在抽取完物理 Plan 以后,我们最后还会进行一个 Physical Rule Rewrite 阶段,这个阶段和 Logical Rule Rewrite 阶段相似,只是一些启发式规则的优化。之所以将这些规则放到最后,原因有两个方面:
- 物理阶段的优化,大多是局部性优化,原则上并不会影响分布式Plan的选择;
- 在前一个前提下,放在物理阶段优化,可以避免 Memo Optimize 阶段中搜索空间的膨胀,也可以减少一些冗余的code。
// com.starrocks.sql.optimizer.Optimizer#optimizeByCost
// result => 最优Physical plan
OptExpression finalPlan = physicalRuleRewrite(rootTaskContext, result);
现有Physical Rule Rewrite
- 聚合模型检查是否需要打开Pre-Aggregation开关
- Top-N 重写
- 三阶段/四阶段聚合调度优化
- Prune join shuffle columns
- 低基数字典优化
- 表达式复用优化
- Predicate 重排
// com.starrocks.sql.optimizer.Optimizer#physicalRuleRewrite
private OptExpression physicalRuleRewrite(TaskContext rootTaskContext, OptExpression result) {
Preconditions.checkState(result.getOp().isPhysical());
int planCount = result.getPlanCount();
// Since there may be many different plans in the logic phase, it's possible
// that this switch can't turned on after logical optimization, so we only determine
// whether the PreAggregate can be turned on in the final
result = new PreAggregateTurnOnRule().rewrite(result, rootTaskContext);
// Rewrite Exchange on top of Sort to Final Sort
result = new ExchangeSortToMergeRule().rewrite(result, rootTaskContext);
result = new PruneAggregateNodeRule().rewrite(result, rootTaskContext);
result = new PruneShuffleColumnRule().rewrite(result, rootTaskContext);
result = new UseSortAggregateRule().rewrite(result, rootTaskContext);
result = new AddDecodeNodeForDictStringRule().rewrite(result, rootTaskContext);
// This rule should be last
result = new ScalarOperatorsReuseRule().rewrite(result, rootTaskContext);
// Reorder predicates
result = new PredicateReorderRule(rootTaskContext.getOptimizerContext().getSessionVariable()).rewrite(result,
rootTaskContext);
result.setPlanCount(planCount);
return result;
}
ExchangeSortToMergeRule
// com.starrocks.sql.optimizer.rule.tree.ExchangeSortToMergeRule#visitPhysicalDistribution
public OptExpression visitPhysicalDistribution(OptExpression optExpr, Void context) {
if (optExpr.arity() == 1 && optExpr.inputAt(0).getOp() instanceof PhysicalTopNOperator) {
PhysicalTopNOperator topN = (PhysicalTopNOperator) optExpr.inputAt(0).getOp();
if (topN.getSortPhase().isFinal() && !topN.isSplit() && topN.getLimit() == Operator.DEFAULT_LIMIT) {
OptExpression child = OptExpression.create(new PhysicalTopNOperator(
topN.getOrderSpec(), topN.getLimit(), topN.getOffset(), topN.getPartitionByColumns(),
topN.getPartitionLimit(), SortPhase.PARTIAL, topN.getTopNType(), false, false, null, null
), optExpr.inputAt(0).getInputs());
child.setLogicalProperty(optExpr.inputAt(0).getLogicalProperty());
child.setStatistics(optExpr.getStatistics());
// 多增加一层shuffle
OptExpression newOpt = OptExpression.create(new PhysicalTopNOperator(
topN.getOrderSpec(), topN.getLimit(), topN.getOffset(), topN.getPartitionByColumns(),
topN.getPartitionLimit(), SortPhase.FINAL, topN.getTopNType(), true, false, null,
topN.getProjection()),
Lists.newArrayList(child));
newOpt.setLogicalProperty(optExpr.getLogicalProperty());
newOpt.setStatistics(optExpr.getStatistics());
return visit(newOpt, null);
} else {
return visit(optExpr, null);
}
}
return visit(optExpr, null);
}
多了一层shuffle,简单理解为两阶段聚合操作(PARTIAL 一次、FINAL一次)
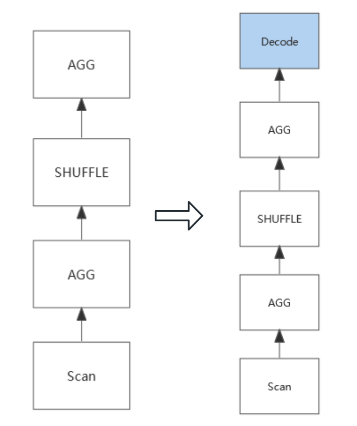
AddDecodeNodeForDictStringRule
低基数优化(原理介绍看参考资料):将字符串存储为数字,计算过程可以加速处理;但最后展示的时候需要数字还原为字符串。
// com.starrocks.sql.optimizer.rule.tree.AddDecodeNodeForDictStringRule.DecodeVisitor#visit
public OptExpression visit(OptExpression optExpression, DecodeContext context) {
visitProjectionBefore(optExpression, context);
for (int i = 0; i < optExpression.arity(); ++i) {
context.hasEncoded = false;
OptExpression childExpr = optExpression.inputAt(i);
// if needApplyStringDict, context.hasEncoded=true
visitProjectionBefore(childExpr, context);
OptExpression newChildExpr = childExpr.getOp().accept(this, childExpr, context);
if (context.hasEncoded) {
insertDecodeExpr(optExpression, Collections.singletonList(newChildExpr), i, context);
} else {
optExpression.setChild(i, newChildExpr);
}
}
return visitProjectionAfter(optExpression, context);
}
public OptExpression visitProjectionAfter(OptExpression optExpression, DecodeContext context) {
if (context.hasEncoded && optExpression.getOp().getProjection() != null) {
Projection projection = optExpression.getOp().getProjection();
Set<Integer> stringColumnIds = context.stringColumnIdToDictColumnIds.keySet();
if (projectionNeedDecode(context, projection)) {
// child has dict columns
// 新生成DecodeOExpr
OptExpression decodeExp = generateDecodeOExpr(context, Collections.singletonList(optExpression));
// 将原先OprExp Projection 操作移到 PhysicalDecodeOperator
decodeExp.getOp().setProjection(optExpression.getOp().getProjection());
optExpression.getOp().setProjection(null);
return decodeExp;
} else if (projection.couldApplyStringDict(stringColumnIds)) {
Projection newProjection = rewriteProjectOperator(projection, context);
optExpression.getOp().setProjection(newProjection);
optExpression.setLogicalProperty(rewriteLogicProperty(optExpression.getLogicalProperty(),
new ColumnRefSet(newProjection.getOutputColumns())));
return optExpression;
} else {
context.clear();
}
}
return optExpression;
}
private static OptExpression generateDecodeOExpr(DecodeContext context, List<OptExpression> childExpr) {
Map<Integer, Integer> dictToStrings = Maps.newHashMap();
for (Integer id : context.stringColumnIdToDictColumnIds.keySet()) {
int dictId = context.stringColumnIdToDictColumnIds.get(id);
dictToStrings.put(dictId, id);
}
// 构建新的PhysicalDecodeOperator,原先OptExp 当输入
PhysicalDecodeOperator decodeOperator = new PhysicalDecodeOperator(ImmutableMap.copyOf(dictToStrings),
Maps.newHashMap(context.stringFunctions));
OptExpression result = OptExpression.create(decodeOperator, childExpr);
result.setStatistics(childExpr.get(0).getStatistics());
LogicalProperty decodeProperty = new LogicalProperty(childExpr.get(0).getLogicalProperty());
result.setLogicalProperty(DecodeVisitor.rewriteLogicProperty(decodeProperty, dictToStrings));
// hasEncoded = false;
context.clear();
return result;
}
效果如下