批处理系统
使用 UNIX工具进行批处理
unix 命令链(awk, s时, grep, sort , uniq和xargs的组合) ,可以在几分钟内完成许多数据分析 任务,并且表现令人十分满意。UNIX工具的最大局限在于它们只能在一台机器上运行。
MapReduce与分布式文件系统
MapReduce 有点像分布在数千台机器上的UNIX工具。
MapReduce 是一个编程框架,可以使用它编写代码来处理HDFS等分布式文件系统中 的大型数据集。
MapReduce 与 UNIX 命令管道的主要区别在于它可以跨多台机器并行执行计算,其不必编写代码来指示如何井行化(框架内部处理)。
对比 Hadoop与分布式数据库
- 存储多样性:数据库要求严格的Schema,HDFS 可以存储任何格式
- 处理模型的多样性:Hadoop计算/存储分开,不仅仅只是用SQL;数据库特定需求进行调整和优化,因此整个系统可以在其设计的查询类型上实现非常好的性能。
- 针对频繁故障的设计:如何处理故障和 如何使用内存和磁盘
- MPP 数据库某一个节点失败则整个任务失败,需要重新提交;计算过程的数据尽可能在内存,避免读取磁盘的成本
- Hadoop 中间数据写入磁盘,这样在某个subTask失败不需要重新跑整个任务;数据集太大内存也放不下。处理大量的数据井运行很长时间的作业
超越MapReduce
数据流
把整个工作流作为一个作业来处理,而不是把它分解成独立的子作业。数据流对MapR巳duce的改进是,不需要自己将所有中间状态写入文件系统。
为了实现重新计算,框架必须追踪给定数据是如何计算的,使用了哪个输入分区, 以及应用了哪个运算符。 Spark 使用弹性分布式数据集( Resilient Distributed Dataset, RDD) 抽象来追踪数据的祖先,而Flink 运算符状态建立检查点, 从而允许将执行过程中遇到故障的运算符恢复运行。
流处理系统
批处理的问题是,输入的更改只会在一天之后的输出中反映出来,这对于许多没有耐心的用户来说太慢了。
发送事件流
事件由生产者 (也称为发布者或发送者)生成一次,然后可能由多个消费者(订阅者或 接收者)处理。
消息代理与数据库对比
- 数据库通常会保留数据直到被明确要求删除,而大多数悄息代理在消息成功传递 给悄费者时就自动删除消息。这样的消息代理不适合长期的数据存储。
- 由于消息代理很快删除了消息, 多数消息系统会假定当前工作集相当小,即队列很短。如果因为消费者速度很慢,而使代理需要缓存很多消息的话(如果内存无法容纳所有的消息,可能会将部分消息保存到磁盘),那么每个消息就需要更快的时间来处理,整个吞吐量 可能会因此降低
- 数据库通常支持二级索引和各种搜索数据的方式 ,而消息代理通常支持某种方式订阅匹配特定模式的主题。这些机制虽然是不同 的,但本质上都是让客户端可以选择它们想要了解的部分数据 。
- 查 询 数据时 ,结果通常基于数据 的时间点快 照。如果另一个客户端随后向数据 库写入更改查询结果的内容,那么第一个客户端不会发现之前的结果已经过期 (除非它重复查询或轮询更改)。相比之下,消息代理不支持任意的查询,但是当数据发生变化时 (即新消 息可用时),它们会通知客户端。
批处理过程的一个关键特征是,可以反复地运行它们,尝试处理步骤,而且没有损坏输入的风险(因为输入是只读的)。
流处理也可以,但流处理的数据源一般是消息代理,而消息代理的数据 TTL 有限。
数据库与流
没有 一 个系统能够满足所有的数据存储、查询和处理需求。
变更数据捕获
异构存储要保持一致要双写,而双写会带来很多问题:
- 一个成功,一个失败
- 并发会相互覆盖,一个值是A,另一个值时B
保证一致需要做原子提交(两阶段提交)。为何会出现这些问题,在于异构存储是每个存储都有主节点,有两个主节点肯定是有并发冲突问题。那如何把两个主节点变成一个主节点变成解决事情的关键。
变更数据捕获(Change Data Capture, CDC)
只写DB,另一个存储系统使用CDC将数据写到自己系统上。这样相当于只有一个主节点,另一个储存变成DB的从节点了。之前的问题解决了,但主从复制的问题一样会发生。
Apache Kafka支持此日志压缩功能,这样消息代理可用于永久存储, 而不仅仅是用于临时消息传递。
事务日志记录了对数据库所做的所有更改。 高速追加是更改日志的唯一方位。 从这个角度来看,数据库的内容保存了日志中最新记录值的缓存。日志是事实。数据库是日志子集的缓存。该缓存子集恰好是来自日志的每个记录和索引值的最新值。
流处理
适合流处理的场景
- 复杂事件处理
- 流分析:统计分析
- 维护物化视图
- 在流上搜索:类似 CEP
- 消息传递和 RPC
流的时间问题
事件时间的窗口问题,flink watermark
流式 join
- 窗口之间 join
- 流和维表 join
- 双流 join
流处理的容错
- 微批处理和校验点:flink barrier
- 重新审视原子提交:提供端到端的恰好一次
- 幕等性:可以多次执行的操作,并且它与只执行 一 次操作具有相同的效果;至少一次语义
- 故障后重建状态:flink checkpoint;从输入流开始重建(数据重刷)
数据系统的未来
数据集成
数据流异步复制,派生出新的数据模式(flink 消费binlog做ETL)
大多数共识算怯是针对单节点吞吐量足以处理整个 事件流而设计的,并且这些算桂不提供支持多节点共享事件排序的机制。设计突破单 节点吞吐量甚至在广域地理环境分布的共识算能仍然是 一 个有待研究的开放性问题。
分拆数据库
操作系统和数据库都可以存储数据,文件和数据模型(表)。操作系统提供低层次的硬件抽象,数据库提供高层次的抽象(SQL实现强大的功能)。
数据库中创建索引时,需要从一致性快照从头开始构建;这有点像流处理系统中初始变更数据捕获(补数需要重新推数据)。
整个组织的数据流开始变得像一个巨大的数据库:ETL 数据加工并存储的过程就像数据库子系统中新建索引或物化视图。
整个大数据看作是一个数据库的话,是由不同的存储和处理工具最终会组成一个紧密结合的系统。
- 统一查询:类似 Presto 这种统一 SQL 查询引擎,华为的openLooKeng 就是在 Presto 上包装成服务:不同数据源、跨区查询和 Join
- 分离数据库(统一写入):没有一个数据库能满足所有需求,肯定是选用不同的数据库,这涉及到一份数据写多个存储或数据再加工
有序的事件日志结合幕等的事件处理是一种更简化的抽象,因此在异构系统中实现时会更可行(流在异构间流转);可以理解为消息队列解耦。
通过应用层代码来组合多个专门的存储与处理系统并实现分离式数据库的方陆也被称为“数据库由内向外”方法。
围绕数据流来构建应用程序是一个非常有前途的方向。
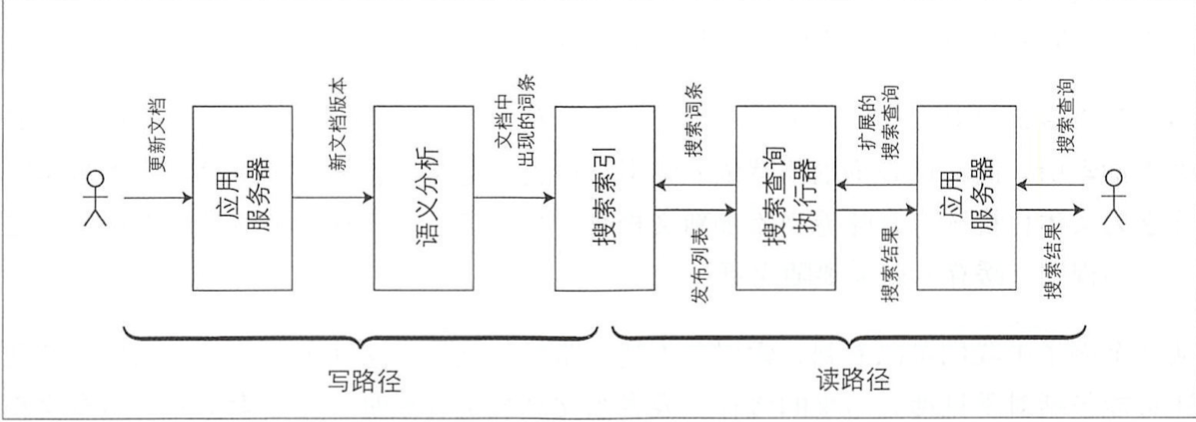
写路径和读路径涵盖了数据的整个过程,从数据收集到数据使用。写路径可以看作是预计算的一部分,即一旦数据进入即刻完成,无论是否有人要求访问它。而过程中的读路径则只有当明确有人要求访问时才会发生。如果你熟悉函数式编程语言,可能会注意到写路径类似于尽早求值,读路径类似于惰性求值。某种程度上,它是写入时需完 成的工作量和读取时需完成的工作量之间的一种平衡。
端到端的正确性
基于数据流架构来思考、探索正确性的若干方法。
即使应用程序所使用的数据系统提供了比较强的安全属性(如可串行化事务),也并不意味着应用程序就一定没有数据丢失或损坏,应 用程序本身也需要采取端到端的措施,例如消除重复。
做正确的事情
审视了构建数据密集型应用系统在道德层面的 一些问题
注:<分拆数据库>和<端到端的正确性>需要细细品味。