TaskScheduler
在 DuckDB 启动时会创建一个全局的 TaskScheduler,在后台启动(CPU内核数-1) 个后台线程,启动线程是在 TaskScheduler::SetThreadsInternal() 函数中进行
(gdb) bt #0 duckdb::TaskScheduler::SetThreadsInternal (this=0x2cfead80, n=5) at /root/duckdb/src/parallel/task_scheduler.cpp:267 #1 0x0000000002930620 in duckdb::TaskScheduler::SetThreads (this=0x2cfead80, n=5) at /root/duckdb/src/parallel/task_scheduler.cpp:245 #2 0x000000000286b4b4 in duckdb::DatabaseInstance::Initialize (this=0x2cfe8368, database_path=0x0, user_config=0xffffdd8ef698) at /root/duckdb/src/main/database.cpp:248 #3 0x000000000286b598 in duckdb::DuckDB::DuckDB (this=0x2cfe8330, path=0x0, new_config=0xffffdd8ef698) at /root/duckdb/src/main/database.cpp:252 #4 0x000000000236b67c in duckdb::make_uniq<duckdb::DuckDB, char const&, duckdb::DBConfig>(char const&, duckdb::DBConfig&&) () at /root/duckdb/src/include/duckdb/common/helper.hpp:63 #5 0x0000000002363b40 in duckdb_shell_sqlite3_open_v2 (filename=0x0, ppDb=0xffffdd8efb48, flags=6, zVfs=0x0) at /root/duckdb/tools/sqlite3_api_wrapper/sqlite3_api_wrapper.cpp:118 #6 0x0000000002349004 in open_db (p=0xffffdd8efb48, openFlags=0) at /root/duckdb/tools/shell/shell.c:14241 #7 0x000000000235702c in runOneSqlLine (p=0xffffdd8efb48, zSql=0x2cfe6fb0 “SELECT * FROM read_csv_auto(‘/root/duckdb/data/csv/dirty_line.csv’);”, in=0x0, startline=1) at /root/duckdb/tools/shell/shell.c:19890 #8 0x0000000002357698 in process_input (p=0xffffdd8efb48) at /root/duckdb/tools/shell/shell.c:20015 #9 0x00000000023593b8 in main (argc=1, argv=0xffffdd8f0f18) at /root/duckdb/tools/shell/shell.c:20828
// src/parallel/task_scheduler.cpp
DatabaseInstance &db;
//! The task queue
unique_ptr<ConcurrentQueue> queue;
//! Lock for modifying the thread count
mutex thread_lock;
//! The active background threads of the task scheduler
vector<unique_ptr<SchedulerThread>> threads;
//! Markers used by the various threads, if the markers are set to "false" the thread execution is stopped
vector<unique_ptr<atomic<bool>>> markers;
TaskScheduler 数据结构
DatabaseInstancedb实例queue:任务队列thread_lock:锁,修改threads 时使用threads:后台线程数组markers:标记,每个后台线程是否需要继续运行
// src/parallel/task_scheduler.cpp
void TaskScheduler::SetThreadsInternal(int32_t n) {
#ifndef DUCKDB_NO_THREADS
if (threads.size() == idx_t(n - 1)) {
return;
}
idx_t new_thread_count = n - 1;
if (threads.size() > new_thread_count) {
// we are reducing the number of threads: clear all threads first
for (idx_t i = 0; i < threads.size(); i++) {
*markers[i] = false;
}
// 唤醒阻塞的后台线程,这样才能使后台线程退出
// => 后台线程会阻塞在从队列中取数据
Signal(threads.size());
// now join the threads to ensure they are fully stopped before erasing them
for (idx_t i = 0; i < threads.size(); i++) {
threads[i]->internal_thread->join();
}
// erase the threads/markers 缩小后台线程数时,先让所有线程都退出
threads.clear();
markers.clear();
}
if (threads.size() < new_thread_count) {
// we are increasing the number of threads: launch them and run tasks on them
idx_t create_new_threads = new_thread_count - threads.size();
for (idx_t i = 0; i < create_new_threads; i++) {
// launch a thread and assign it a cancellation marker
auto marker = unique_ptr<atomic<bool>>(new atomic<bool>(true));
// 创建一个thread 后,会立即开始执行,此时已经执行
auto worker_thread = make_uniq<thread>(ThreadExecuteTasks, this, marker.get());
auto thread_wrapper = make_uniq<SchedulerThread>(std::move(worker_thread));
threads.push_back(std::move(thread_wrapper));
markers.push_back(std::move(marker));
}
}
#endif
}
每个后台线程都是取执行ThreadExecuteTasks,并且有atomic<bool> 标记该线程是否应该继续执行。
ThreadExecuteTasks
// src/parallel/task_scheduler.cpp
static void ThreadExecuteTasks(TaskScheduler *scheduler, atomic<bool> *marker) {
scheduler->ExecuteForever(marker);
}
void TaskScheduler::ExecuteForever(atomic<bool> *marker) {
#ifndef DUCKDB_NO_THREADS
shared_ptr<Task> task; // Task 最开始是 PipelineTask
// loop until the marker is set to false
while (*marker) {
// wait for a signal with a timeout
queue->semaphore.wait(); // 队列中没任务,阻塞
if (queue->q.try_dequeue(task)) { // 尝试取任务
auto execute_result = task->Execute(TaskExecutionMode::PROCESS_ALL);
switch (execute_result) {
case TaskExecutionResult::TASK_FINISHED:
case TaskExecutionResult::TASK_ERROR:
task.reset(); // 清理 task
break;
case TaskExecutionResult::TASK_NOT_FINISHED:
throw InternalException("Task should not return TASK_NOT_FINISHED in PROCESS_ALL mode");
case TaskExecutionResult::TASK_BLOCKED:
// 取消任务后,会将任务加入到 to_be_rescheduled_tasks map
// 若开启 DUCKDB_DEBUG_ASYNC_SINK_SOURCE,
// 在调用此代码前会调用interrupt_state.Callback 在to_be_rescheduled_tasks 搜任务并重新加入队列
task->Deschedule();
task.reset();
break;
}
}
}
从queue 获取任务Execute,只要(*marker) 不为false 就会一直执行。
queue
// src/parallel/task_scheduler.cpp
typedef duckdb_moodycamel::ConcurrentQueue<shared_ptr<Task>> concurrent_queue_t;
typedef duckdb_moodycamel::LightweightSemaphore lightweight_semaphore_t;
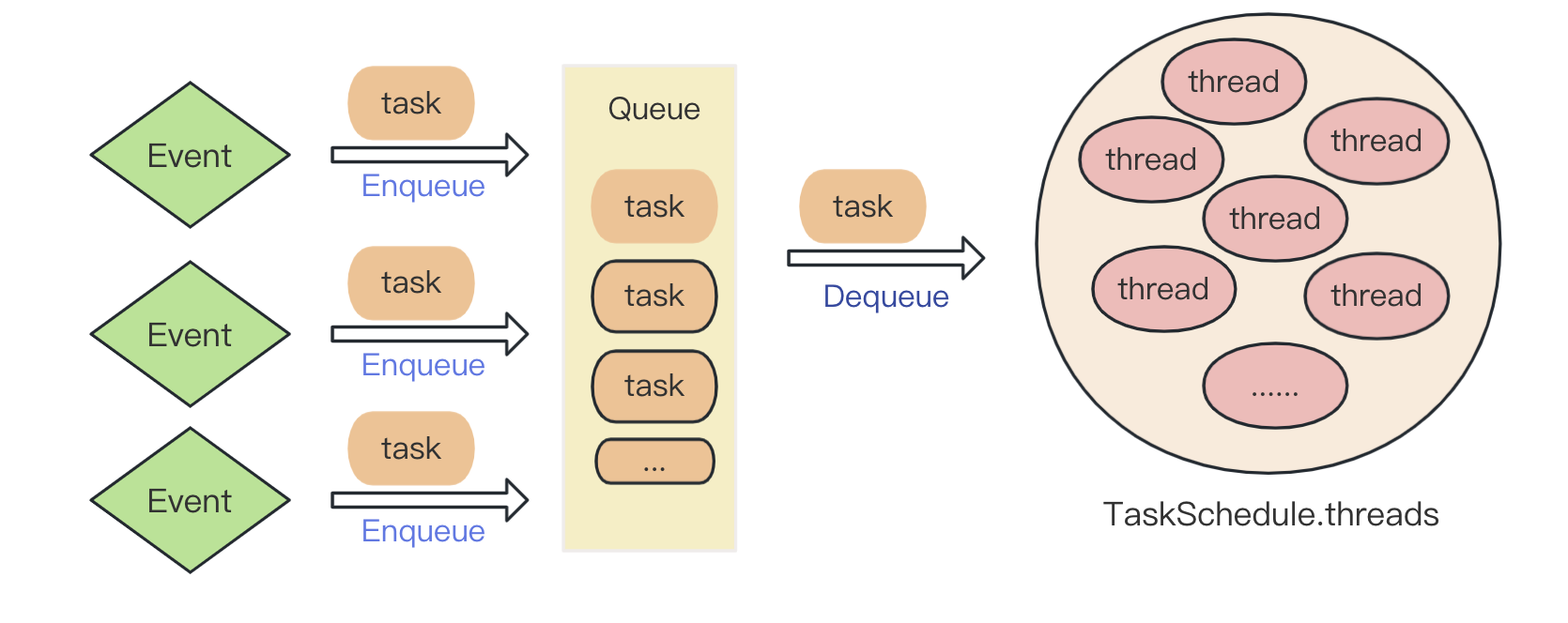
/**
* 线程都阻塞在 semaphore,
* 当有任务插入队列时,semaphore 会唤醒某个线程
* 唤醒的线程从队列取任务执行,然后继续阻塞在 semaphore
*/
struct ConcurrentQueue {
concurrent_queue_t q; // 支持并发的队列
lightweight_semaphore_t semaphore;
void Enqueue(ProducerToken &token, shared_ptr<Task> task); // 插入任务
bool DequeueFromProducer(ProducerToken &token, shared_ptr<Task> &task); //队列取某个生产者的任务
};
// 队列插入任务
void ConcurrentQueue::Enqueue(ProducerToken &token, shared_ptr<Task> task) {
lock_guard<mutex> producer_lock(token.producer_lock);
if (q.enqueue(token.token->queue_token, std::move(task))) {
semaphore.signal(); // 队列中有任务了,唤醒某个阻塞在取任务的线程
} else {
throw InternalException("Could not schedule task!");
}
}
bool ConcurrentQueue::DequeueFromProducer(ProducerToken &token, shared_ptr<Task> &task) {
lock_guard<mutex> producer_lock(token.producer_lock);
return q.try_dequeue_from_producer(token.token->queue_token, task);
}
ConcurrentQueue 资料 https://github.com/cameron314/concurrentqueue
这个queue 写法,项目中值得借鉴。
生成任务
// src/parallel/event.cpp
void Event::SetTasks(vector<shared_ptr<Task>> tasks) {
auto &ts = TaskScheduler::GetScheduler(executor.context);
D_ASSERT(total_tasks == 0);
D_ASSERT(!tasks.empty());
this->total_tasks = tasks.size();
for (auto &task : tasks) {
ts.ScheduleTask(executor.GetToken(), std::move(task));
}
}
// src/parallel/task_scheduler.cpp
void TaskScheduler::ScheduleTask(ProducerToken &token, shared_ptr<Task> task) {
// Enqueue a task for the given producer token and signal any sleeping threads
queue->Enqueue(token, std::move(task));
}
event 会产生task,并将task 插入queue,此时后台线程会被唤醒来取任务执行
总结
- TaskScheduler 开启(CPU内核数-1) 个后台线程,每个后台线程都是从
queue取任务执行 - 后台线程在取任务时,会先阻塞,当
queue插入任务时,会唤醒某个线程 eventschedule 函数生成task(最常见的是PipelineTask),插入到queue- 一个Pipeline 会生成并发数个任务
- Pipeline 并行在执行
- 只要进入
queue的任务是会并行的执行,很多后台线程抢着执行 => 任务是有依赖关系的,怎么解决?- 任务的依赖关系,是依赖于
event,每个Pipeline 会生成对应的event ,Pipeline 之间的依赖关系也会被附加到event之间(看上篇文章) - 当依赖关系的event 未执行结束,当前event 不会产生 task
- 任务的依赖关系,是依赖于
PipelineTask
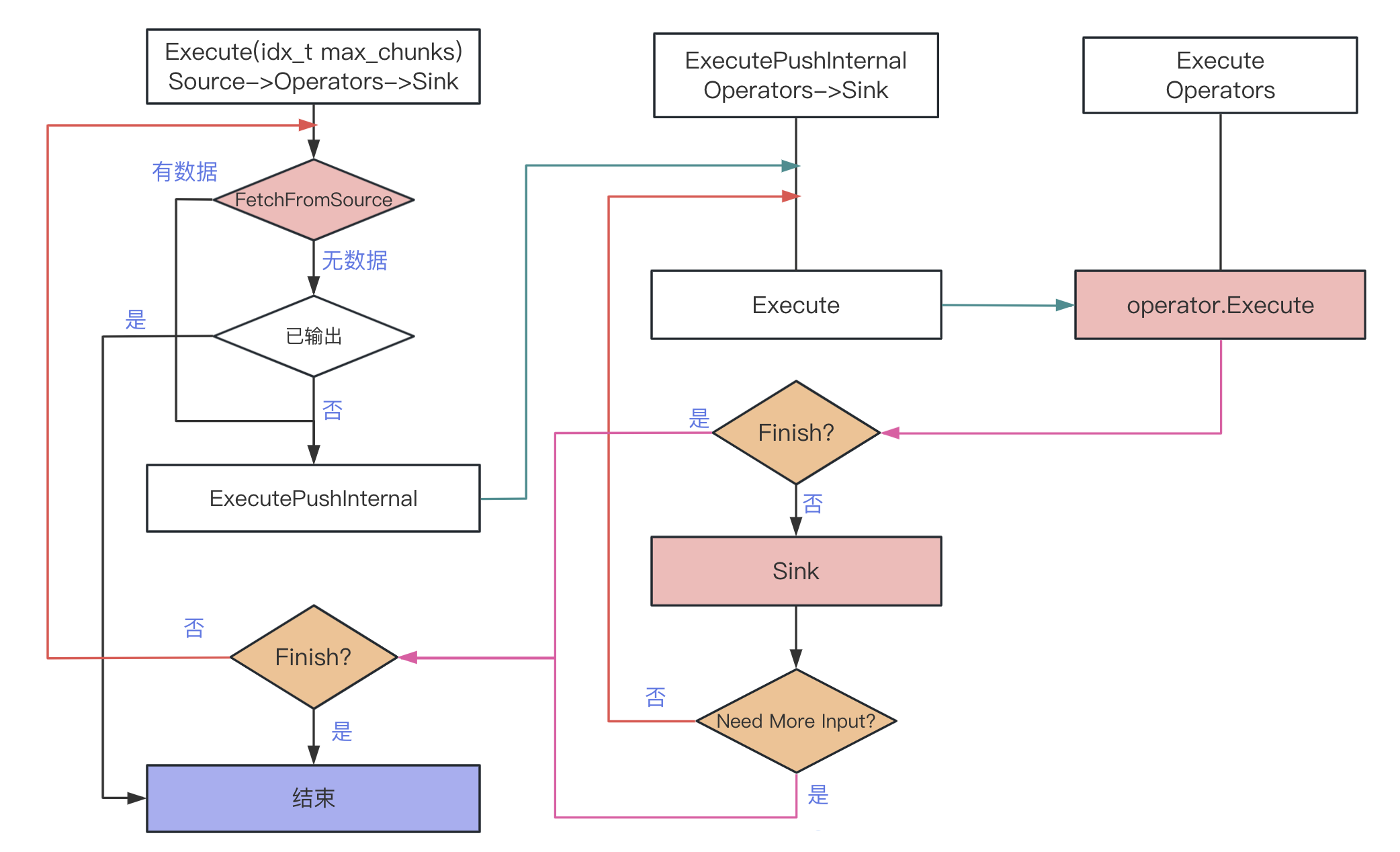
上一小节,描述 task 是如何被调度执行。下面看看task 内部是如何执行,以最常见的 PipelineTask 为例
在 TaskScheduler::ExecuteForever 执行 task->Execute
// PipelineTask.ExecuteTask
TaskExecutionResult ExecuteTask(TaskExecutionMode mode) override {
if (!pipeline_executor) {
pipeline_executor = make_uniq<PipelineExecutor>(pipeline.GetClientContext(), pipeline);
}
pipeline_executor->SetTaskForInterrupts(shared_from_this());
// mode = TaskExecutionMode::PROCESS_ALL
if (mode == TaskExecutionMode::PROCESS_PARTIAL) {
auto res = pipeline_executor->Execute(PARTIAL_CHUNK_COUNT);
switch (res) {
case PipelineExecuteResult::NOT_FINISHED:
return TaskExecutionResult::TASK_NOT_FINISHED;
case PipelineExecuteResult::INTERRUPTED:
return TaskExecutionResult::TASK_BLOCKED;
case PipelineExecuteResult::FINISHED:
break;
}
} else {
auto res = pipeline_executor->Execute();
switch (res) {
case PipelineExecuteResult::NOT_FINISHED:
throw InternalException("Execute without limit should not return NOT_FINISHED");
case PipelineExecuteResult::INTERRUPTED:
return TaskExecutionResult::TASK_BLOCKED;
case PipelineExecuteResult::FINISHED:
break;
}
}
// event 生成的task finish 个数判断
// 若task 都结束,标记此 event 完成
event->FinishTask();
pipeline_executor.reset();
return TaskExecutionResult::TASK_FINISHED;
}
};
当event 生成的所有任务都执行完成(并发数个任务),会执行 event 的 FinishTask ,详细内容看上篇
PipelineExecutor
// PipelineExecutor::Execute
//! Source has indicated it is exhausted
bool exhausted_source = false;
//! This flag is set when the pipeline gets interrupted by the Sink -> the final_chunk should be re-sink-ed.
bool remaining_sink_chunk = false;
//! Flushing of caching operators is done
bool done_flushing = false;
//! The operators that are not yet finished executing and have data remaining
//! If the stack of in_process_operators is empty, we fetch from the source instead
stack<idx_t> in_process_operators;
//! Flushing of intermediate operators has started
bool started_flushing = false;
PipelineExecuteResult PipelineExecutor::Execute() {
return Execute(NumericLimits<idx_t>::Maximum()); // uint64_t 最大值
}
PipelineExecuteResult PipelineExecutor::Execute(idx_t max_chunks) {
D_ASSERT(pipeline.sink);
auto &source_chunk = pipeline.operators.empty() ? final_chunk : *intermediate_chunks[0];
for (idx_t i = 0; i < max_chunks; i++) {
if (context.client.interrupted) {
throw InterruptException();
}
OperatorResultType result;
if (exhausted_source && done_flushing && !remaining_sink_chunk && in_process_operators.empty()) {
break;
} else if (remaining_sink_chunk) {
// The pipeline was interrupted by the Sink. We should retry sinking the final chunk.
result = ExecutePushInternal(final_chunk);
remaining_sink_chunk = false;
} else if (!in_process_operators.empty() && !started_flushing) {
// The pipeline was interrupted by the Sink when pushing a source chunk through the pipeline. We need to
// re-push the same source chunk through the pipeline because there are in_process operators, meaning that
// the result for the pipeline
D_ASSERT(source_chunk.size() > 0);
result = ExecutePushInternal(source_chunk);
} else if (exhausted_source && !done_flushing) {
// The source was exhausted, try flushing all operators
auto flush_completed = TryFlushCachingOperators();
if (flush_completed) {
done_flushing = true;
break;
} else {
return PipelineExecuteResult::INTERRUPTED;
}
} else if (!exhausted_source) {
// "Regular" path: fetch a chunk from the source and push it through the pipeline
source_chunk.Reset();
SourceResultType source_result = FetchFromSource(source_chunk);
if (source_result == SourceResultType::BLOCKED) {
return PipelineExecuteResult::INTERRUPTED;
}
if (source_result == SourceResultType::FINISHED) {
exhausted_source = true;
if (source_chunk.size() == 0) {
continue;
}
}
result = ExecutePushInternal(source_chunk);
} else {
throw InternalException("Unexpected state reached in pipeline executor");
}
// SINK INTERRUPT
if (result == OperatorResultType::BLOCKED) {
remaining_sink_chunk = true;
// 返回 INTERRUPTED,上层PipelineTask 会TASK_BLOCKED,
// 继而TaskScheduler 取消此任务调度
// 只会发生在source/sink 异步的情况,这是个新特性,当前版本还在测试
return PipelineExecuteResult::INTERRUPTED;
}
if (result == OperatorResultType::FINISHED) {
break;
}
}
if ((!exhausted_source || !done_flushing) && !IsFinished()) {
// 大部分情况下,不应该执行到这里,只能是Finish 返回
// NOT_FINISHED 返回是异常情况 PipelineTask 会抛异常
return PipelineExecuteResult::NOT_FINISHED;
}
PushFinalize();
return PipelineExecuteResult::FINISHED;
}
一个Pipeline Operators 完整操作(除了Sink->Finalize)
- 初始状态
exhausted_source = false和in_process_operators.isEmpty- source 有数据,
FetchFromSource获取数据- ->
pipeline.source->GetData - 若source 返回
FINISHED表示source 数据已全部获取,设置exhausted_source=true - 调用
ExecutePushInternal执行Operators
- ->
ExecutePushInternal:operators->sink执行- 返回三种状态
NEED_MORE_INPUT: 上层循环继续,看情况输入不同的data 调此函数FINISHED:上层结束循环,该pipeline 结束BLOCKED:上层直接退出循环,进入异常处理
Execute:operators执行- 返回三种状态
NEED_MORE_INPUT:上层返回NEED_MORE_INPUT(表示当前批次数据已处理完)FINISHED:上层返回FINISHEDHAVE_MORE_OUTPUT:上层用当前批次数据继续调用此函数,让operator 产生新的输出
- 返回三种状态
- 返回三种状态
- source 有数据,
- 当
exhausted_source=true,done_flushing=false时- 什么时候会发生这种情况?
FetchFromSource一次调用将全部数据获取完毕 - 调用
TryFlushCachingOperators,内部也会调ExecutePushInternal,执行 Operators - 一次数据处理流程:source->operatos->sink,反复调用直到 source 无数据;
- 当一次性就能获取全部source 时,执行operatos->sink 即可无需再重复获取Source
- 什么时候会发生这种情况?
- 当
in_process_operators不为空时,表示有 operator 需要之前的数据重新再调用(HAVE_MORE_OUTPUT) - ExecutePushInternal(source_chunk)
FetchFromSource
SourceResultType PipelineExecutor::FetchFromSource(DataChunk &result) {
...
auto res = GetData(result, source_input);
...
}
SourceResultType PipelineExecutor::GetData(DataChunk &chunk, OperatorSourceInput &input) {
return pipeline.source->GetData(context, chunk, input);
}
逻辑很清晰,调用 Source->GetData
ExecutePushInternal
OperatorResultType PipelineExecutor::ExecutePushInternal(DataChunk &input, idx_t initial_idx) {
D_ASSERT(pipeline.sink);
if (input.size() == 0) { // LCOV_EXCL_START
return OperatorResultType::NEED_MORE_INPUT;
} // LCOV_EXCL_STOP
// this loop will continuously push the input chunk through the pipeline as long as:
// - the OperatorResultType for the Execute is HAVE_MORE_OUTPUT
// - the Sink doesn't block
while (true) {
OperatorResultType result;
// Note: if input is the final_chunk, we don't do any executing, the chunk just needs to be sinked
if (&input != &final_chunk) {
final_chunk.Reset();
// 执行 operators.execute
result = Execute(input, final_chunk, initial_idx);
if (result == OperatorResultType::FINISHED) {
return OperatorResultType::FINISHED;
}
} else {
result = OperatorResultType::NEED_MORE_INPUT;
}
auto &sink_chunk = final_chunk;
if (sink_chunk.size() > 0) { // 说明operator 都已执行,轮到sink->sink 执行了
StartOperator(*pipeline.sink);
D_ASSERT(pipeline.sink);
D_ASSERT(pipeline.sink->sink_state);
OperatorSinkInput sink_input {*pipeline.sink->sink_state, *local_sink_state, interrupt_state};
// operator.Sink
auto sink_result = Sink(sink_chunk, sink_input);
EndOperator(*pipeline.sink, nullptr);
if (sink_result == SinkResultType::BLOCKED) {
return OperatorResultType::BLOCKED;
} else if (sink_result == SinkResultType::FINISHED) {
// 直接结束整个Pipeline 任务
FinishProcessing();
return OperatorResultType::FINISHED;
}
}
if (result == OperatorResultType::NEED_MORE_INPUT) {
return OperatorResultType::NEED_MORE_INPUT;
}
}
}
执行 operators->sink 流程
- Execute 执行operators.execute,
- 返回状态
NEED_MORE_INPUT:表示当前批次数据已处理完毕,sink 处理后返回上层,等待新批次数据调用FINISHED:operator结束,直接返回FINISHED,整个pipeline 任务结束HAVE_MORE_OUTPUT:用当前input 继续调用Execute
- 返回状态
- 只要不是
FINISHED,Operator返回的data 都会让Sink->sink处理 - sink 函数只要不返回 FINISHED,继续循环
- Operator 不返回NEED_MORE_INPUT、FINISHED,继续循环
- 表示当前批次的数据,Operators 还要再处理(
HAVE_MORE_OUTPUT)
Execute
OperatorResultType PipelineExecutor::Execute(DataChunk &input, DataChunk &result, idx_t initial_idx) {
if (input.size() == 0) { // LCOV_EXCL_START
return OperatorResultType::NEED_MORE_INPUT;
} // LCOV_EXCL_STOP
D_ASSERT(!pipeline.operators.empty());
idx_t current_idx;
GoToSource(current_idx, initial_idx);
if (current_idx == initial_idx) {
current_idx++;
}
// 全部 operators 都已执行
if (current_idx > pipeline.operators.size()) {
result.Reference(input);
return OperatorResultType::NEED_MORE_INPUT;
}
while (true) {
if (context.client.interrupted) {
throw InterruptException();
}
// now figure out where to put the chunk
// if current_idx is the last possible index (>= operators.size()) we write to the result
// otherwise we write to an intermediate chunk
// 每个operator 都属于自己的输出 DataChunk,
// 最后一个operator 的输出 DataChunk 是result
auto current_intermediate = current_idx;
auto ¤t_chunk =
current_intermediate >= intermediate_chunks.size() ? result : *intermediate_chunks[current_intermediate];
current_chunk.Reset();
if (current_idx == initial_idx) {
// we went back to the source: we need more input
return OperatorResultType::NEED_MORE_INPUT;
} else {
auto &prev_chunk =
current_intermediate == initial_idx + 1 ? input : *intermediate_chunks[current_intermediate - 1];
auto operator_idx = current_idx - 1;
auto ¤t_operator = pipeline.operators[operator_idx].get();
// if current_idx > source_idx, we pass the previous operators' output through the Execute of the current
// operator
StartOperator(current_operator);
auto result = current_operator.Execute(context, prev_chunk, current_chunk, *current_operator.op_state,
*intermediate_states[current_intermediate - 1]);
EndOperator(current_operator, ¤t_chunk);
if (result == OperatorResultType::HAVE_MORE_OUTPUT) {
// more data remains in this operator
// push in-process marker
// 保存哪些 operator 正在处理当前批次数据,上层不需要再获取新数据,
// 将当前批次数据重新调用
in_process_operators.push(current_idx);
} else if (result == OperatorResultType::FINISHED) {
D_ASSERT(current_chunk.size() == 0);
// 直接结束整个Pipeline 任务
FinishProcessing(current_idx);
return OperatorResultType::FINISHED;
}
current_chunk.Verify();
}
if (current_chunk.size() == 0) {
// no output from this operator!
// 无数据返回,若是执行的第一个operator,直接退出
// 若不是执行的第一个operator,重置下一个执行operator 为初始(重新获取数据)
// 类似于 filter 操作将数据全部过滤了,那么后续操作没必要执行
if (current_idx == initial_idx) {
// if we got no output from the scan, we are done
break;
} else {
// if we got no output from an intermediate op
// we go back and try to pull data from the source again
GoToSource(current_idx, initial_idx);
continue;
}
} else {
// we got output! continue to the next operator
current_idx++;
if (current_idx > pipeline.operators.size()) {
// if we got output and are at the last operator, we are finished executing for this output chunk
// return the data and push it into the chunk
break;
}
}
}
return in_process_operators.empty() ? OperatorResultType::NEED_MORE_INPUT : OperatorResultType::HAVE_MORE_OUTPUT;
}
按顺序执行 Operator
GoToSource: 校准从哪个opeartor 开始执行(默认是 initial_idx)- 如果存在
in_process_operators,直接从in_process_operators开始, - 因为当前输入的数据,在in_process_operators 之前的operator 上次已执行,没必要重新执行
- 如果存在
- 判断
Operators是否都已执行,返回NEED_MORE_INPUT - while:遍历执行
OperatorOperator返回HAVE_MORE_OUTPUT:in_process_operators,Operator返回无数据,重置下一个执行Operator为初始(重新获取数据)- 执行的
Operator序号++
- 返回三种状态
NEED_MORE_INPUT:上层继续往上NEED_MORE_INPUT(表示当前批次数据已处理完)FINISHED:上层继续往上FINISHED,此Pipeline 结束HAVE_MORE_OUTPUT:上层继续循环调用此函数(数据相同),让Operator 产生新的输出
in_process_operators 要注意,这里会穿透好几个函数
PushFinalize
void PipelineExecutor::PushFinalize() {
...
pipeline.sink->Combine(context, *pipeline.sink->sink_state, *local_sink_state);
...
}
调用 sink->Combine,到此为止,一般的Pipeline 任务只剩下 sink->Finalize 没执行。
总结
数据处理完成流程:Source -> Operator -> Sink
Execute:从source获取数据Inputdata,给ExecutePushInternal消费- 收到 ExecutePushInternal 返回
NEED_MORE_INPUT:- 若
source数据都已获取且已输出:退出,当前Pipeline执行完毕 - 若
source数据都已获取但存在in_process_operators:当前Inputdata给ExecutePushInternal - 若
source还有数据,继续 getdata,给ExecutePushInternal
- 若
- 收到
ExecutePushInternal返回FINISHED:退出,当前Pipeline 执行结束 ExecutePushInternal:将Inputdata给Operator消费,结果继续给Sink消费- 收到 Execute 返回
NEED_MORE_INPUT:等sink 消费后,向上层返回NEED_MORE_INPUT,需要继续输入新的 Inputdata - 收到 Execute 返回
FINISHED:返回FINISHED 表示直接结束 - 收到 Execute 返回
HAVE_MORE_OUTPUT:表示Execute 要再消费一次当前 Inputdata,继续Execute(Inputdata) - Execute(DataChunk):将 Inputdata 按顺序给Operator 处理
- 返回
NEED_MORE_INPUT表示当前Inputdata 所有Operator 都已处理完毕,请求继续输入新的 Inputdata - 返回
FINISHED:Operator 不再处理,提前结束 - 返回
HAVE_MORE_OUTPUT:当前Inputdata 再输入,需要重新处理产生新的输出
- 返回
- 收到 Execute 返回
- 收到 ExecutePushInternal 返回