Site: https://15445.courses.cs.cmu.edu/fall2022/project1/
Pdf: https://15445.courses.cs.cmu.edu/fall2022/slides/06-bufferpool.pdf
实现一个buffer pool 存放部分DB 数据,加快DB 数据读取。
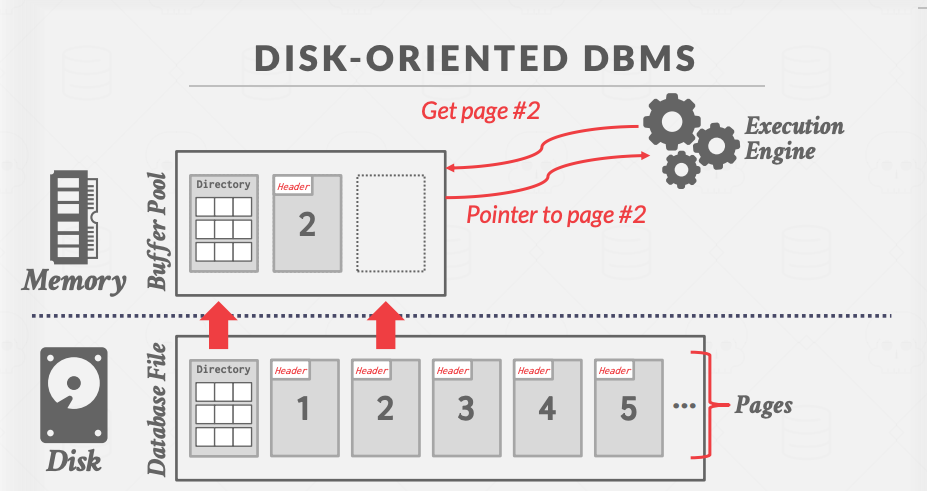
要实现buffer pool 需要两个数据结构:可扩展Hash 表、LRU-K替换策略
- 可扩展Hash 表:存放DB page 数据在内存中的位置 frame_id => <page_id, frame_id>
- buffer pool 就是内存中开辟连续的大空间(
page 数组),分割成page 块大小 - 下图 page_table 所示,O(1) 复杂度指 page_id 取到内存地址frame_id
- buffer pool 就是内存中开辟连续的大空间(

- LRU-K替换策略: buffer pool 空间 « DB数据空间,需要置换策略
- 需要用到的page 载入buffer pool,不需要用到的page 驱逐出buffer pool
可扩展Hash 表
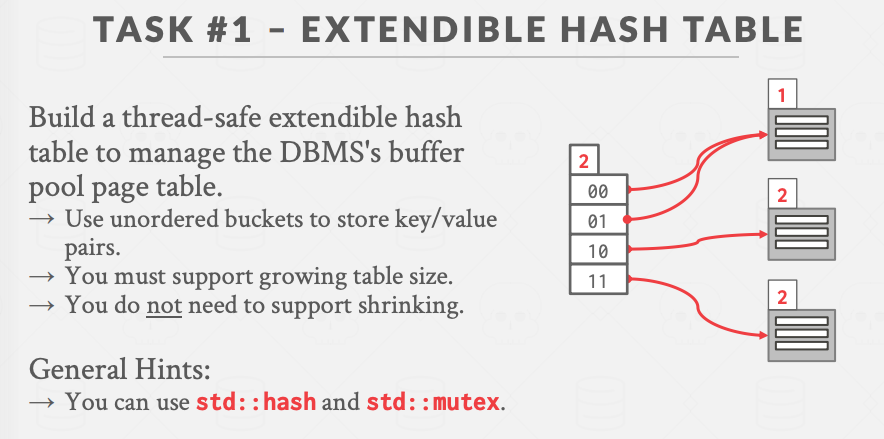
与平常所用的HashTable 类似:数组(dir_) + 链表(bucket),不同之处在于扩容时的数据重分布:不会全部数据都重分布,而是只会对引发重分布的bucket 数据进行重分布。详细资料看extendible-hashing-dynamic-approach-to-dbms
涉及到的数据结构如下:
// ExtendibleHashTable.class
int global_depth_; // The global depth of the directory 类似bucket.depth_
size_t bucket_size_; // The size of a bucket 设定bucket 长度
int num_buckets_; // The number of buckets in the hash table
mutable std::mutex latch_;
std::vector<std::shared_ptr<Bucket>> dir_; // The directory of the hash table
// ExtendibleHashTable::Bucket.class
size_t size_;
int depth_;
std::list<std::pair<K, V>> list_;
Bucket
Bucket 的操作很简单,就是对链表的增删查操作。需要注意的下面两个属性
size_:统一设置链表的长度,插入时如果大于size 则会引发重分布操作(只是当前链表里的数据重分布)depth_: 跟hash(key) 后要与操作的mask_code 有关,具体看看IndexOf函数体会下,决定 key存放到哪个bucket
ExtendibleHashTable
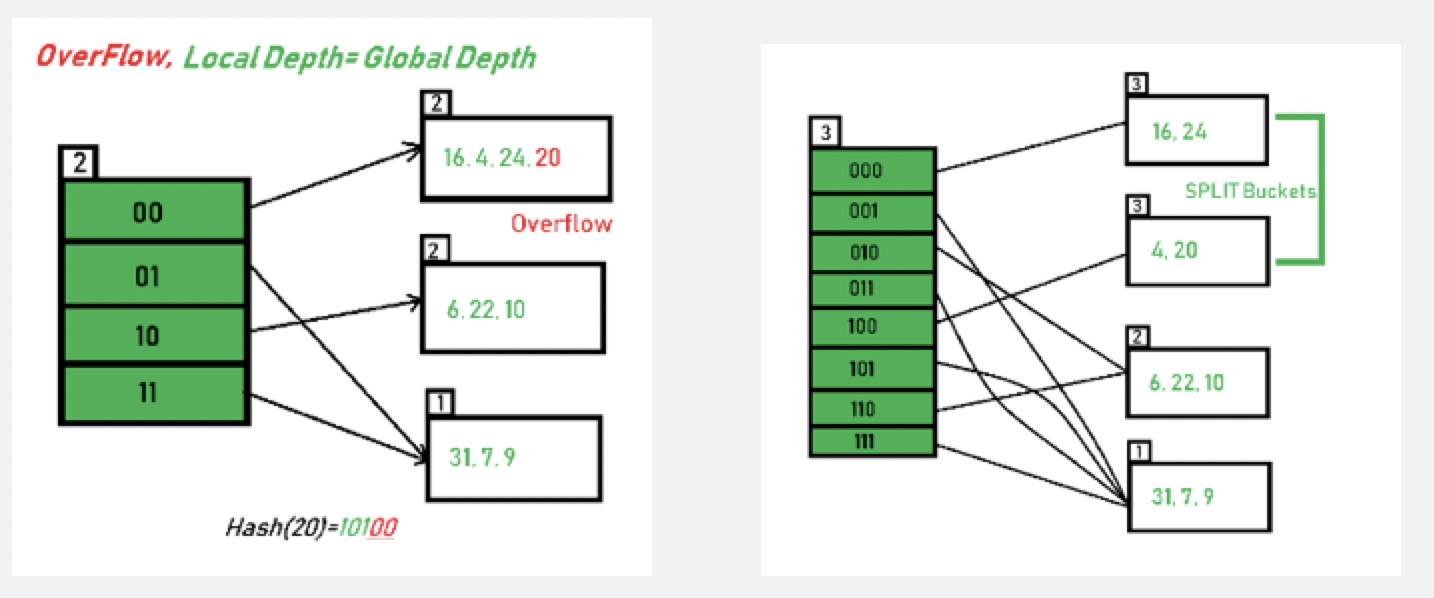
在ExtendibleHashTable 查/删都非常简单,IndexOf 得到index,dir[index] 可得具体的Bucket,查/删操作都交由Bucket 即可。插入操作相对复杂,Bucket 数据重分布不麻烦,但dir 所指向的bucket 调整就麻烦一点。重分布有两种情况
- dir 扩容: depth_ = global_depth_
- 这种情况比较好处理,因为需要调整的dir(指向的bucket) 就两个:当前index、index + 扩容前dir.size
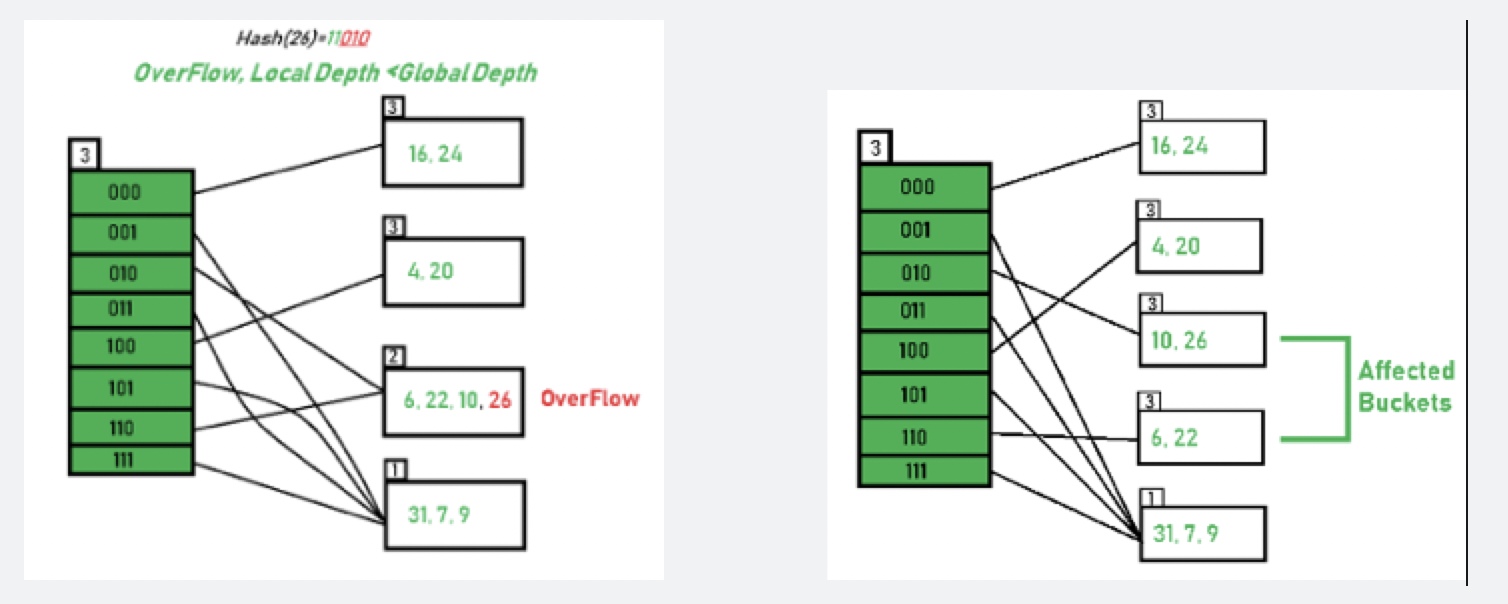
- dir 无需扩容: depth_ < global_depth_
- 麻烦在于要调整的dir 个数是不固定的;下图案例是两个,但若是[31, 7, 9] 这个Bucket 重分布就涉及到四个
- 与上面的
depth_相关:需要调整的dir 必定间隔1<<depth_,只需要找到最早的index 即可依次找到所有。
LRU-K替换策略
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
细节看:LRU-K和2Q缓存算法介绍
- 数据第一次被访问,加入到
访问历史列表; - 如果数据在
访问历史列表里后没有达到K次访问,则按照FIFO 淘汰; - 当
访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序; - 缓存数据队列中被再次访问后,重新排序;
- 需要淘汰数据时,淘汰缓存队列中排在末尾的数据(LRU),即:淘汰“倒数第K次访问离现在最久”的数据。
LRUKReplacer
size_t curr_size_{0}; // 可被驱逐 frame_id 个数 vec_evictable_ = true
size_t replacer_size_; // frame_id 的取值范围 = buffer pool page size
size_t k_;
std::mutex latch_;
std::vector<bool> vec_evictable_; // 哪些frame_id_t 可被驱逐
std::unordered_map<frame_id_t, size_t> hit_count_; // 每个frame_id_t 出现次数
// map 记录每个元素的访问次数和在队列中的位置(以在O(1) 时间完成移动删除等操作)
/* 历史访问队列 */
std::list<frame_id_t> hist_list_;
std::unordered_map<frame_id_t, std::list<int>::iterator> hist_map_;
/* 缓存队列 */
std::list<frame_id_t> cache_list_;
std::unordered_map<frame_id_t, std::list<int>::iterator> cache_map_;
按上面的逻辑 + 数据结构,实现功能不是很困难。
这里有点困惑的是 replacer_size_: frame_id 的取值范围。如上所述,buffer pool 就是page 数组,frame_id 就是数组下标。当buffer pool 大小设定后,frame_id 最大值就确定了,而replacer_size_ = page 数组长度。
当时做的时候还有个疑惑:frame_id 就是buffer pool index,而LRU 比较的frame_id,理论是不会发生置换(all(frame_id)=pages size)。其实这里把frame_id 换成 page_id 会清晰很多(虽然看到都是frame_id,但不同时期同个frame_id 存放的是不同page_id)。之所以用frame_id 而不是page_id,可能基于以下考虑:
- frame_id 可以直接用于 page数组,如果是page_id,还需要在page_tables 中用page_id 获取frame_id 才行
- 在置换时需要判断frame 是否
is_dirty_,这必须要访问frame(page 数组里的某个元素)
Buffer Pool
可扩展Hash 表 + LRU-K替换策略,Buffer 的功能就可实现。但这里有两个与寻常的buffer 不一样的地方
- LRU-K 中的
Evictable,驱逐时不止根据访问频次,还要判断Evictable=> 该page 是否还有在使用 - 驱逐的page 若有修改(内存page 与磁盘page 内容不一致),需要将page 刷写到磁盘

Page
/** The actual data that is stored within a page. */
char data_[BUSTUB_PAGE_SIZE]{};
/** The ID of this page. */
page_id_t page_id_ = INVALID_PAGE_ID;
/** The pin count of this page. */
int pin_count_ = 0;
/** True if the page is dirty, i.e. it is different from its corresponding page on disk. */
bool is_dirty_ = false;
pin_count:当前page 被使用个数,- +1 操作与
replacer_->RecordAccess、replacer_->SetEvictable(false)成对出现,保护page 不会被置换出去 - pin_count=0,表示已经没有使用该page,允许被置换出去,
replacer_->SetEvictable(true)
- +1 操作与
is_dirty_:内存page 与磁盘page 内容不一致- 当page 被置换/删除时,如果为true,需要先将该页 写出到磁盘
BufferPoolManagerInstance
Page *pages_; // buffer pool (frame)空间,page 数组,存储db page 数据
/** Page table for keeping track of buffer pool pages. */
ExtendibleHashTable<page_id_t, frame_id_t> *page_table_;
/** Replacer to find unpinned pages for replacement. */
LRUKReplacer *replacer_;
/** List of free frames that don't have any pages on them. */
std::list<frame_id_t> free_list_; // 记录pages_ 数组中,哪些page(frame) 是空闲的 => LRUKReplacer 驱逐
Function:
- NewPg:新建一个DB page,需要一个空闲frame
- 从free_list_/replacer_ 驱逐得到 frame,新建一个page
- 初始化 frame(page) 状态,并更新page_table_、replacer_(<page_i, frame_id> 映射)
- FetchPg:磁盘上某个page 加载到内存
- 从free_list_/replacer_ 驱逐得到 frame
- 初始化 frame(page) 状态 => 磁盘数据写入frame,并更新page_table_、replacer_(<page_i, frame_id> 映射)
- UnpinPg:pin_count_–,若pin_count_ 减到0,replacer_ 设置对应的 frame_id 为可驱逐
- FlushPg:单纯将page 刷写到磁盘
- FlushAllPgs:遍历pages_ 将
dirty的page 刷写出磁盘 - DeletePg:若是dirty page 先刷写磁盘,再删除对应的page_table_、replacer_、free_list_ 以及frame 状态