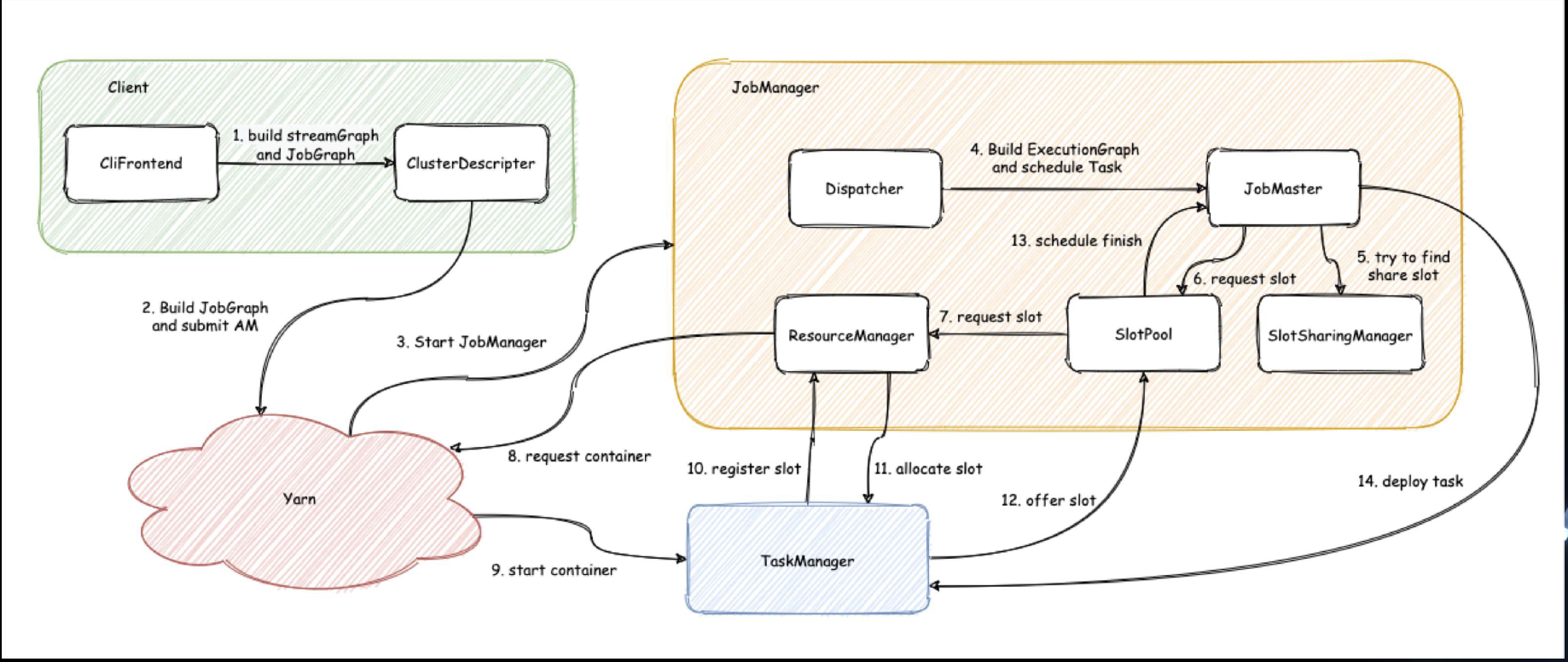
Single Task Recovery and Regional Checkpoint
重要
Flink如何实时分析Iceberg数据湖的CDC数据
非常重要,后续研究 iceberg 时细看
网易流批一体的实时数仓平台实践
Apache Flink在汽车之家的应用及实践
- 基于 Catalog 的元数据管理
- UDXF 管理
- 监控报警及日志收集
- 作业评分流程
Flink 在顺丰的实践应用
任务运维
腾讯看点基于Flink构建万亿数据量下的实时数仓及实时查询系统
Flink + ClickHouse P23
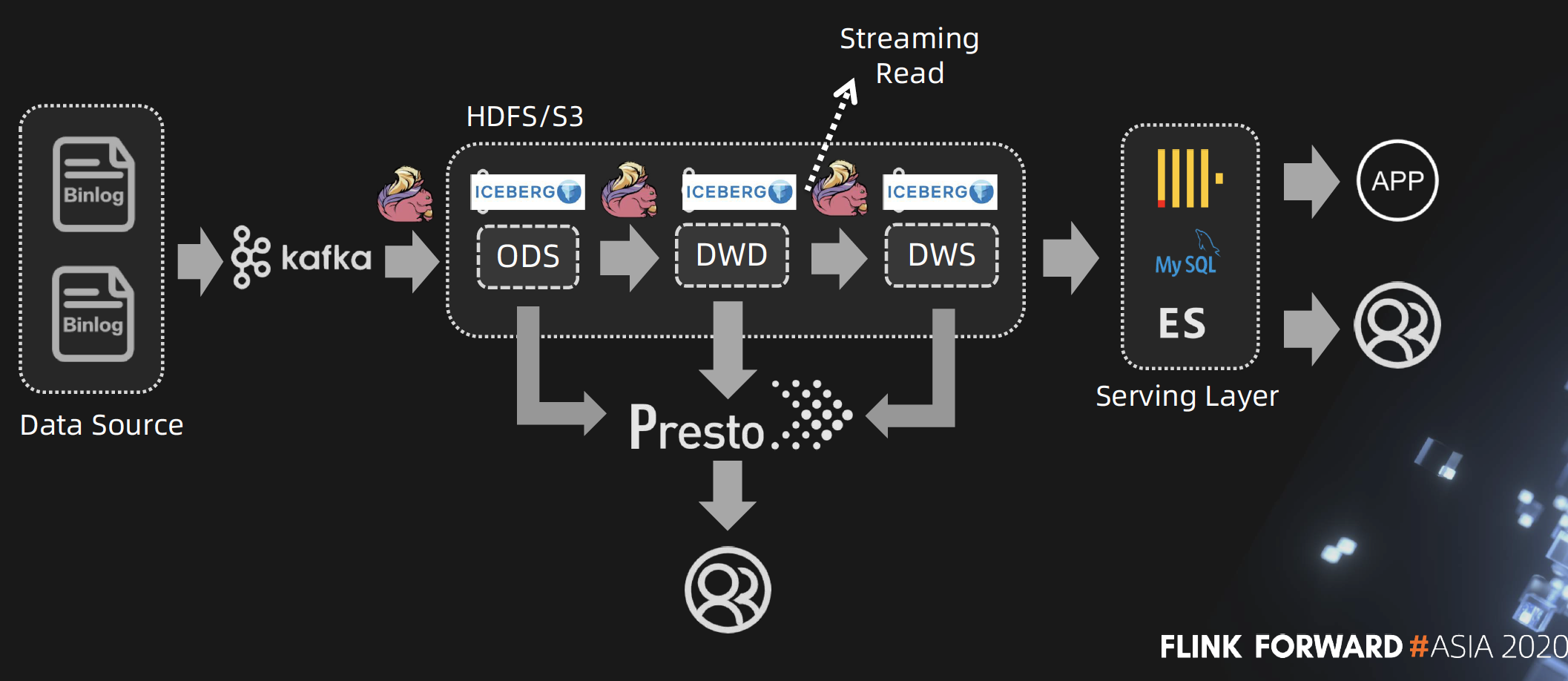
腾讯基于Flink + Iceberg 全场景实时数仓的建设实践
Flink + Iceberg
12.15 下午
基于 Flink DataStream API 的流批一体处理
- 批模式下的 eventtime 只有开始和结束两个时间点
Flink SQL在字节跳动的优化&实践
-
SQL 调试:采样真实数据执行
-
SQL 层的自定义 Window
-
维表优化
- 事实表 keyby 再 join 维表,提高Cache命中率(joinkey 固定)
- mini batch 维表,提高join 性能
-
状态恢复
- DAG 修改,operationID 生成方式
- 聚合算子,RowData
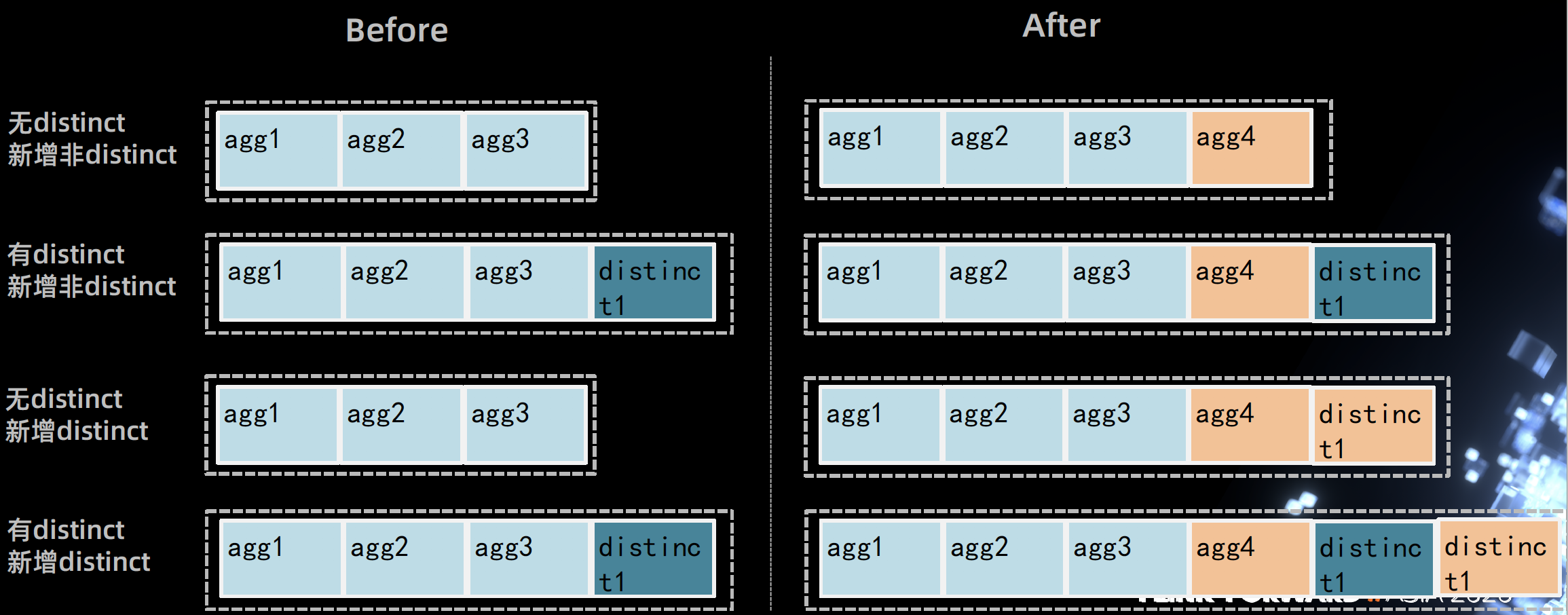
Flink 1.12 资源管理新特性
多看几遍
- 内存使用在 UI 展示
- 任务平铺
- AI/GPU
美团Flink可用性建设实践
非常重要:99.9%的可用性
- 可用性
- 作业未运行:监控作业运行状态
- 作业不稳定:监控作业重启频率
- 作业不产出:监控作业消费情况
- 数据产出延迟:监控消费延迟情况
- 可用性优化:JobManager HA 减少对 Zookeeper 依赖
- 减少故障频率
- 减少故障影响面
- 减少故障持续时间
- 定时 savepoint
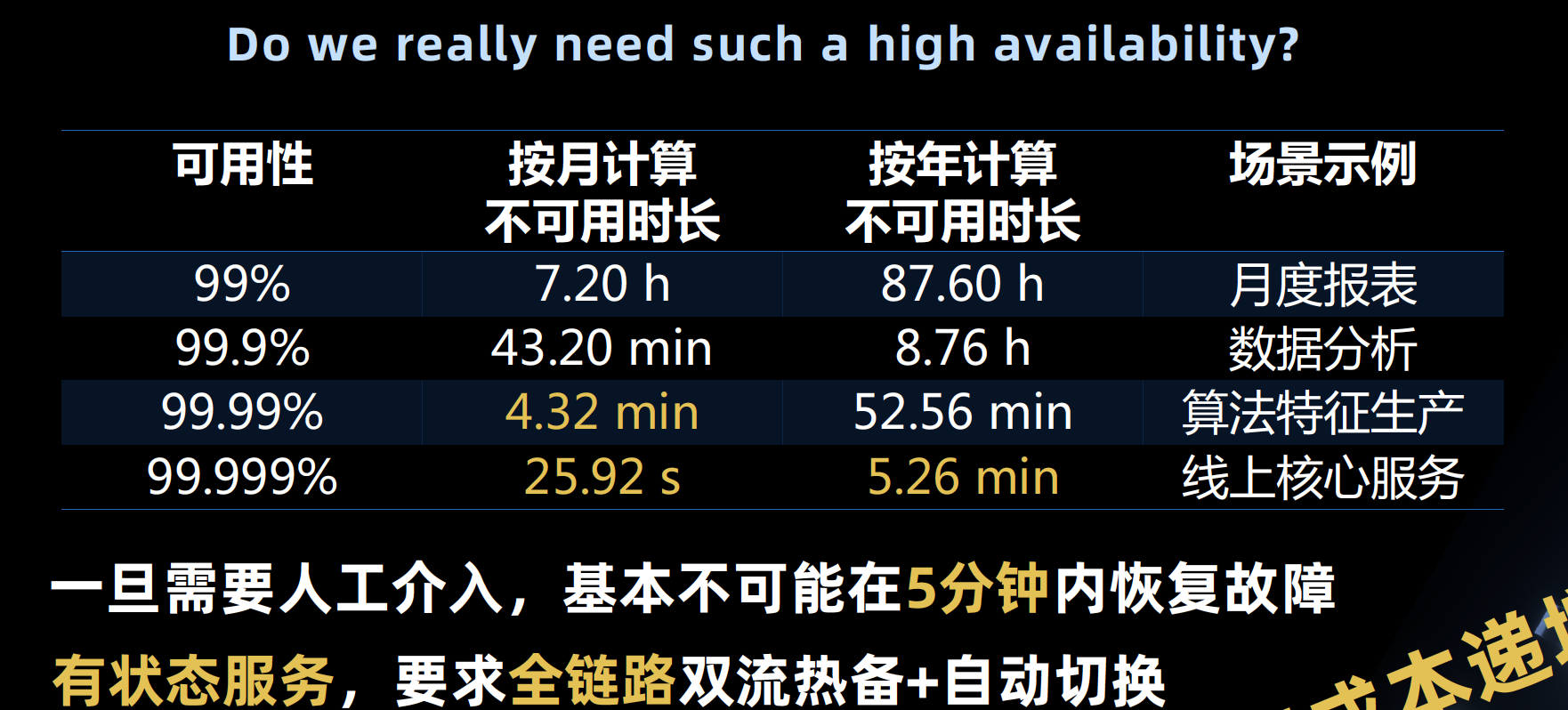
- 99%:直接拉起作业
- 99.9%:资源隔离
- 99.99%:热备
- 99.999%:自动切换
一旦需要人工介入,基本不可能在5分钟内恢复故障
有状态服务,要求全链路双流热备+自动切换
Flink SQL的功能扩展与深度优化
- 窗口功能扩展
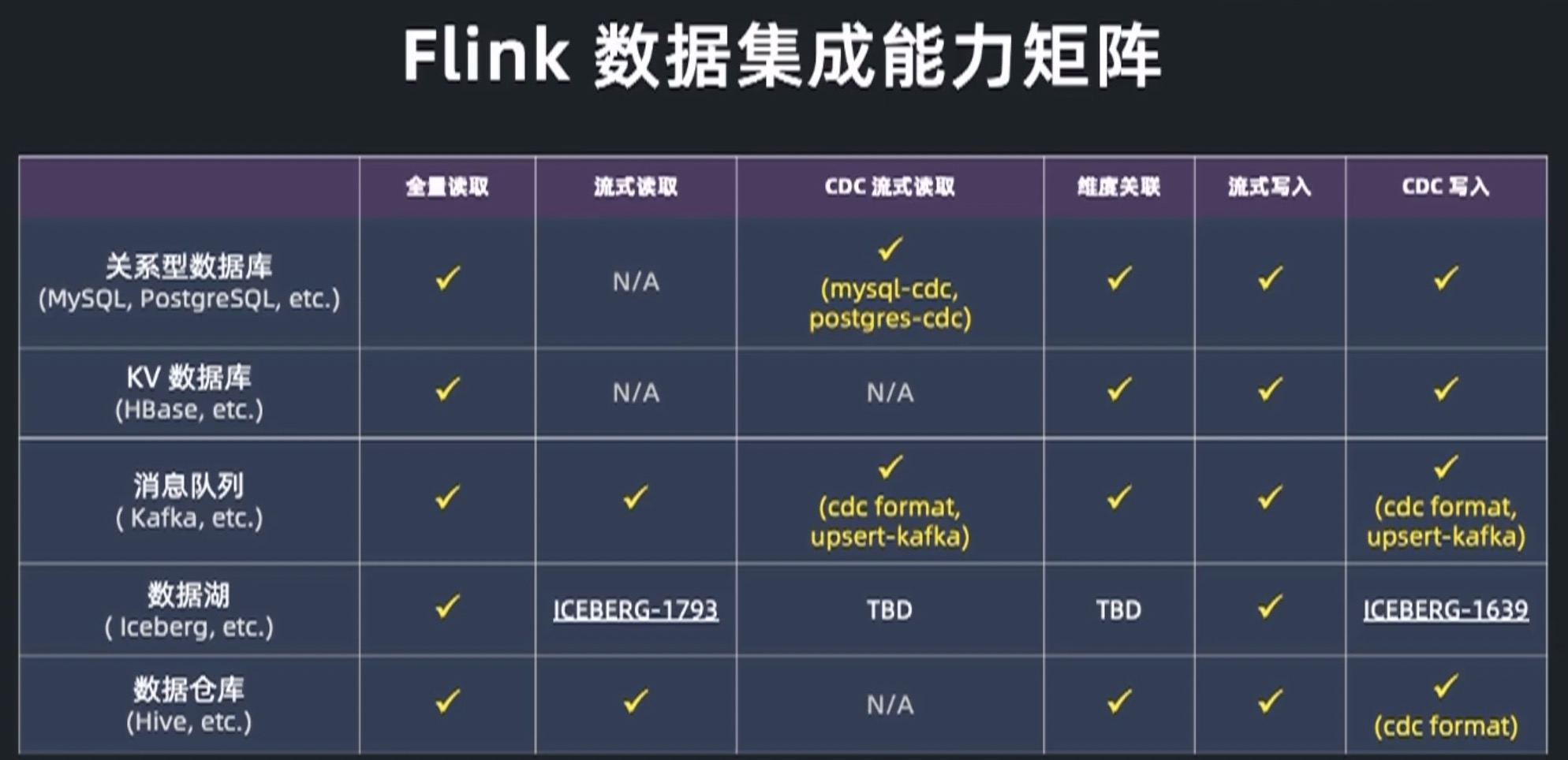
基于 Flink SQL 构建流批一体的 ETL 数据集成
- 1.12 toHive 小文件合并
- 关联 Hive 维表
eventTime维表 join

ULTRON — 360基于Flink的实时数仓平台
平台建设