原文地址:https://www.ververica.com/blog/end-to-end-exactly-once-processing-apache-flink-apache-kafka
2017年12月,Apache Flink 1.4.0 发布。此版本包含一个对于流处理来说的重大特性:TwoPhaseCommitSinkFunction,它利用二阶段提交协议使 Flink 程序实现端到端的精确一次处理,Flink-Kafka-Connector 已实现这个功能。 TwoPhaseCommitSinkFunction 提供了一个接口,并要求用户只实现少数方法来实现端到端的精确一次处理语义。
TwoPhaseCommitSinkFunction 的使用文档,请查看 to the relevant place in the Flink documentation。或者你可以直接查看 Kafka 0.11 producer,它实现了 TwoPhaseCommitSinkFunction 。
如果你想了解更多,本文将带你深入了解这个新特性在 Flink 中的实现原理
- Flink Checkpoints 在实现 Flink 程序精准一次处理的作用
- 展示 Flink 如何通过两阶段提交协议与 Source/Sink 交互,以提供端到端的精确一次保证
- 通过一个简单的示例,了解如何使用
TwoPhaseCommitSinkFunction实现一个精确一次处理的文件接收器
Apache Flink 中的精确一次处理语义
当我们在说“精确一次”,是说每个 event 对最终结果只影响一次。当机器/软件故障时,不会出现重复数据和丢数据。
Flink 很早就实现了精确一次处理语义,written in depth about Flink’s checkpointing,这是 Flink 提供一次语义的核心。Flink 文档中也提供该功能的全面概述。
Flink 中的 Checkpoint 是一致性的快照,包含以下内容:
- 应用程序的当前状态
- 输入流的 position
通过配置间隔,Flink 有规律的生成 Checkpoint 并持久化到存储系统(S3/HDFS)。将 Checkpoint 数据持久化到存储系统这个操作是异步的,这意味着 Flink 在 Checkpoint 过程中也可以继续处理 event。
当机器/软件故障导致重启时,Flink 会从最近一个完成的 Checkpoint 中恢复:在处理 event 前,从 Checkpoint 恢复状态并获取 Source position 重置输入流的消费位点。这意味着对于 Flink 计算结果来说就好像从未发生过故障一样。
在 Flink 1.4 之前,只在 Flink 内部保证精确处理一次语义,对于第三方数据源没有保证。但是 Flink 应用程序与各种各样的 Sink 一起运行,开发人员需要能够实现 end2end 的精确一次语义。
要提供端到端的精确一次语义,这些外部系统必须提供提交和回滚与 Flink Checkpoint 相协调的方法。
在分布式系统中协调提交和回滚的一种常见方法是两阶段提交协议。在下节我们一起讨论 Flink 的 TwoPhaseCommitSinkFunction 是如何利用二阶段提交协议实现端到端的精确一次语义。
Apache Flink 端到端精确一次处理语义
我们将介绍两阶段提交协议,以及它如何在从Kafka读写的示例中实现端到端的精确一次语义。Kafka 是流行的消息传递系统与 Flink 一起使用,Kafka 在最近的 0.11版本中增加了对事务的支持。文档介绍了 Flink 从Kafka 读取数据并写回 Kafka 这个过程要实现端到端精确一次处理的一些机制。
Flink 对端到端精确一次语义的支持并不局限于Kafka,您可以将其用于提供提交和回滚机制的任何 Source/Sink。例如 Pravega,Dell/EMC 开源的流式存储系统通过 Flink 提供的 TwoPhaseCommitSinkFunction 也可以实现端到端精确一次处理语义。
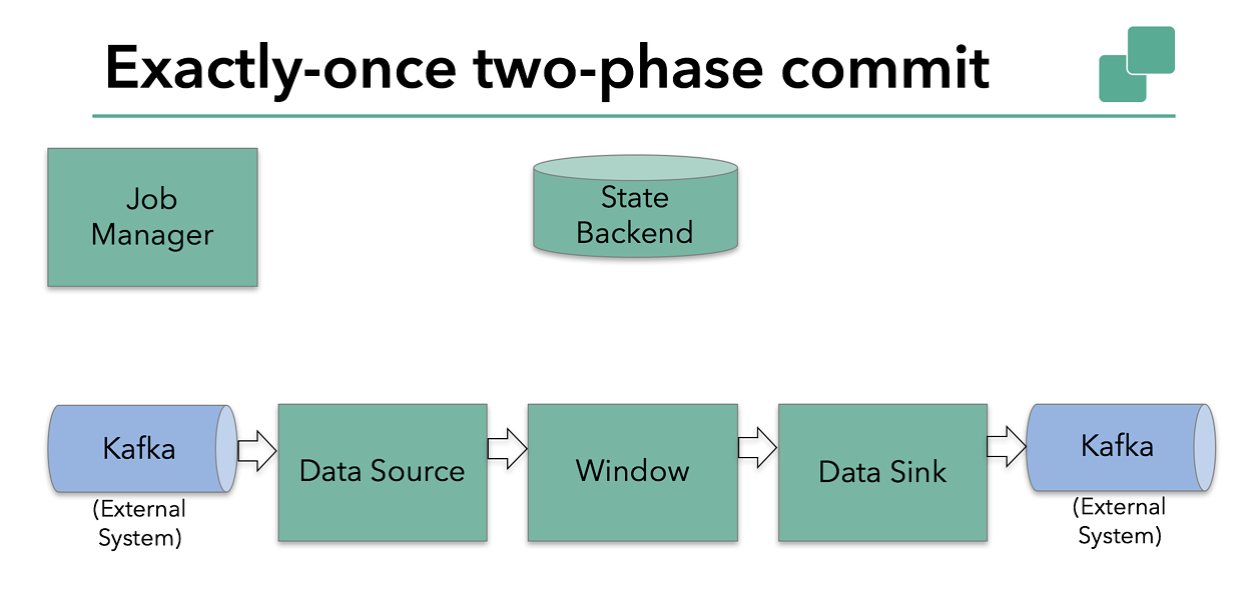
我们今天将讨论的示例Flink应用程序中
- 从 kafka 读取数据的 Source( KafkaConsumer)
- 窗口聚合操作
- 写数据都 kafka 的 Sink
要使 Sink 提供精确一次的保证,它必须将事务范围内的所有数据都写入 Kafka。两个 Checkpoint 之间的所有数据是一起提交,这样可以确保在发生故障时回滚。
然而在具有多个并发运行的 Sink 任务的分布式系统中,简单的提交或回滚是不够的。因为所有组件必须的提交/回滚都必须保持一致,以确保结果一致。Flink 使用两阶段提交协议以及其预提交阶段来解决这个问题。
Checkpoint 开始表示两阶段提交协议的“预提交”阶段可以启动。当一个 Checkpoint 启动时,Flink JobManager 向数据流注入一个 Barrier(它将数据流中的记录分为进入当前 Checkpoint 的集合和进入下一个 Checkpoint 的集合)。
Barrier 从前一个算子传递到下一个算子,当算子处理到 Barrier 时就会将当前算子状态坐快照并持久化到状态后端。
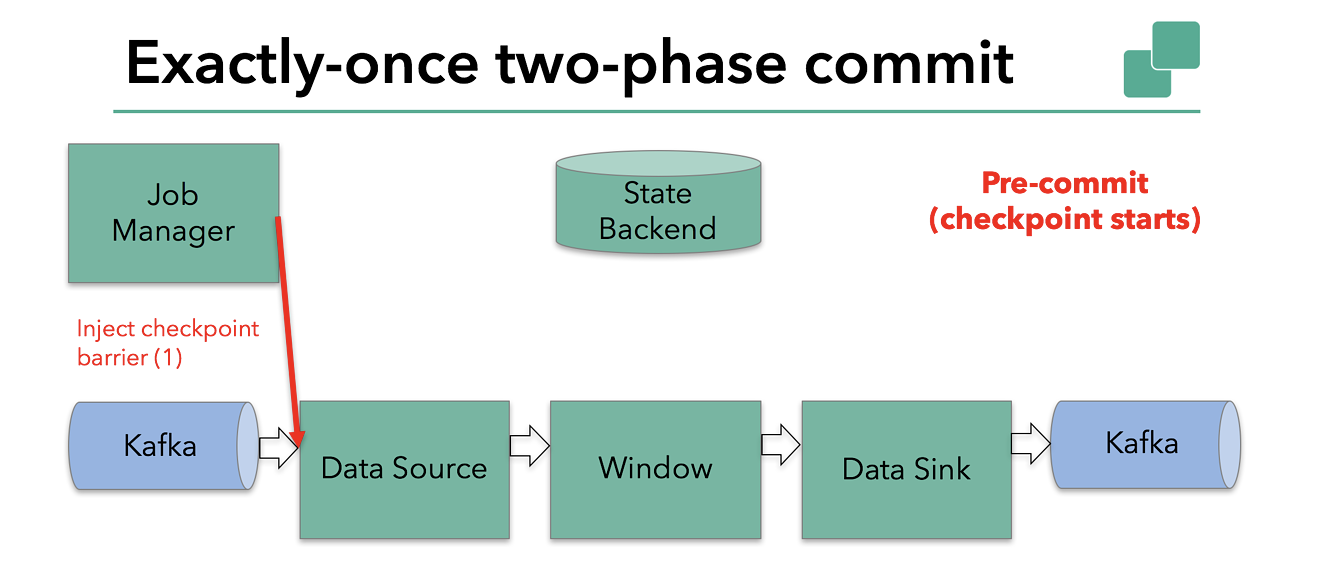
Source 处理到 Barrier 后,先传递给下一个算子,然后再将 Kafka offset保存,最后再处理下一个 event。
如果运算符只有内部状态,则此方法有效。内部状态是可以由 Flink 的状态存储和管理的:例如,第二个运算符窗口的聚合结果。当一个进程只有内部状态时,除了写入定义的状态外,在预提交不需要执行任何额外的操作。Flink 负责在检查点成功的情况下正确提交这些写操作,或者在失败的情况下中止这些写操作。
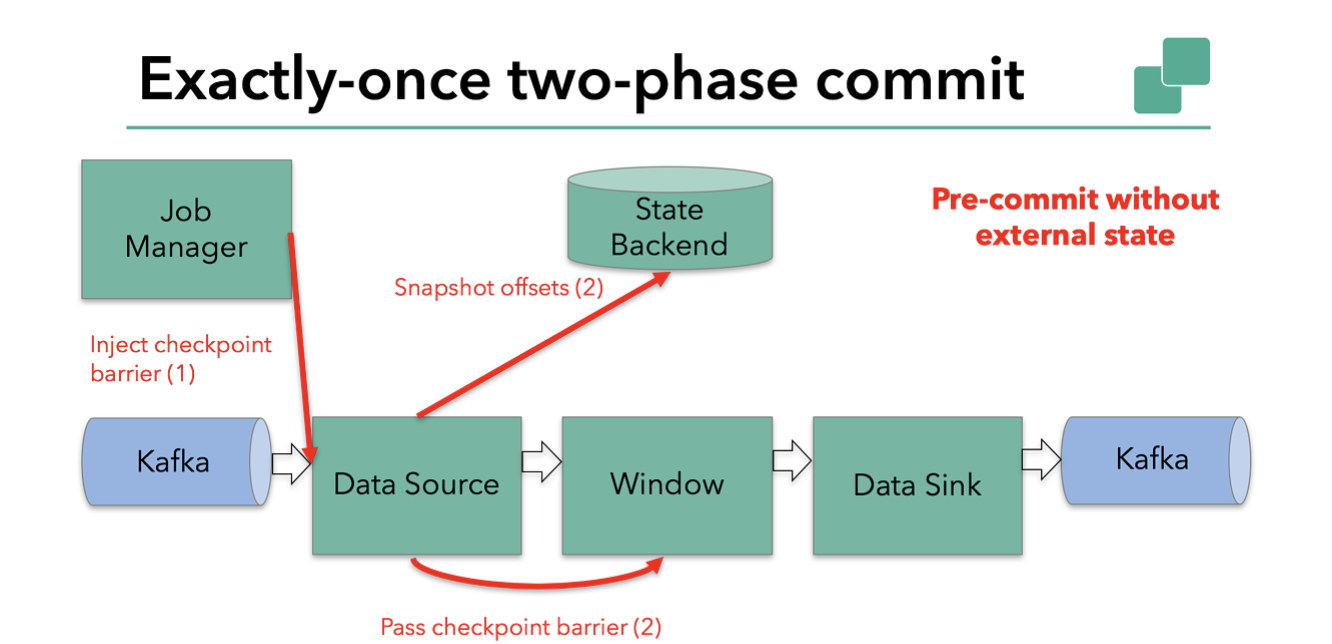
但是,当一个进程有外部状态时,这个状态的处理方式必须有所不同。外部状态通常以写入外部系统(Kafka)的形式出现。在这种情况下,为了提供精确的一次保证,外部系统为了与两阶段提交协议交互必须提供事务支持。
我们知道我们示例中的 Sink 具有这样的外部状态,因为它向 Kafka 写入数据。在这种情况下,在预提交阶段,除了将其状态写入状态后端之外,Sink 还必须预提交其外部事务。
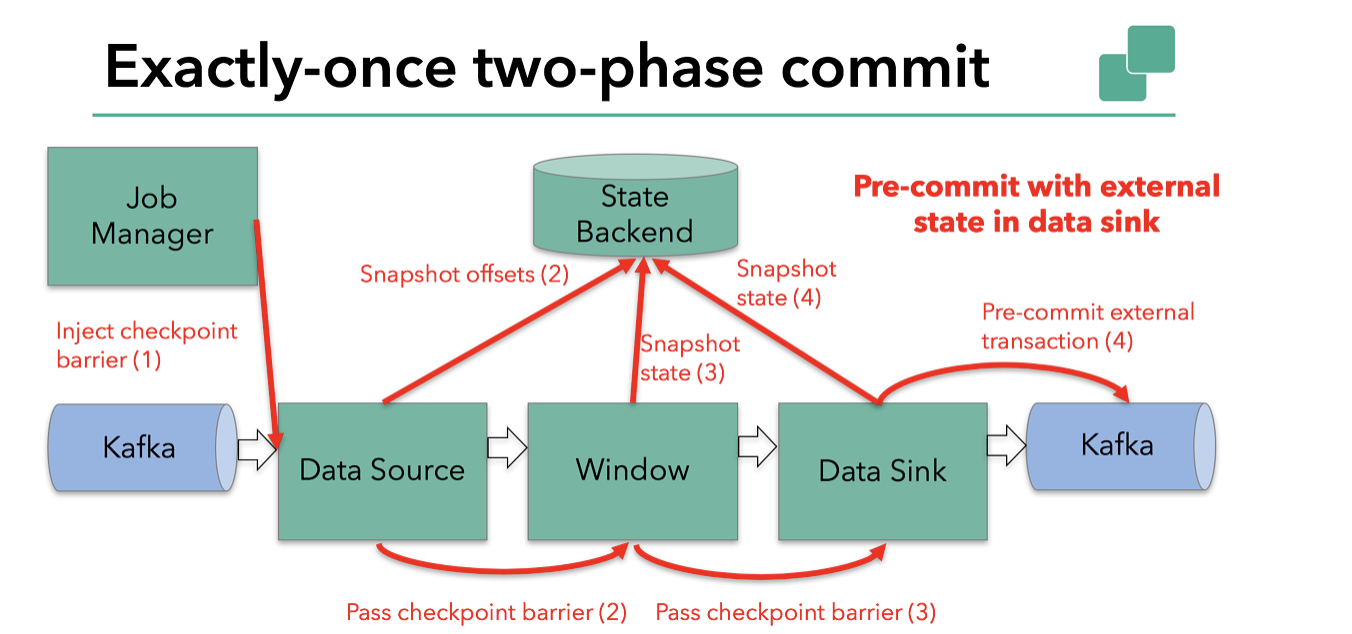
当 Barrier 通过所有操作符并且触发的快照回调成功完成时,预提交阶段结束。所有算子触发的状态快照都被视为该 Checkpoint 的一部分。Checkpoint 是整个应用程序状态的快照,包括预提交的外部状态。如果出现故障,我们可以回滚到上次成功完成快照的时间点。
下一步是通知所有算子 Checkpoint 已成功。这是两阶段提交协议的提交阶段,JobManager 为应用程序中的每个 算子 发出 checkpoint-completed 的回调。
Source 和窗口算子没有外部状态,因此在提交阶段,这些算子不必采取任何操作。不过 Sink 有外部状态,此时应该提交外部事务。

整个过程如下:
- 一旦所有算子完成预提交,它们就会发出一个提交
- 如果有一个预提交失败,那么所有其他的预提交都将被中止,我们将回滚到上一个成功完成的 Checkpoint
- 在成功的预提交之后,必须保证最终提交成功——Flink 和外部系统都需要这样保证。这个过程非常关键,因为如果提交最终没有成功,就会发生数据丢失。
- 如果提交失败(例如,由于间歇性网络问题),则整个 Flink 应用程序将失败,应用程序将根据用户的重新启动策略重新启动,并且有一次再次提交的机会(事务会保存在 state,重启后从state 恢复事务,但若这次还失败则会丢数据)。
因此,我们必须确保所有算子都同意 Checkpoint 的最终结果:所有算子都同意提交数据/放弃提交并回滚。
Flink 中实现两阶段提交
管理起来有点复杂,这就是为什么 Flink 将两阶段提交协议的公共逻辑提取到 TwoPhaseCommitSinkFunction 类中。
让我们基于文件的示例上讨论如何实现 TwoPhaseCommitSinkFunction。我们只需要实现四个函数就可以实现精确一次的文件 Sink:
beginTransaction:开启一个事务,我们在目标文件系统的临时目录中创建一个临时文件。随后,我们可以将数据写入该文件。preCommit:we flush the file, close it。我们还将为属于下一个 Checkpoint 的写入启动一个新事务。commit: 我们原子地将预提交的文件移动到实际的目标目录。请注意,这会增加输出数据可见性的延迟。abort: 删除临时文件
总所周知,如果有任何失败,Flink 会将应用程序的状态恢复到最新成功 Checkpoint。但在极端情况下会发生这么一种情况:在预提交之后提交事务时失败了。在这种情况下,Flink 将我们的算子恢复到已经预提交但尚未提交的状态。
我们必须在 Checkpoint 下保存有关预提交事务的足够信息,以便在重新启动后能够中止或提交事务。在我们的示例中,就是临时文件和目标目录的路径。
TwoPhaseCommitSinkFunction 考虑到这个场景,当从检查点恢复状态时,它总是会先尝试提交。此时需要我们以幂等的方式实现事务。一般来说问题不大。在我们的例子中,只会出现以下两种情况,无论什么情况下都是幂等(remove 文件是原子操作):
- 临时文件在临时目录下,还未移动到目标目录,此时执行事务提交(移动文件到目标目录)
- 临时文件不在临时目录下,已在目标目录,此时执行事务提交(无临时文件可移动)
总结
非常感谢你耐心阅读到现在。下面是我们讨论的一些要点
- Flink 的 Checkpoint 机制是保证实现
TwoPhaseCommitSinkFunction和提供端到端精确一次的基础 - 这种方法的一个优点是 Flink 不像其他系统那样在传输中物化数据:不需要像大多数批处理那样将计算的每个阶段都写入磁盘
- Flink 的
TwoPhaseCommitSinkFunction提取了二阶段协议的公告逻辑,并为 Flink 与外部数据源交互提供端到端的精确一次保障。 - 从 Flink1.4.0 开始,Pravega 和 Kafka 0.11 Sink 都提供端到端精确一次语义。Kafka 在 0.11 提供了事务,这是 Flink-Kafka-Conector 实现端到端精确一次的基础。
- Kafka 0.11 producer 是在
TwoPhaseCommitSinkFunction基础上实现的,相比于至少一次语义开销也不算太大。
我们对这个新功能的实现感到非常兴奋,也非常期待更多的 Sink 支持 TwoPhaseCommitSinkFunction 。
译者
文章翻译到此结束。
本文提及的 TwoPhaseCommitSinkFunction 其实是 Flink 实现分布式事务的实现方式。但实现一个分布式事务,在现实世界往往更为复杂(很多问题本文未提及) 会导致丢数据。介绍一篇大神的笔记,里面详细探讨各种各样的问题