Source 变化有点大,之前看过,现在重新记录下。
FLIP-27: Refactor Source Interface: https://cwiki.apache.org/confluence/display/FLINK/FLIP-27%3A+Refactor+Source+Interface
流程
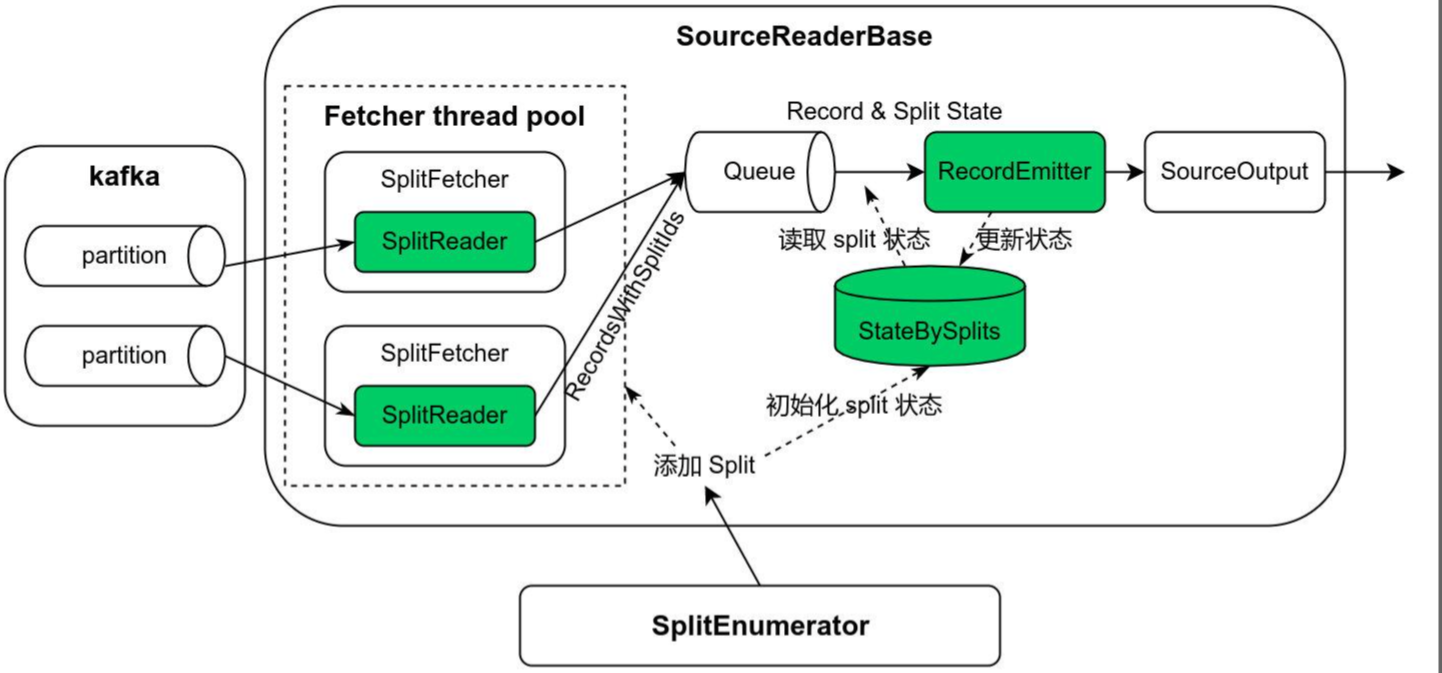
SourceEnumerator.start- 获取Topic 分区信息,过滤出新增的分区;并将新增分区信息通过函数
context.assignSplits发送到Source - 主要代码 getSubscribedTopicPartitions、checkPartitionChanges
- 包含新分区发现、分区分配问题(多并行度下分区如何分配)
- 获取Topic 分区信息,过滤出新增的分区;并将新增分区信息通过函数
SourceRead.addSplits:有两个地方会触发此调用:状态恢复(下文再提)、新分区发现(context.assignSplits)- SourceRead 接收到一个新分区信息,调用
FetcherManager.addSplits
- SourceRead 接收到一个新分区信息,调用
FetcherManager.addSplits:添加一个AddSplitsTask任务- 将splits 信息封装成 AddSplitsTask,放到内部队列(BlockingDeque
taskQueue) - FetcherManager 内部
splitFetcher从队列获取task 并执行(这里单指AddSplitsTask) - AddSplitsTask:通知SplitReader 有新的 split(分区) =>
splitReader.handleSplitsChanges
- 将splits 信息封装成 AddSplitsTask,放到内部队列(BlockingDeque
SplitReader.handleSplitsChanges- cousumer(Sourec 第三方对应的Client) 添加新分区信息
fetch 函数执行正常的消费(获取数据)- 由
splitFetcher调用FetchTask.run(若没有AddSplitsTask,则执行FetchTask) - ->
splitReader.fetch() - 消费后放入
elementsQueue,等待后续拉取
- 由
RecordEmitter.emitRecord:数据输出到下游并更新 offsetSourceOperator#emitNext- ->
SourceReaderBase#pollNext从elementsQueue获取数据 record - emitRecord(record)
除了SourceEnumerator 是在JobManager 运行,其他都是TaskManager 上跑。上面流程总结:JM 给每个TM 分配要消费的分区信息,TM 消费对应分区拉取的数据放在elementsQueue,SourceOperator 触发从elementsQueue 获取数据发往下游。
SourceEnumerator 负责发现需要读取的 kafka partition,SourceReader 则负责具体 partition 数据的读取。
Checkpoint
Enumerator
保存分区信息
// org.apache.flink.connector.kafka.source.enumerator.KafkaSourceEnumerator
private final Set<TopicPartition> assignedPartitions;
public KafkaSourceEnumState snapshotState(long checkpointId) throws Exception {
return new KafkaSourceEnumState(assignedPartitions);
}
SourceReader
保存消费的分区信息和offset。
// org.apache.flink.streaming.api.operators.SourceOperator#snapshotState
public void snapshotState(StateSnapshotContext context) throws Exception {
long checkpointId = context.getCheckpointId();
LOG.debug("Taking a snapshot for checkpoint {}", checkpointId);
readerState.update(sourceReader.snapshotState(checkpointId));
}
// org.apache.flink.connector.base.source.reader.SourceReaderBase
public List<SplitT> snapshotState(long checkpointId) {
List<SplitT> splits = new ArrayList<>();
splitStates.forEach((id, context) -> splits.add(toSplitType(id, context.state)));
return splits;
}
public void addSplits(List<SplitT> splits) {
LOG.info("Adding split(s) to reader: {}", splits);
// Initialize the state for each split.
splits.forEach(
s ->
splitStates.put(
s.splitId(), new SplitContext<>(s.splitId(), initializedState(s))));
// Hand over the splits to the split fetcher to start fetch.
splitFetcherManager.addSplits(splits);
}
currentSplitContext = splitStates.get(nextSplitId);
currentSplitOutput = currentSplitContext.getOrCreateSplitOutput(output);
recordEmitter.emitRecord(record, currentSplitOutput, currentSplitContext.state);
public void emitRecord(
ConsumerRecord<byte[], byte[]> consumerRecord,
SourceOutput<T> output,
KafkaPartitionSplitState splitState)
throws Exception {
try {
sourceOutputWrapper.setSourceOutput(output);
sourceOutputWrapper.setTimestamp(consumerRecord.timestamp());
deserializationSchema.deserialize(consumerRecord, sourceOutputWrapper);
splitState.setCurrentOffset(consumerRecord.offset() + 1);
} catch (Exception e) {
throw new IOException("Failed to deserialize consumer record due to", e);
}
}
- addSplits 增加splitStates 分区信息
- emitRecord 计数 splitStates.offset
状态恢复
Enumerator
// org.apache.flink.connector.kafka.source.KafkaSource
public SplitEnumerator<KafkaPartitionSplit, KafkaSourceEnumState> restoreEnumerator(
SplitEnumeratorContext<KafkaPartitionSplit> enumContext,
KafkaSourceEnumState checkpoint)
throws IOException {
return new KafkaSourceEnumerator(
subscriber,
startingOffsetsInitializer,
stoppingOffsetsInitializer,
props,
enumContext,
boundedness,
checkpoint.assignedPartitions());
}
如果从checkpoint 恢复会调用此函数来创建 Enumerator ,自带 assignedPartitions
SourceReader
// org.apache.flink.streaming.api.operators.SourceOperator
public void initializeState(StateInitializationContext context) throws Exception {
super.initializeState(context);
final ListState<byte[]> rawState =
context.getOperatorStateStore().getListState(SPLITS_STATE_DESC);
readerState = new SimpleVersionedListState<>(rawState, splitSerializer);
}
public void open() throws Exception {
...
// restore the state if necessary.
final List<SplitT> splits = CollectionUtil.iterableToList(readerState.get());
if (!splits.isEmpty()) {
sourceReader.addSplits(splits);
}
...
}
addSplits 会为 Reader 增加新的分区以及offset
- 新程序运行时是没有状态的,那么 SourceEnumerator 会将所有分区信息(offset 采用Connector 参数)发送给SourceReader,SourceReader 按分区消费
- 程序带状态重启,若没有新增分区,那么SourceEnumerator 不会发生任何信息;SourceOperator 会将状态里的分区信息发送给 SourceReader
- 程序带状态重启,有新增分区,那么SourceEnumerator 只会发送新增分区给SourceReader;SourceOperator 将状态里的分区信息发送给 SourceReader